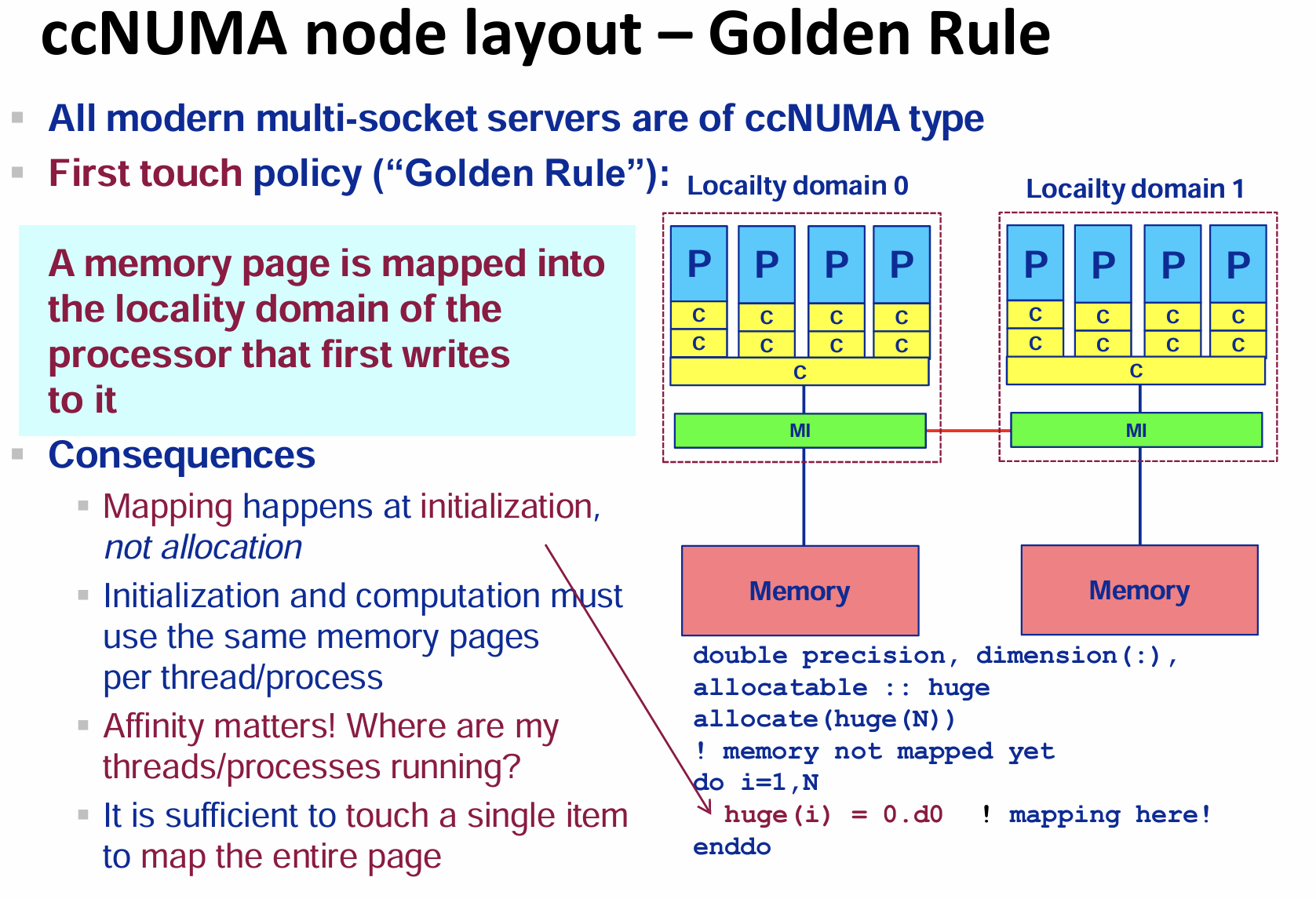
openmp
openmp
OpenMP: Syntax in C/C++
包含头文件:#include <omp.h>
编译制导
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。
测试小案例1:openmp的简单使用
1 |
|
编译:
1 | g++ hello.cpp -fopenmp -o hello |
OPENMP中设置线程数量的方法:
在环境变量中设置environment
variables。在命令窗口中配置 :export OMP_NUM_THREADS =
3
其他常见的环境变量:
▪ Loop scheduling: OMP_SCHEDULE, Stacksize: OMP_STACKSIZE
▪ Dynamic adjustment of threads: OMP_DYNAMIC
运行以后有这样的效果:
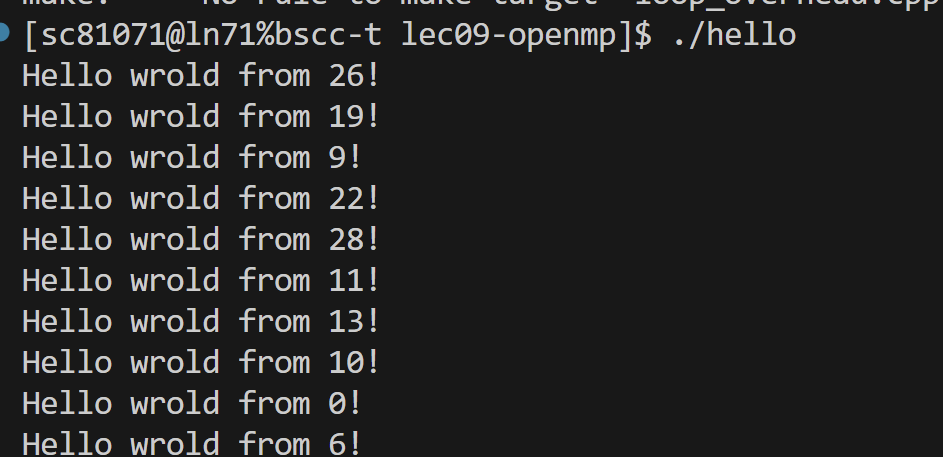
测试小案例2:私有变量和共享变量
1 | int main(int argc, char* argv[]) { |
privatized variables defined in scope outside the parallel region
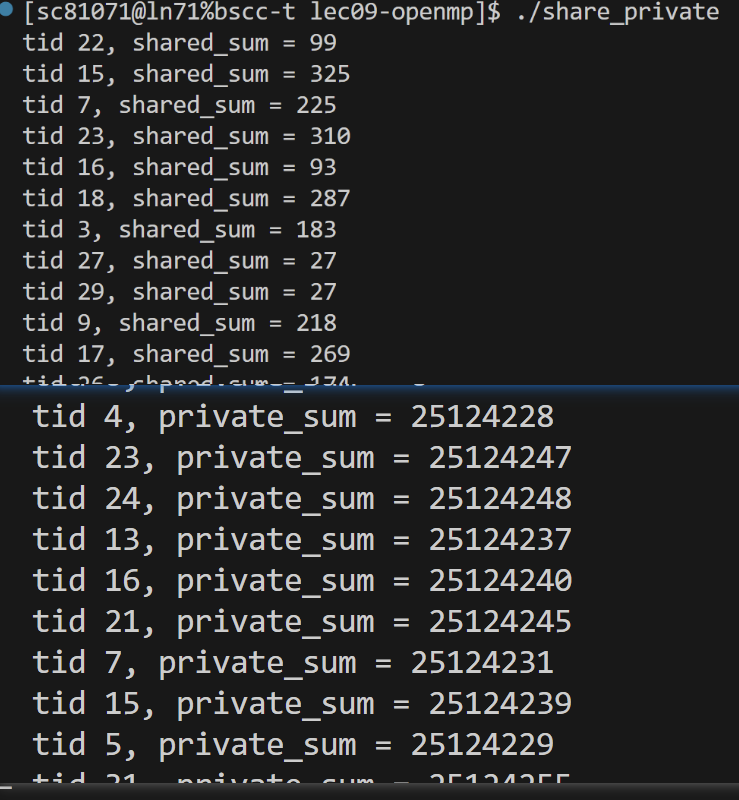
调度的策略
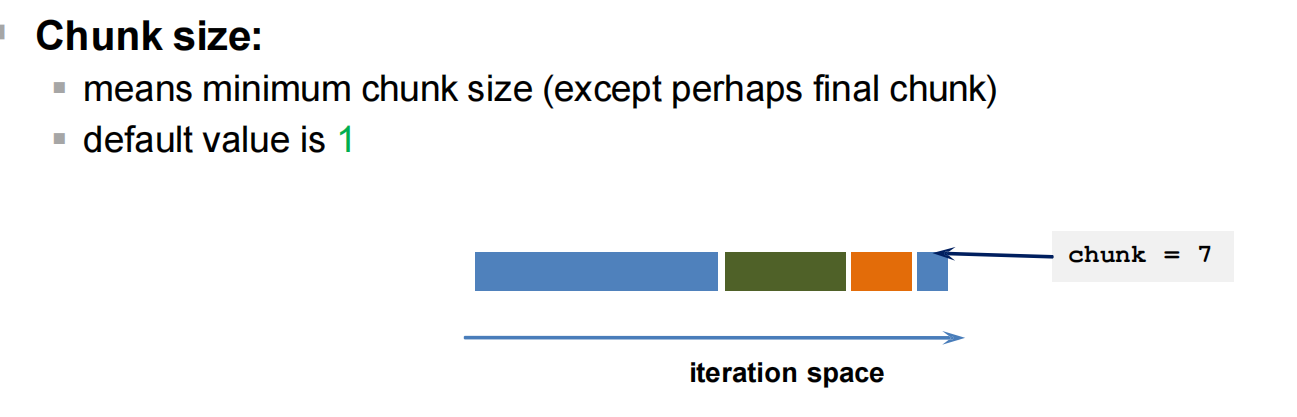
默认的静态调度策略是将程序整段均分,分块后分给不同的线程。
动态调度

例如:
#pragma omp for schedule(static, 1)
