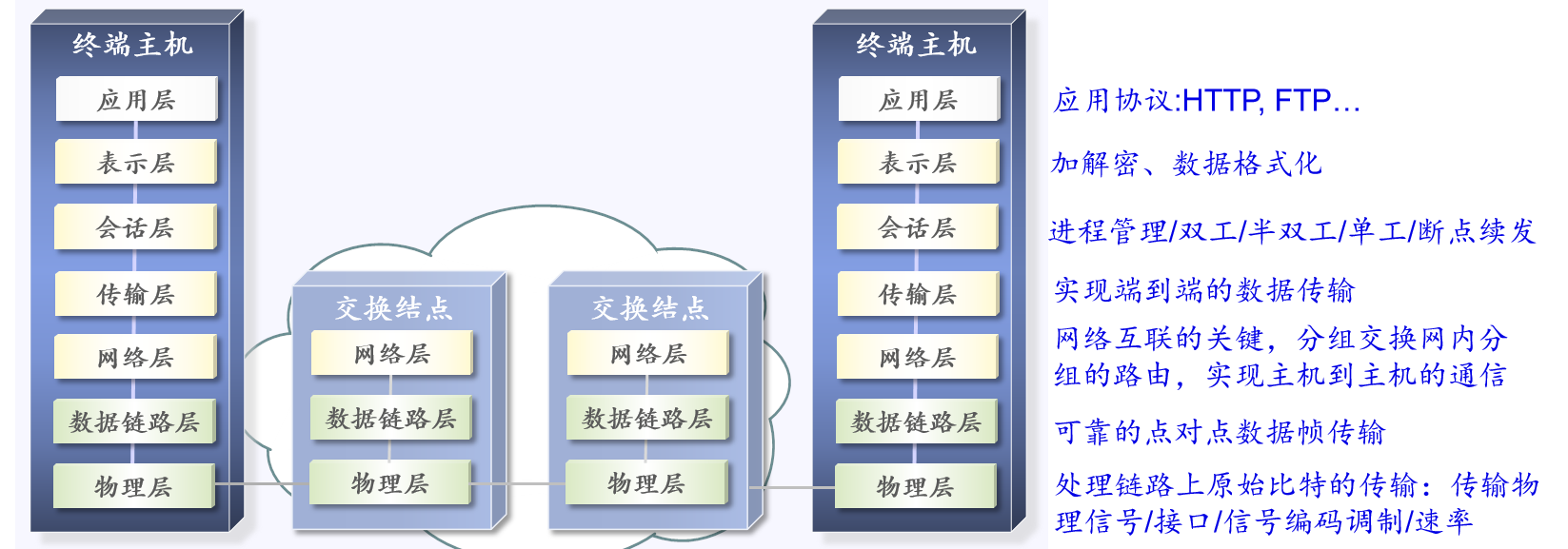
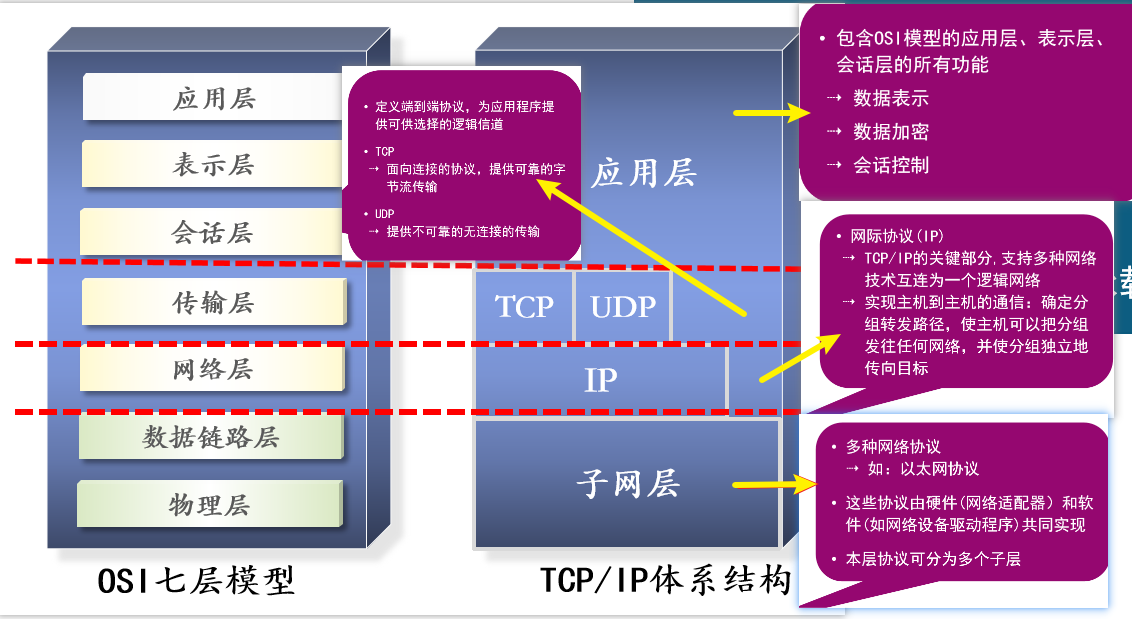
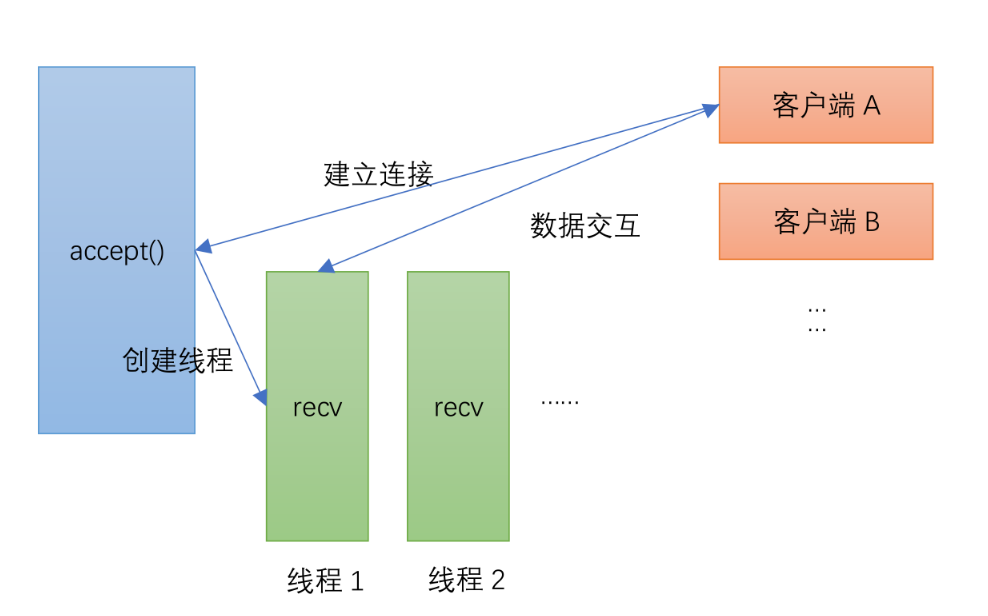
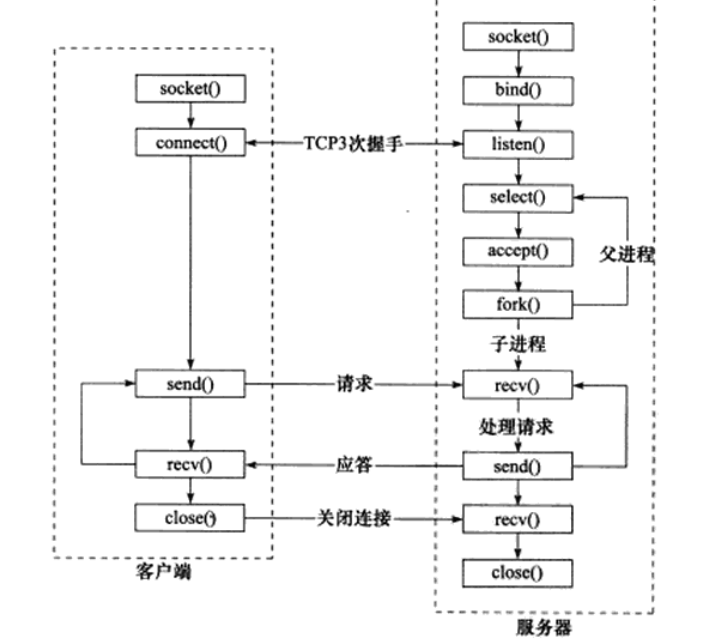
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| #include <errno.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <unistd.h>
#include <pthread.h>
#define MAXLNE 4096
#define POLL_SIZE 1024
void *client_routine(void *arg) {
int connfd = *(int *)arg;
char buff[MAXLNE];
while (1) {
int n = recv(connfd, buff, MAXLNE, 0);
if (n > 0) {
buff[n] = '\0';
printf("recv msg from client: %s\n", buff);
send(connfd, buff, n, 0);
} else if (n == 0) {
close(connfd);
break;
}
}
return NULL;
}
int main(int argc, char **argv)
{
int listenfd, connfd, n;
struct sockaddr_in servaddr;
char buff[MAXLNE];
if ((listenfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
printf("create socket error: %s(errno: %d)\n", strerror(errno), errno);
return 0;
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(10000);
if (bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr)) == -1) {
printf("bind socket error: %s(errno: %d)\n", strerror(errno), errno);
return 0;
}
if (listen(listenfd, 10) == -1) {
printf("listen socket error: %s(errno: %d)\n", strerror(errno), errno);
return 0;
}
while (1) {
struct sockaddr_in client;
socklen_t len = sizeof(client);
if ((connfd = accept(listenfd, (struct sockaddr *)&client, &len)) == -1) {
printf("accept socket error: %s(errno: %d)\n", strerror(errno), errno);
return 0;
}
pthread_t threadid;
pthread_create(&threadid, NULL, client_routine, (void*)&connfd);
}
return 0;
}
|