# Memory bound algorithms
获取数据有时比计算的开销更大:

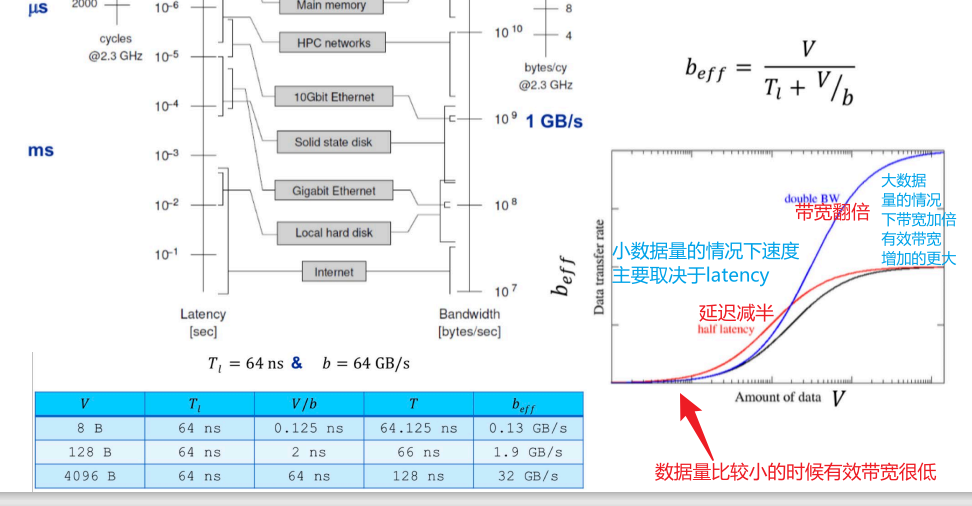
带宽和时延

什么样的运输受限于访存


以稠密矩阵的计算为例
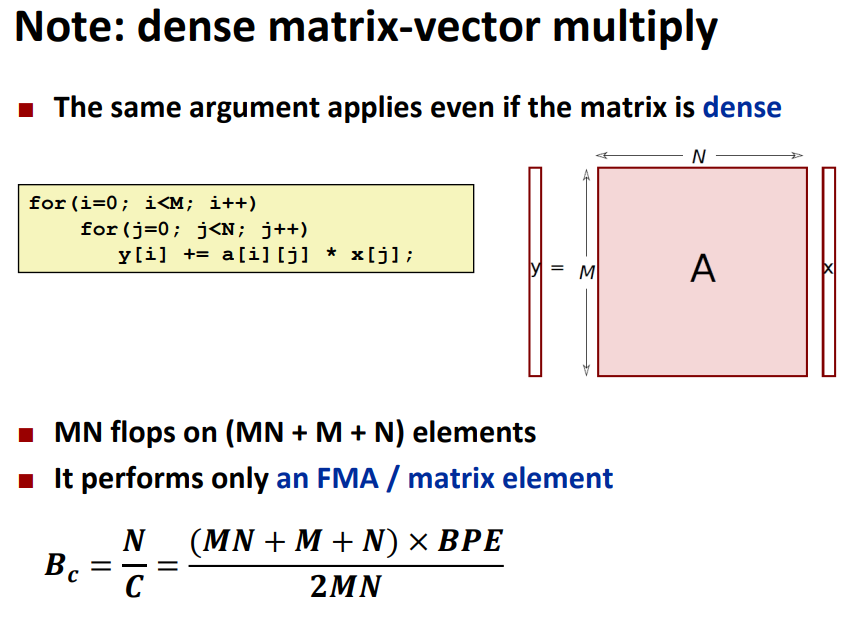
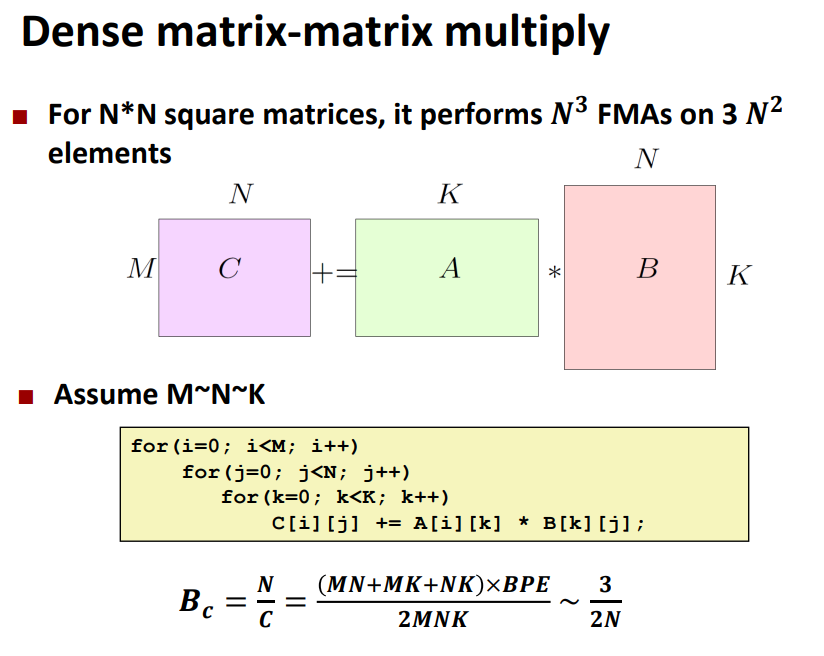
通过计算\(B_c\)可以看出优化的潜力,对于本来就memory
bound的类型,可优化的空间就比较小