#pragma omp for: 这条指令告诉编译器,后面的 for 循环应该被并行化。编译器会生成多线程代码来执行循环的各个迭代。schedule(static, 1): 这是一个调度策略,定义了如何将循环迭代分配给不同的线程。static: 静态调度策略。表示在程序执行前(即编译时)确定每个线程将处理的迭代次数。每个线程处理的迭代是连续的块。1: 表示块大小,即每个线程一次处理一个迭代。这意味着循环的每个迭代(即每次循环)都被分配给不同的线程。
综上所述,#pragma omp for schedule(static, 1)
的意思是:
- 将 for 循环并行化。
- 使用静态调度策略。
- 每个线程处理一个迭代。
1 |
|
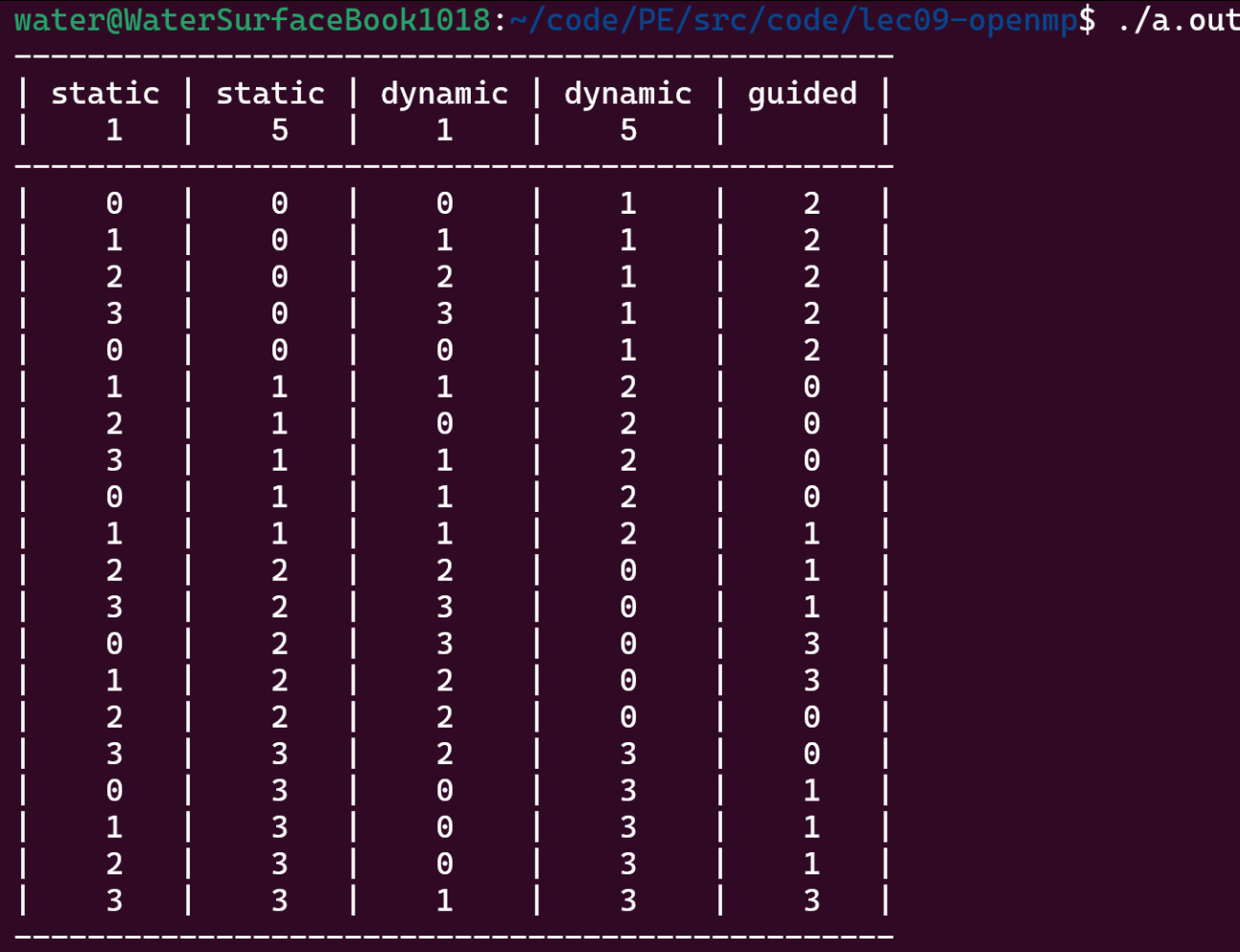
可以看得出,静态调度的时候都是按顺序把块分配给相应的进程的
#pragma omp for schedule(guided) 的含义是:
将
for循环并行化。使用指引调度策略。一开始的块很大,后面的块依次减小分给不同的线程。
Deferred Scheduling(延迟调度)
- 自动调度(Auto Scheduling)
定义:程序员允许实现使用任何可能的映射方案。
- 由运行时决定
runtime:调度可以是上述调度类型之一(例如static或dynamic),具体由环境变量OMP_SCHEDULE设置,或者通过调用omp_set_schedule()覆盖环境设置。- 可以通过调用
omp_get_schedule()查找当前的活动调度。
例子:
环境设置:
1
2
3export OMP_SCHEDULE="guided,4"
./a.outAPI调用:
1
2
3
call omp_set_schedule(omp_sched_dynamic,4)
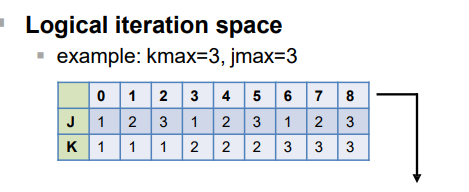
Collapsing Loop Nests(嵌套循环合并)
