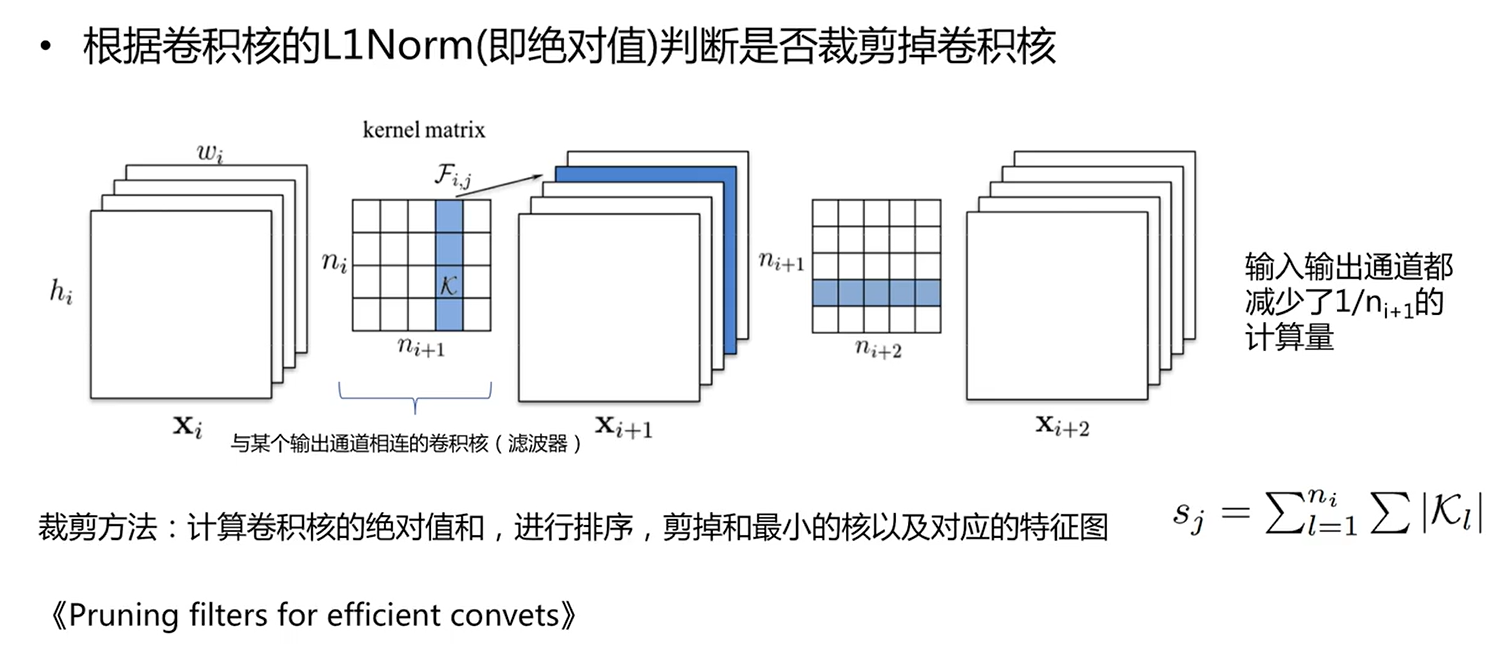
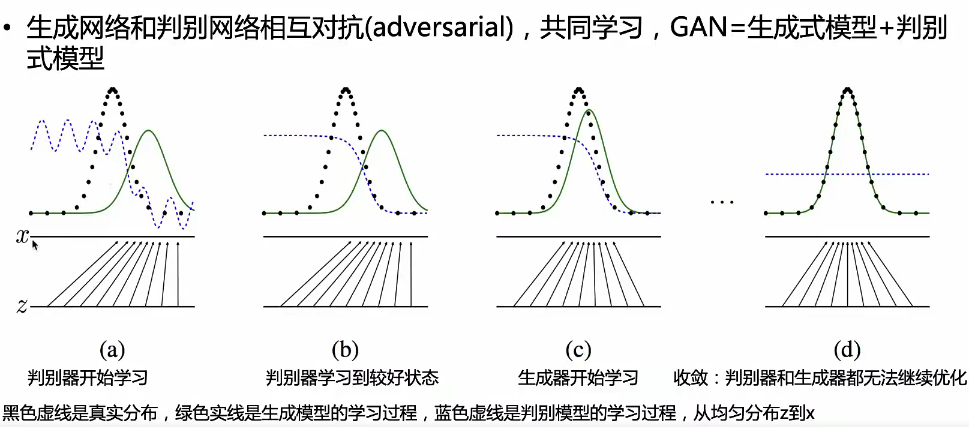
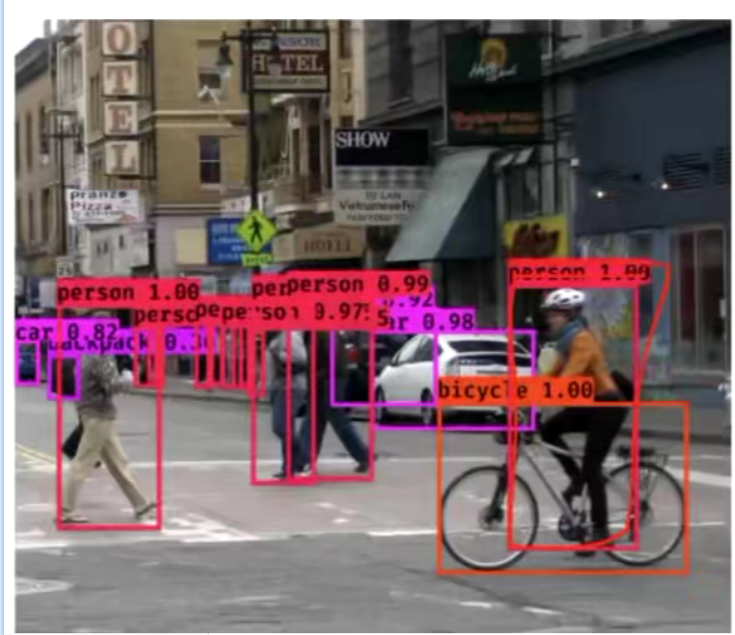
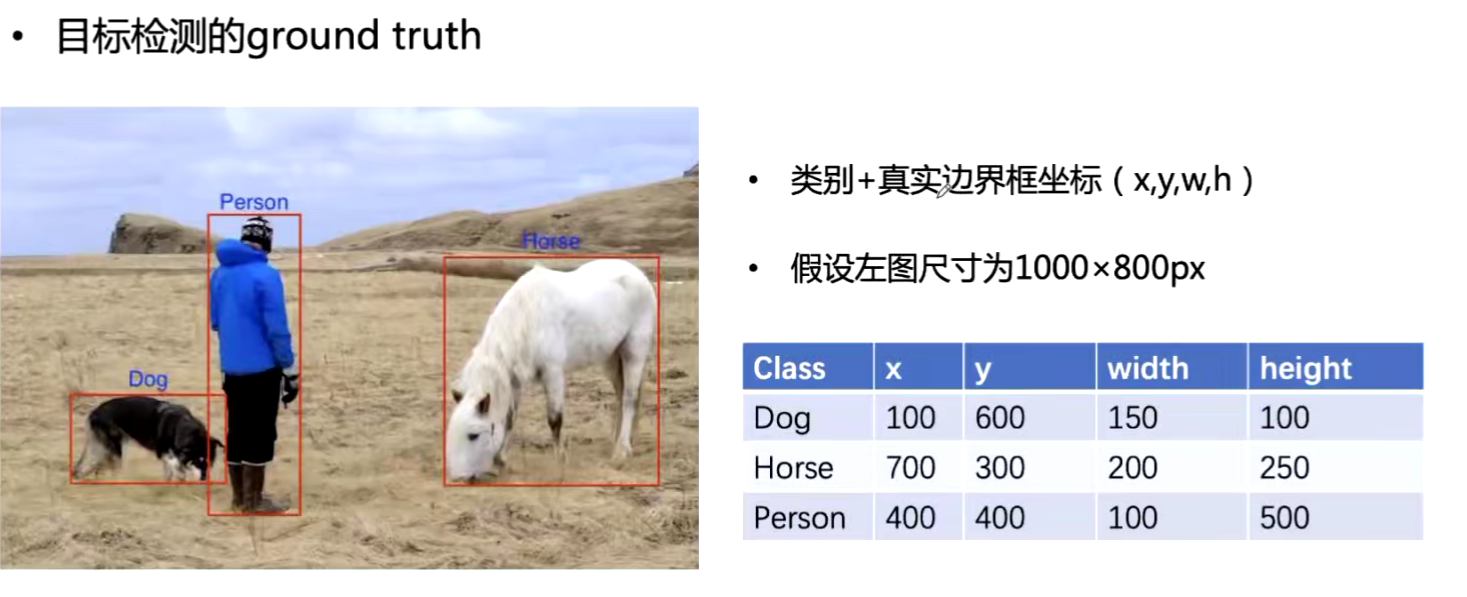
emplace_pack和push_back
emplace_pack和push_back
emplace_back 和 push_back
都是用于将元素添加到容器尾部的 C++ 函数,但它们有一些关键的区别,使得
emplace_back 在某些情况下比 push_back
更高效。
- 构造对象的方式:
push_back接受一个已经构造好的对象,并将其拷贝(或移动)到容器中。emplace_back则允许你在容器内部就地构造对象,而不需要提前创建一个对象。它接受参数,并将这些参数传递给对象的构造函数。
- 性能优势:
- 当使用
push_back时,你需要先创建一个对象,然后将其拷贝(或移动)到容器中。这可能导致额外的构造和拷贝开销,特别是当操作涉及到复杂的对象。 emplace_back可以直接在容器内部构造对象,避免了额外的拷贝或移动操作,因此在性能上可能更高效。
- 当使用
- 可变参数:
emplace_back使用可变参数列表,允许传递给构造函数的参数。这使得它对于构造函数带有多个参数的情况更为灵活,而不需要显式创建一个临时对象。
在实际编程中,如果你只需要添加已经存在的对象到容器尾部,那么
push_back
是一个不错的选择。但如果你想要在容器中直接构造对象,并且构造函数带有多个参数,那么
emplace_back 可能更为合适和高效。