Organization of
processors, caches, and memory
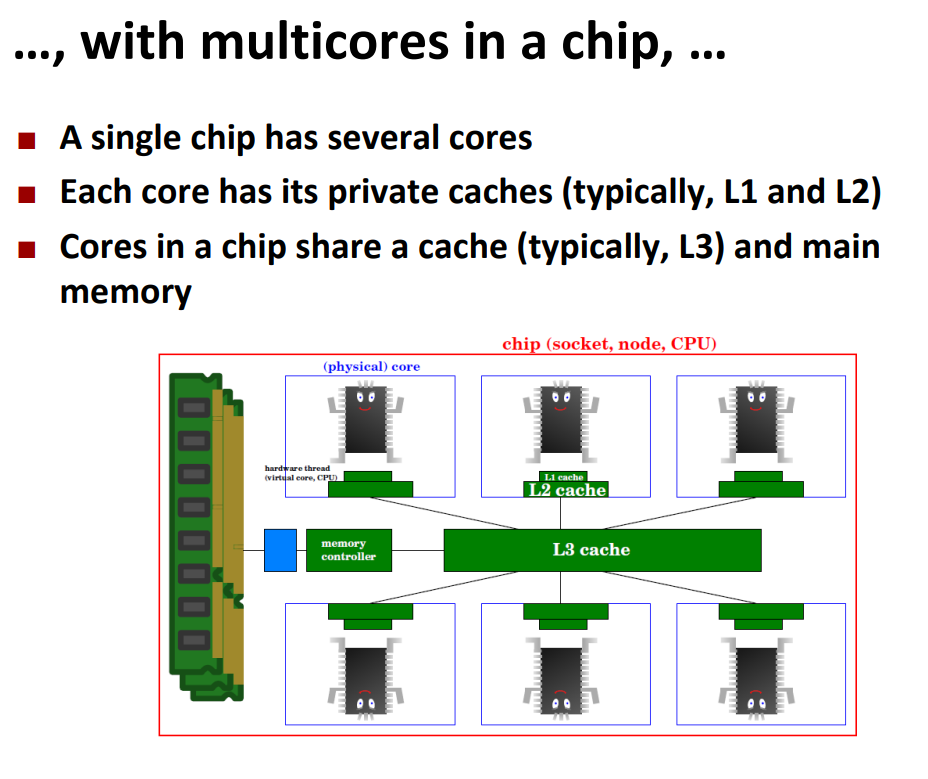
多核:每个核有自己的L1,L2共享一个L3
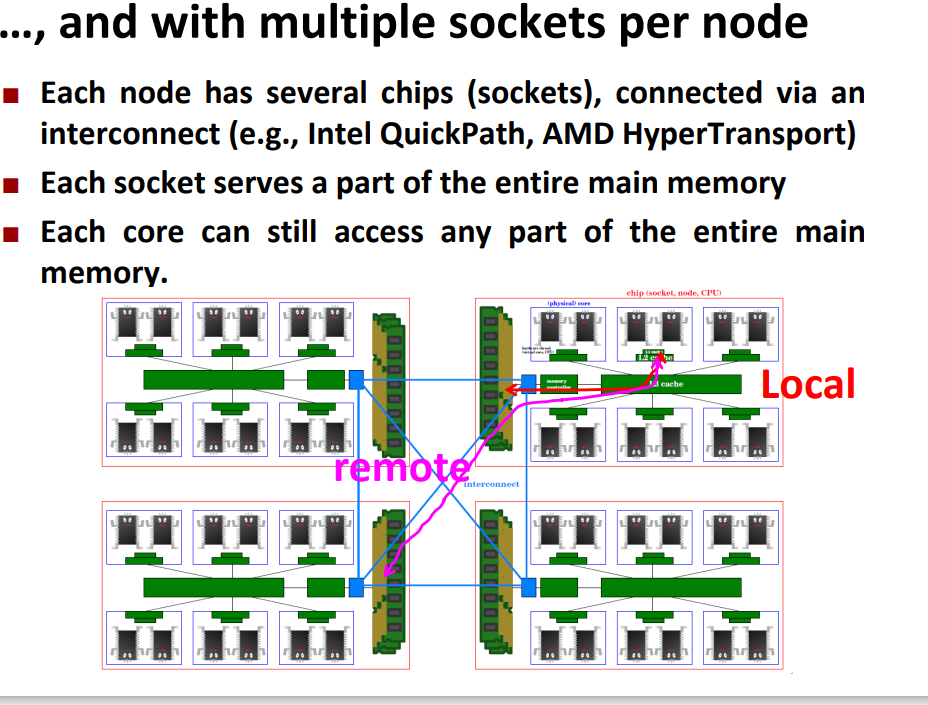
一个node有多个 sockets

Other ways to get more
bandwidth
为什么顺序访问和随机访问在L1的时候性能是一样的。因为比较小的数据一开始warm