将多个嵌套的循环合并成一个单一的迭代空间进行并行处理。
限制条件
- 迭代空间在进入循环时可计算:必须是矩形的迭代空间。
1 |
|
collapse(n):参数n指定要合并的循环层次数量。
kmax=3, jmax=3时,合并后的逻辑迭代空间如下:
优化效果
可能改善内存局部性。
可能减少核心之间的数据流量。
嵌套循环合并适用于需要优化内存访问模式并减少数据传输开销的场景。
嵌套循环合并是优化并行执行的有效方法,尤其在需要处理复杂的嵌套循环结构时,通过将其转换为单一的迭代空间,可以改善内存局部性并提高执行效率。
Performance Tuning: the nowait clause(性能调优:nowait子句)
nowait子句用于消除隐式同步,从而提高性能。通常情况下,OpenMP的循环和其他并行结构在结束时会有隐式的同步点,nowait子句可以避免这种同步。
使用场景
- 在并行区域内的多个循环中,如果不需要在每个循环结束时进行同步,可以使用
nowait子句来提高性能。 - 特别适用于负载不平衡的情况,如果某些线程完成的时间明显早于其他线程,可以通过消除不必要的等待来优化性能。
1 |
|
Explicit barrier synchronization(显式屏障同步)
屏障指令
- 屏障构造是一个独立的指令,用于同步所有线程的执行流。
- 当每个线程到达屏障时,它们会阻塞,直到所有线程都到达屏障。
隐式屏障
- 在某些指令中存在隐式屏障:
- 并行区域的开始和结束处。
do、single、sections、workshare块的结束处(除非指定了nowait子句)。- 执行团队中的所有线程都会在这些指令处同步。
- 这些隐式屏障使这些指令“易用且安全”。
并行段是一个非迭代的工作共享构造,用于将一组结构化的代码块分配给线程团队中的不同线程执行。
1 |
|
