编译和链接
编译和链接
基本流程
当我们 Build 一个项目的时候,一般分为四个步骤:预处理,编译,汇编,链接

预编译:主要处理以#开头的预编译指令
编译:进行词法分析,语法分析和优化生成汇编代码文件
GCC将预编译和编译合成了一个步骤使用cc1程序完成,c++使用cc1plus完成
汇编:汇编指令转换为机器指令,gcc使用汇编器as完成
当我们 Build 一个项目的时候,一般分为四个步骤:预处理,编译,汇编,链接
预编译:主要处理以#开头的预编译指令
编译:进行词法分析,语法分析和优化生成汇编代码文件
GCC将预编译和编译合成了一个步骤使用cc1程序完成,c++使用cc1plus完成
汇编:汇编指令转换为机器指令,gcc使用汇编器as完成
用两个栈来实现一个队列,使用n个元素来完成 n 次在队列尾部插入整数(push)和n次在队列头部删除整数(pop)的功能。 队列中的元素为int类型。保证操作合法,即保证pop操作时队列内已有元素。
数据范围: n*≤1000
要求:存储n个元素的空间复杂度为 O(n) ,插入与删除的时间复杂度都是 O(1)
借助栈的先进后出规则模拟实现队列的先进先出
1、当插入时,直接插入 stack1
2、当弹出时,当 stack2 不为空,弹出 stack2 栈顶元素,如果 stack2 为空,将 stack1 中的全部数逐个出栈入栈 stack2,再弹出 stack2 栈顶元素
二叉搜索树的中序遍历是有序的。
充分利用中序遍历的有序性构造有序的双向链表。
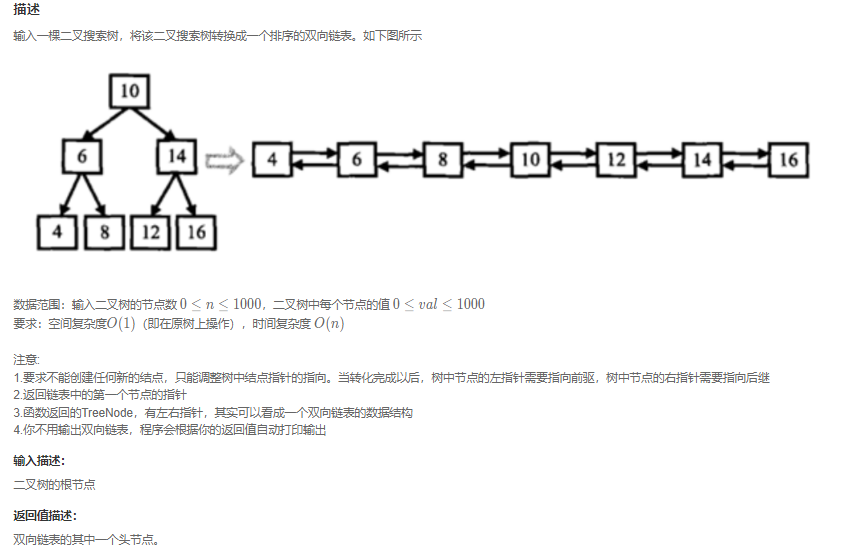
改造原始的中序遍历,避免构造额外的空间。核心的逻辑是:左中右中,中的前驱是左,后继是右子树。所以可以使用一共pre指针指向左节点,然后root的left指向pre,pre的right指向root。pre更新到root,pre设置为全局的变量。
1 | /* |
描述:
深度优先搜索属于图算法的一种,英文缩写为DFS即Depth First Search.
深度优先搜索一般用于树或者图的遍历,其他有分支的(如二维矩阵)也适用。它的原理是从初始点开始,一直沿着同一个分支遍历,直到该分支结束,然后回溯到上一级继续沿着一个分支走到底,如此往复,直到所有的节点都有被访问到。
深度优先遍历图的方法是,从图中某顶点v出发:
(1)访问顶点v; (2)依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问; (3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。

根节点开始向左右子树进行递归,由于要返回具体的路径,递归函数中需要处理的是:
分治算法(divide and conquer)的核心思想其实就是四个字,分而治之
,也就是将原问题划分成 k
个规模较小,并且结构与原问题相似的子问题,递归
地解决这些子问题,然后再合并其结果,就得到原问题的解。
关于分治和递归的区别:
比较经典的应用就是归并排序(Merge Sort)以及 快速排序(Quick Sort)。
分治所能解决的问题一般具有以下几个特征:
说明:
在多线程程序中,为了实现对共享变量的互斥访问,一般都会用spinlock实现,而spinlock需要一个TestAndSet的原子操作。而这种原子操作是需要专门的硬件支持才能完成的,在MIPS中,是通过特殊的Load,Store操作LL(Load Linked,链接加载)以及SC(Store Conditional,条件存储)完成的。
LL 指令的功能是从内存中读取一个字
SC 指令的功能是向内存中写入一个字
LL/SC 指令的独特之处在于,它们不是一个简单的内存读取/写入的函数,当使用 LL 指令从内存中读取一个字之后,比如 LL d, off(b),处理器会记住 LL 指令的这次操作(会在 CPU 的寄存器中设置一个不可见的 bit 位),同时 LL 指令读取的地址 off(b) 也会保存在处理器的寄存器中。接下来的 SC 指令,比如 SC t, off(b),会检查上次 LL 指令执行后的 RMW 操作是否是原子操作(即不存在其它对这个地址的操作),如果是原子操作,则 t 的值将会被更新至内存中,同时 t 的值也会变为1,表示操作成功;反之,如果 RMW 的操作不是原子操作(即存在其它对这个地址的访问冲突),则 t 的值不会被更新至内存中,且 t 的值也会变为0,表示操作失败。
SC 指令执行失败的原因有两种:
简单的应用例子:
用MIPS LL/SC指令实现从内存单元100(R2)取数,把取出来的数加100并存回到100(R2)中的原子操作代码
1 | 1: LL R3,100(R2) |
MIPS的意思是 “无内部互锁流水级的微处理器” (Microprocessor without interlocked piped stages)
加、减、乘、除、开方……
移位:左移与右移、逻辑移位与算术移位……
与、或、非、异或……
格式转换……
不同长度和不同类型:定点/浮点,字节/半字/字/双字