up所有的元素都可以在L1上可以找到
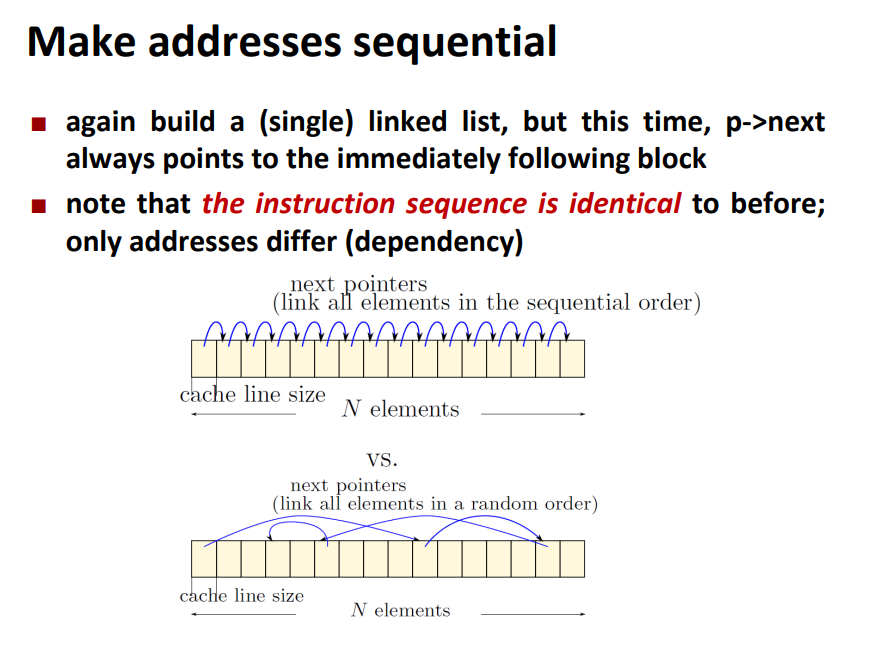
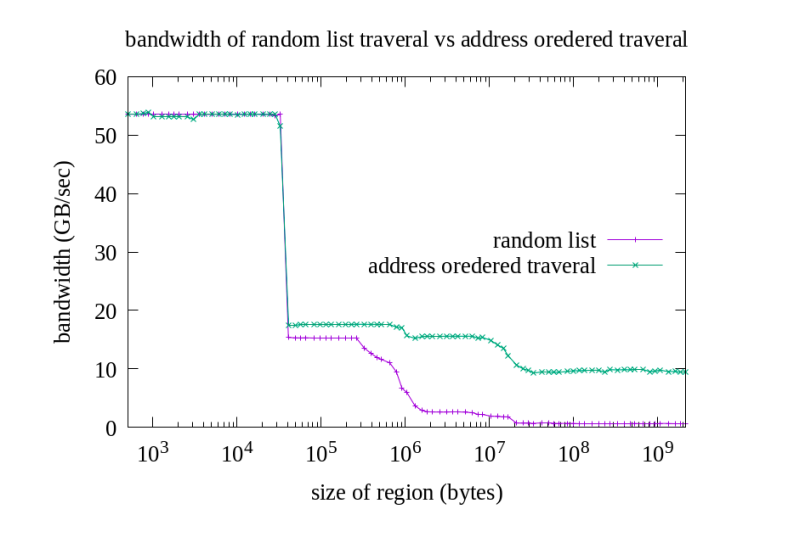
 image-20240402144304188
image-20240402144304188

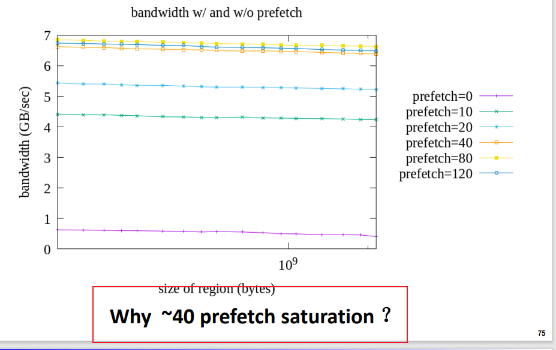
 image-20240402150337148
image-20240402150337148