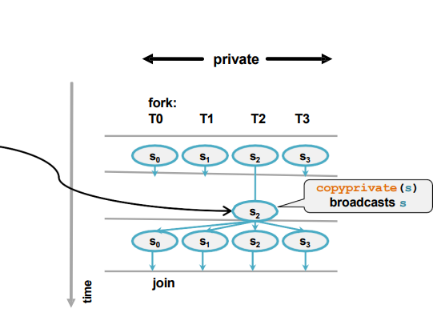
The Single Directive(单线程指令)
定义
single指令指定代码块只由一个线程执行,所有其他线程等待该代码块执行完成。- 常用于需要更新共享实体的操作。
允许的子句
private:指定变量在每个线程中是私有的。firstprivate:指定变量在每个线程中是私有的,并且从主线程复制初始值。copyprivate:在single指令结束时,将执行线程的变量值复制到所有其他线程。nowait:消除隐式同步,使其他线程无需等待single块的执行完成
使用场景
single指令用于需要在并行区域中由一个线程执行的代码块,例如更新共享数据、文件I/O操作等。
1 |
|
在OpenMP中,flush
是一种同步机制,用于确保在并行执行中对共享变量的更新在各个线程之间可见。它的语法如下:
1 |
其中,list
是一个可选的参数,用于指定需要刷新的共享变量列表。如果没有提供
list,则刷新所有共享变量。
flush 指令通常与 #pragma omp barrier
或者其他同步指令一起使用,以确保线程在访问共享数据时的正确同步。
在使用 flush
时要小心,过度使用可能会导致性能下降,因为它会导致线程间的通信和同步。
命名临界区(Named Critical)
在多线程编程中,当多个线程同时访问和修改共享资源时,可能会引发竞态条件和数据不一致性问题。
使用临界区(critical regions)可以确保一次只有一个线程执行临界区内的代码,从而避免竞态条件。
使用命名临界区(Named Critical),即通过给临界区命名,只对同名的临界区进行互斥操作。
这样做的好处是可以提高程序性能,因为只有同名的临界区会互斥,而不同名字的临界区不会互斥,从而减少了不必要的性能损失。
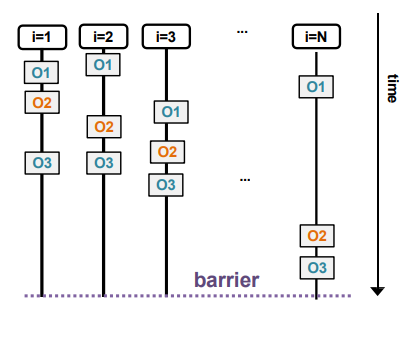