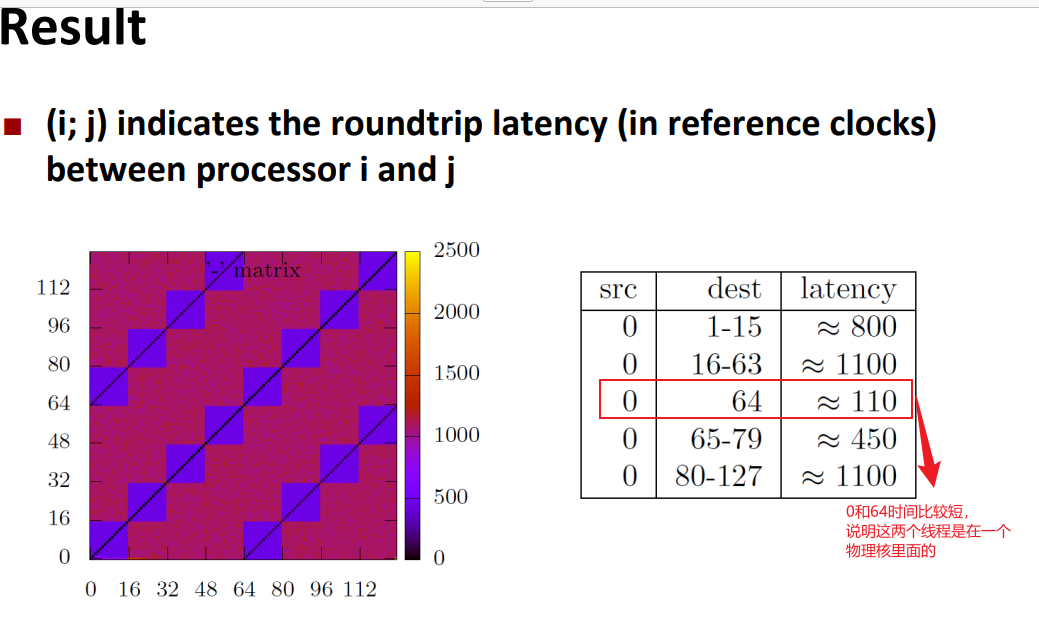 image-20240402153634304
image-20240402153634304

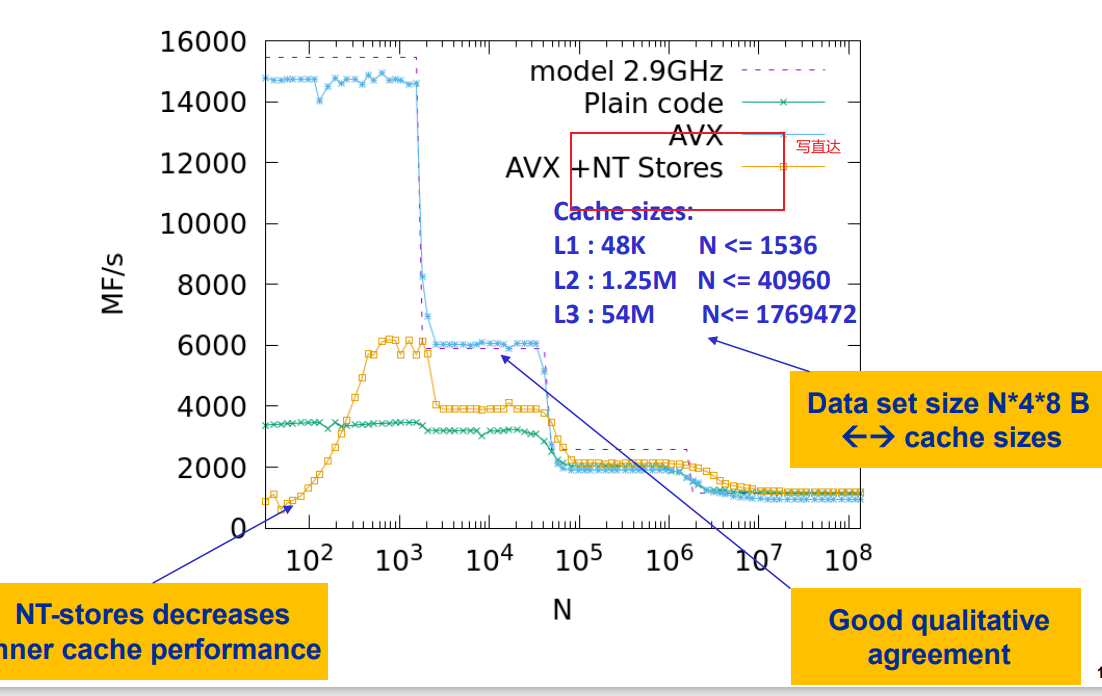
不write alloc
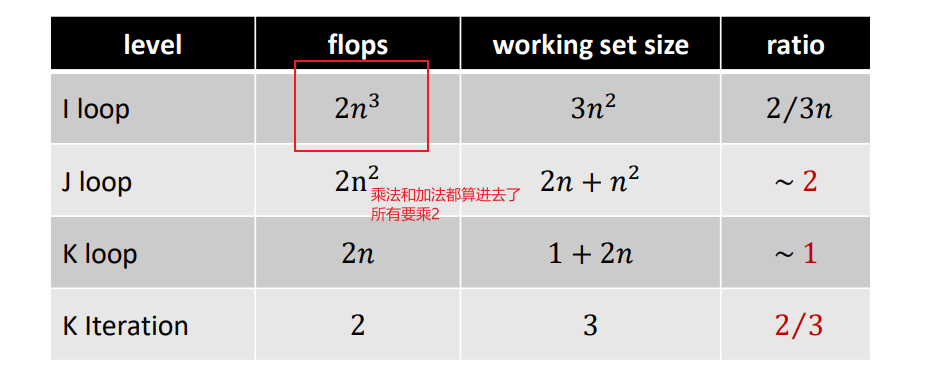 image-20240409143043063
image-20240409143043063