有序子句和指令(Ordered Clause and Directive)
在并行循环中,有时需要按照顺序执行某些操作。这种情况下,可以使用有序子句和指令。
有序指令类似于单一指令,但它是针对循环体内的某些操作,使这些操作按照顺序执行。
1 |
|
O1 是在所有线程中并行执行的操作。
O2
是在有序区域中按顺序执行的操作,即所有线程在此处按顺序执行,而不是并行。
O3 是在有序区域之外继续并行执行的操作。
使用锁实现互斥(Mutual Exclusion with Locks)
共享锁变量可以用来实现特定的同步机制。
在 C/C++ 中,锁变量的类型为 omp_lock_t。
1 |
|
C/C++:
omp_init_lock(omp_lock_t *var)
- 作用:初始化一个锁,初始状态为未锁定。
- 注意:在调用此例程之前,锁变量不能与任何锁关联。
设置锁
C/C++
1
void omp_set_lock(omp_lock_t *var)
- 作用:如果锁可用,设置锁并继续执行;如果锁不可用,阻塞等待。
解除锁
C/C++
1
void omp_unset_lock(omp_lock_t *var)
- 作用:解除对锁的所有权,允许其他线程获取锁。
嵌套锁(Nestable Locks)
嵌套锁允许一个任务多次获取同一个锁,并在完成后需要相同次数的释放操作。
1 |
|
任务执行模型(Task Execution Model)
任务执行模型支持非结构化并行性,例如无限循环和递归函数。多个线程可以创建和执行任务。
1 |
|
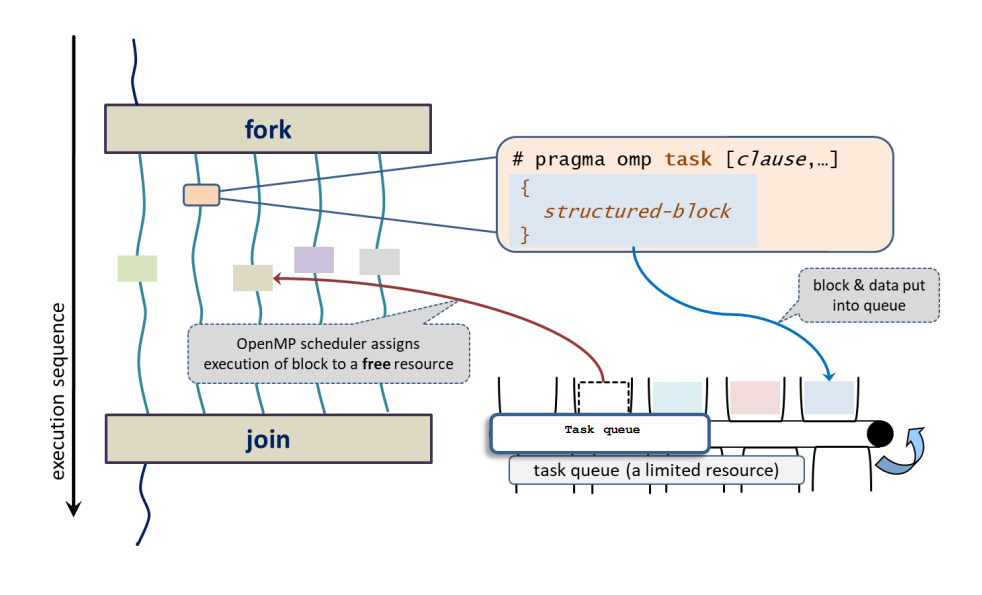
任务的定义与作用
任务是 OpenMP 工作共享的一个更灵活的扩展,允许程序员将代码块和数据项打包为任务,然后将这些任务分配给线程进行执行。任务的主要特点包括:
任务的生成:当一个线程遇到任务构造时,从关联的结构化代码块生成一个任务。
数据环境的创建:根据数据共享属性和默认规则创建任务的数据环境。
任务的执行:生成任务的线程可以立即执行任务,或者将其推迟到稍后执行。在后者情况下,团队中的任何线程都可以被分配执行该任务。
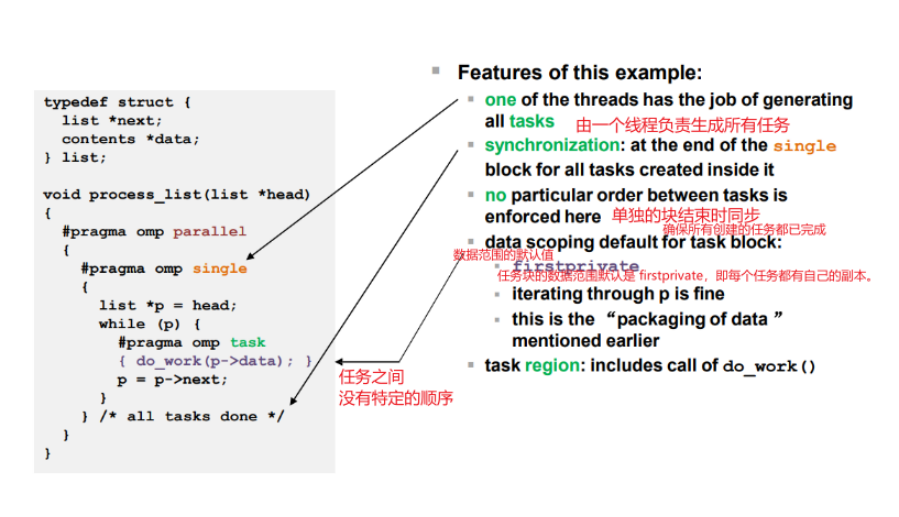
处理链表的函数 process_list:
创建并行区域:
#pragma omp parallel单线程执行块:
1
初始化指针
p指向链表头。使用
while循环遍历链表。对于每个节点,创建一个任务:
1 |
调用
do_work(p->data)处理当前节点的数据。移动指针
p到下一个节点。

1 |
|
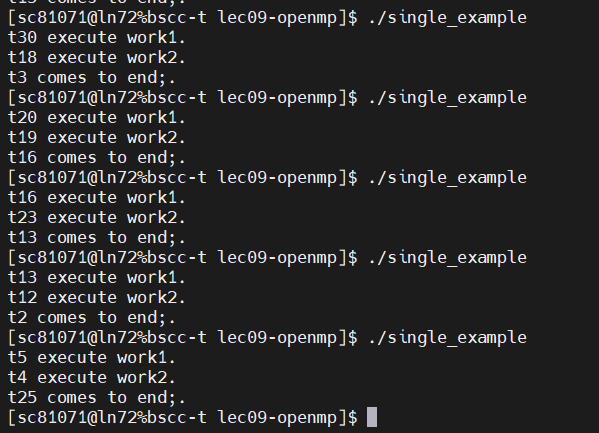
nowait 子句确实可以消除在某些 OpenMP
结构中的隐式同步,但在 single
结构中的作用可能并不像在其他结构(如 for 或
sections)中那样明显。
对于 single 结构,nowait
子句的效果应该是允许其他线程在不等待执行 single
代码块的线程完成其工作后,继续执行其他代码。
尽管 nowait
子句用于消除隐式同步,但在实际执行中,线程调度和前面的隐式同步点仍可能影响代码的执行顺序。这解释了为什么你观察到
t2 comes to end; 总是在最后执行。要验证 nowait
的效果,可以尝试在代码中加入更多的并行工作或调整代码结构,观察其对执行顺序的影响。
任务同步与屏障(Task Synchronization with Barrier and Taskwait)
屏障同步(Barrier Synchronization)
在 OpenMP 中,屏障同步用于确保所有线程都达到某个同步点,然后才继续执行后续的代码。这在并行编程中非常重要,以保证所有线程在同步点之前的工作都已经完成。