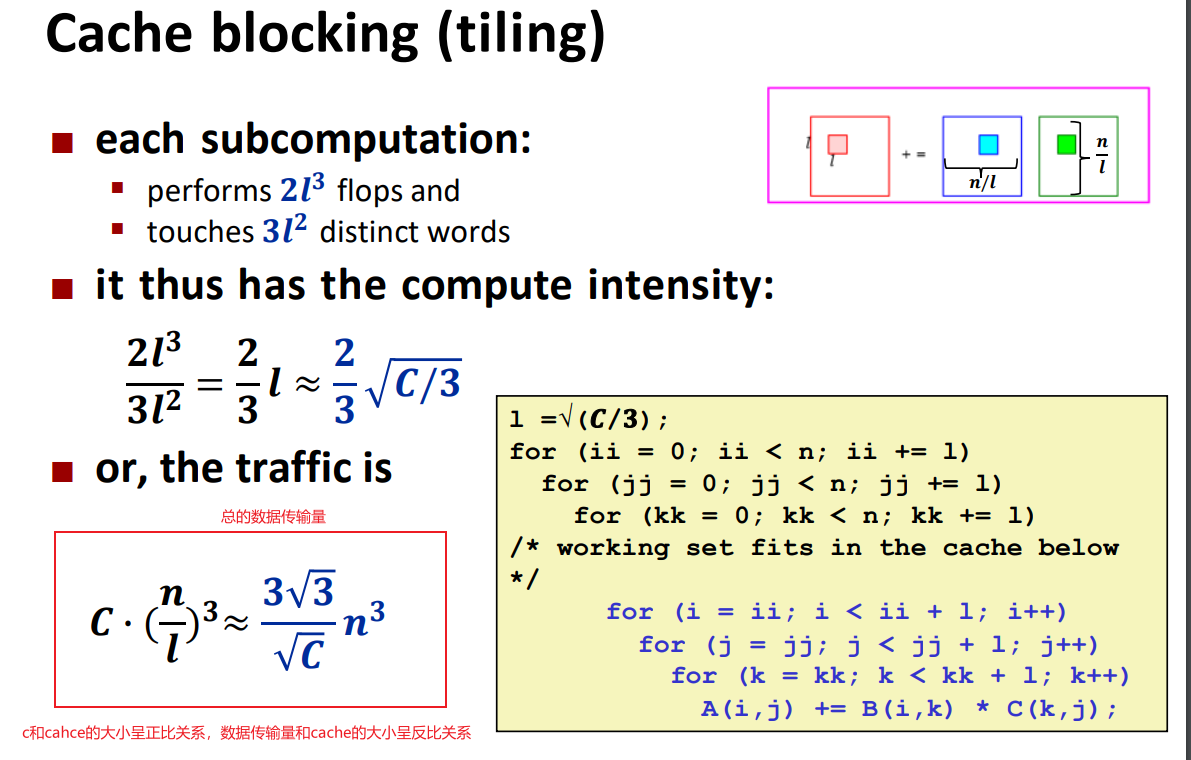 image-20240409143703463
image-20240409143703463
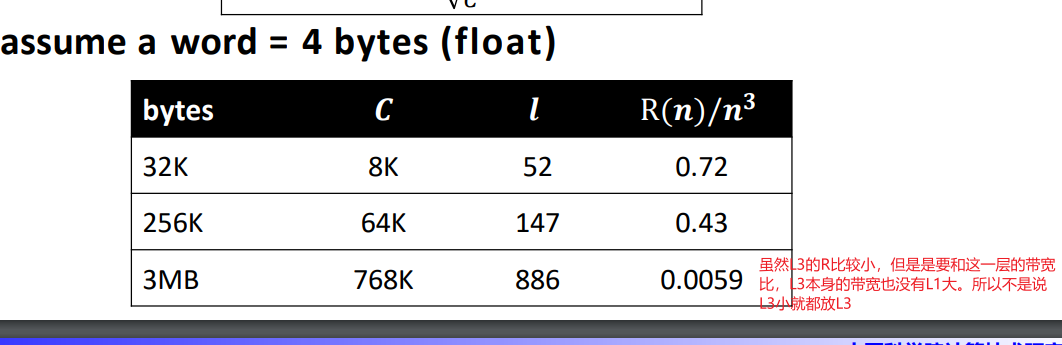
 image-20240409145054028
image-20240409145054028
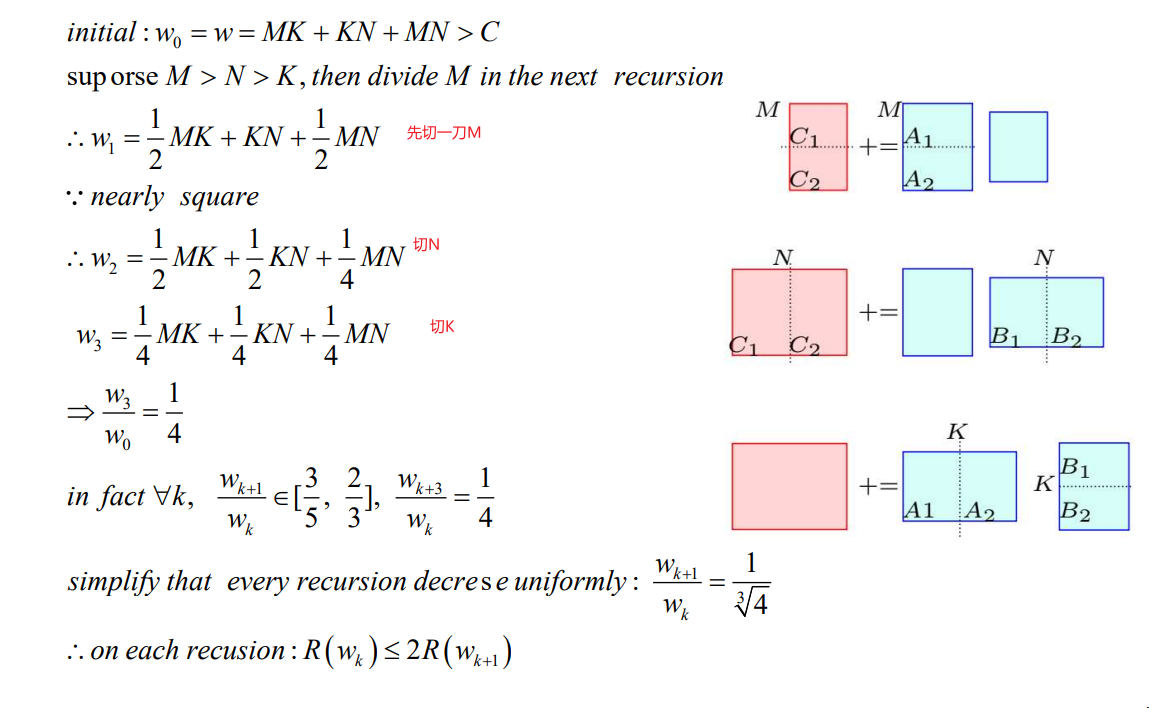 image-20240409150006161
image-20240409150006161
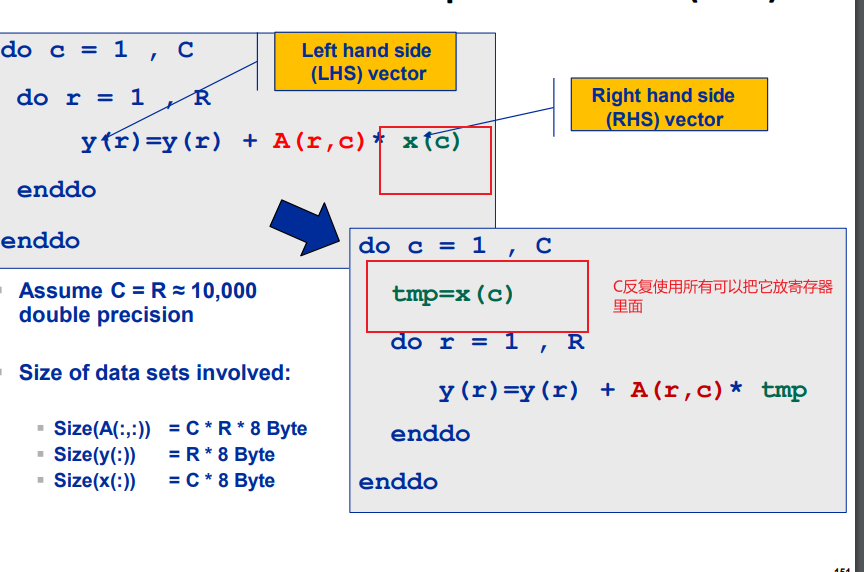 image-20240409153020704
image-20240409153020704
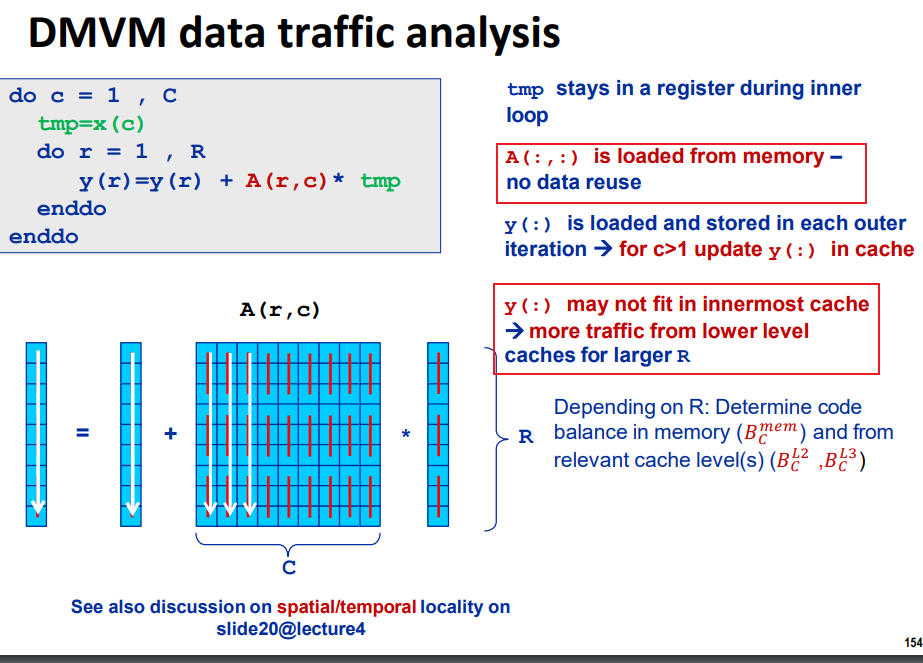 image-20240604000011031
image-20240604000011031
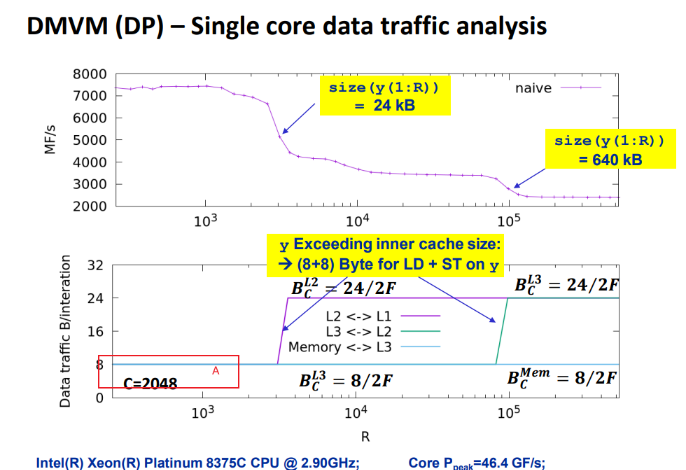
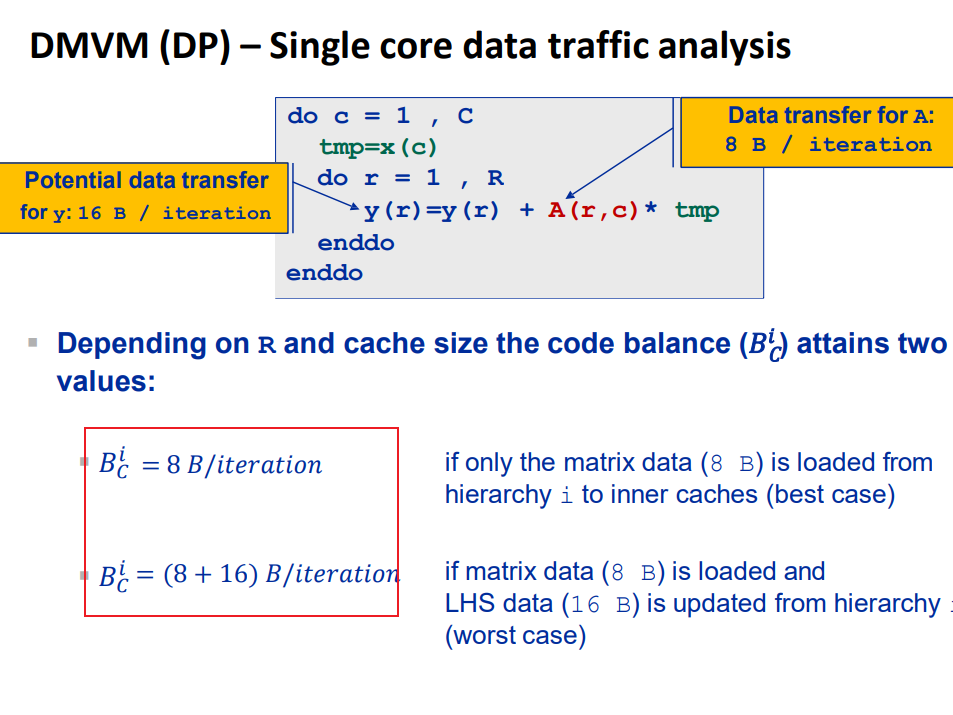 image-20240604002823280