#pragma omp barrier
当线程遇到 barrier
指令时,它会在此处等待,直到所有线程都到达屏障,然后所有线程才会继续执行。
任务等待(Taskwait)
任务等待指令用于等待当前任务的子任务完成。与屏障不同,任务等待只同步当前任务的直接子任务,不影响其他线程的执行。
#pragma omp taskwait
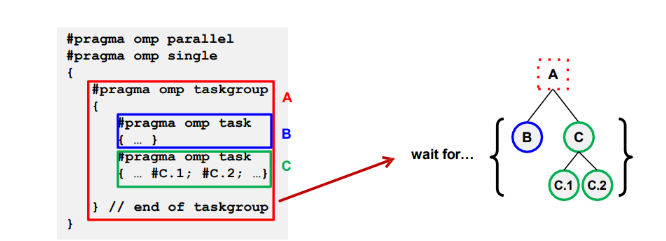
任务组允许创建一个包含多个任务的组,并提供一种方式来等待该组中的所有任务完成。任务组的语法如下:
1 |
|
taskyield 指令简介
taskyield 指令是 OpenMP
提供的一种机制,允许当前任务主动让出处理器,使得运行时系统可以调度和执行其他任务。这对于实现更好的负载均衡和资源利用非常有用,特别是在存在大量任务时。
1 | #pragma omp taskyield |

绑定任务(Tied Tasks)
绑定任务是指任务与执行它的线程绑定在一起。一旦任务开始执行,它必须由同一个线程完成,不能由其他线程接手。
特性
- 任务线程绑定:任务创建后,始终由同一个线程执行,确保任务执行的顺序和连续性。
- 性能优势:由于不需要在多个线程间切换,减少了上下文切换的开销。
非绑定任务(Untied Tasks)
非绑定任务允许任务在执行过程中切换线程。这意味着一个线程可以开始执行任务,而另一个线程可以完成任务。
数据环境(Data Environment)
数据环境子句:
- shared:显式声明变量为共享。
- private:显式声明变量为私有。
- firstprivate:声明变量为私有,并使用其初始值进行初始化。
- lastprivate:声明变量为私有,并在并行区域结束时将其值赋给原变量。
- reduction:对变量进行归约操作。