image-20240604002823280
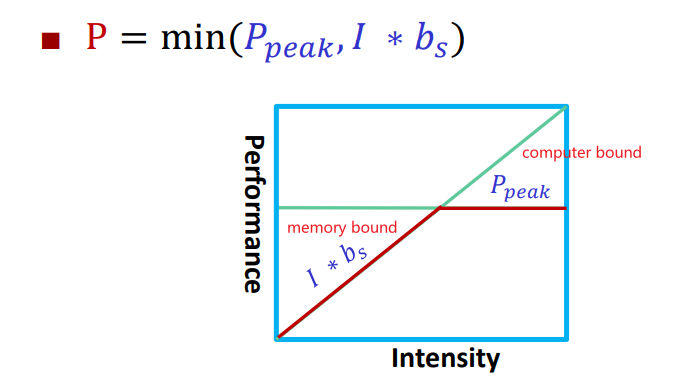
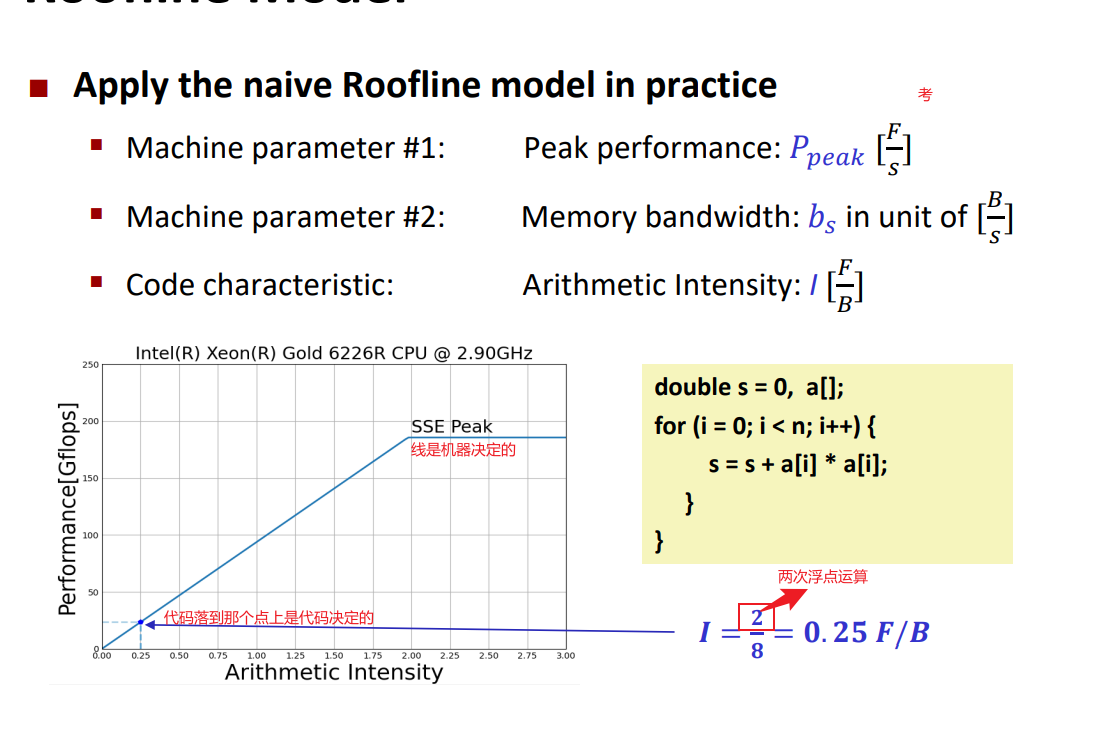

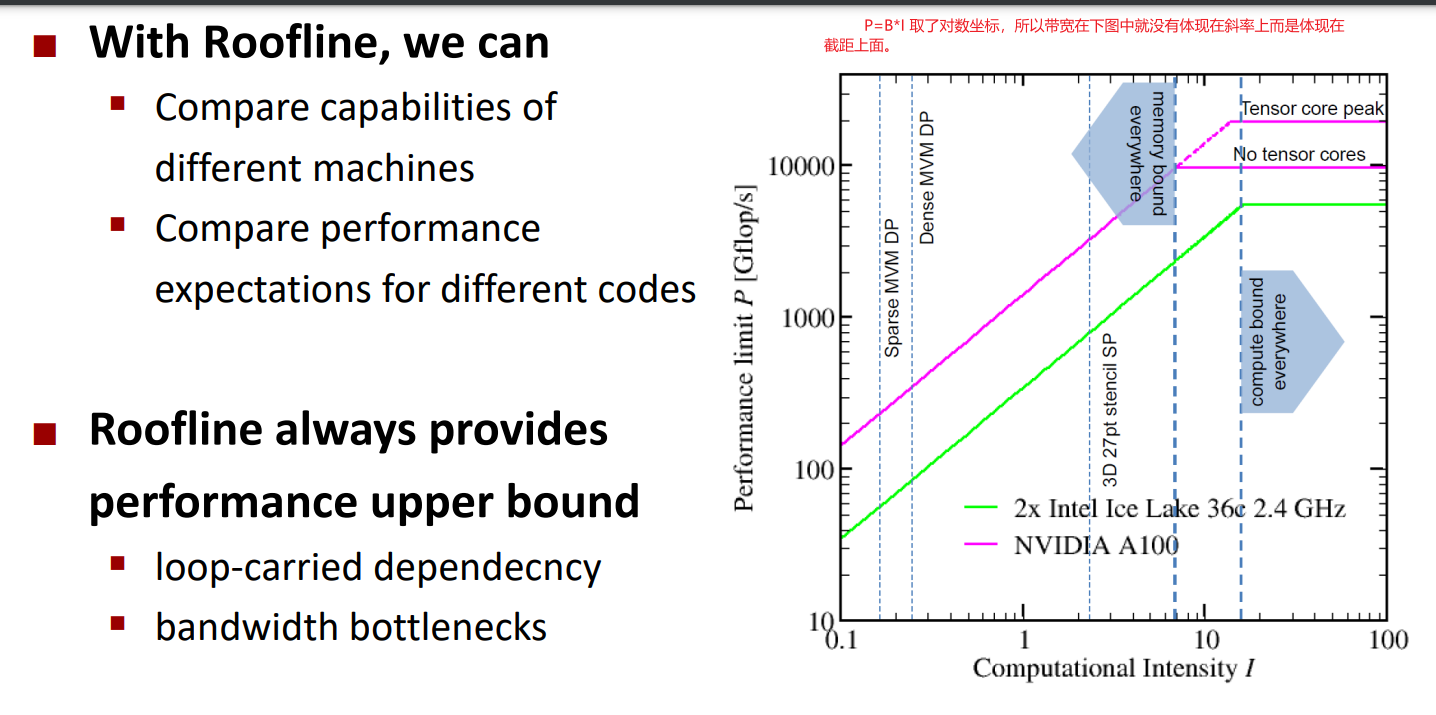 image-20240416150049265
image-20240416150049265
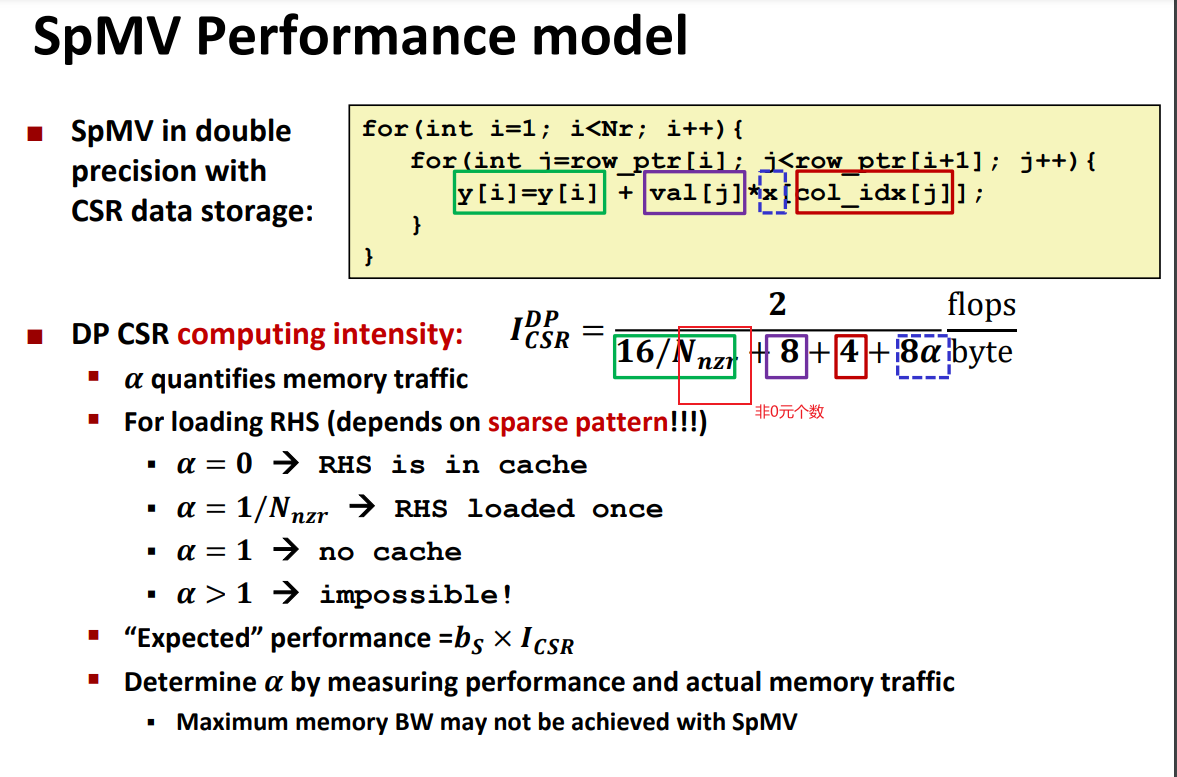 image-20240416163022123
image-20240416163022123
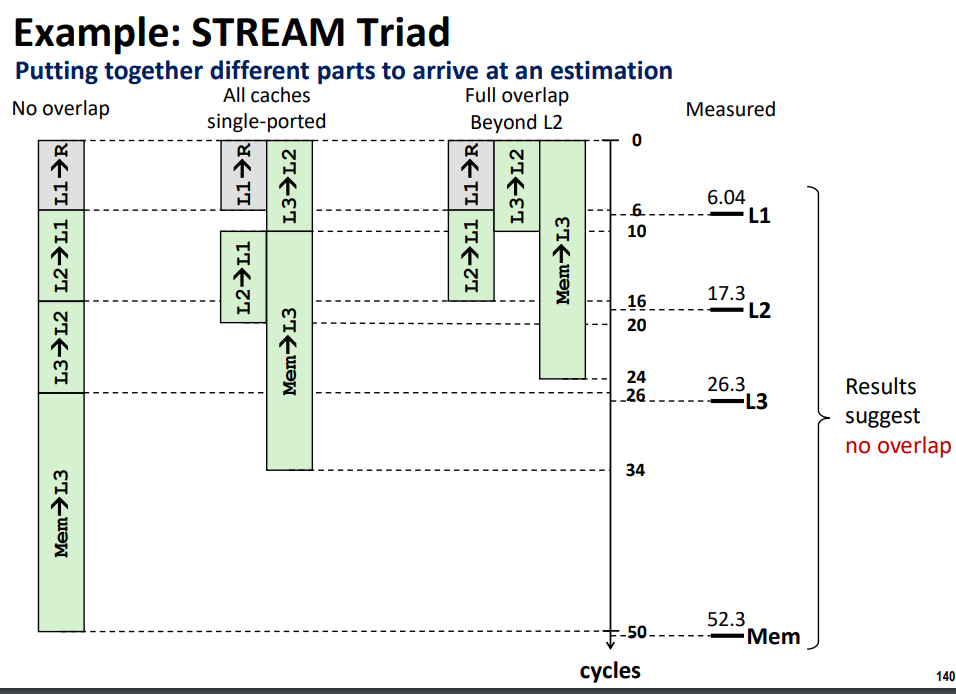 image-20240603160342812
image-20240603160342812
 image-20240603192339780
image-20240603192339780
 image-20240603194843237
image-20240603194843237
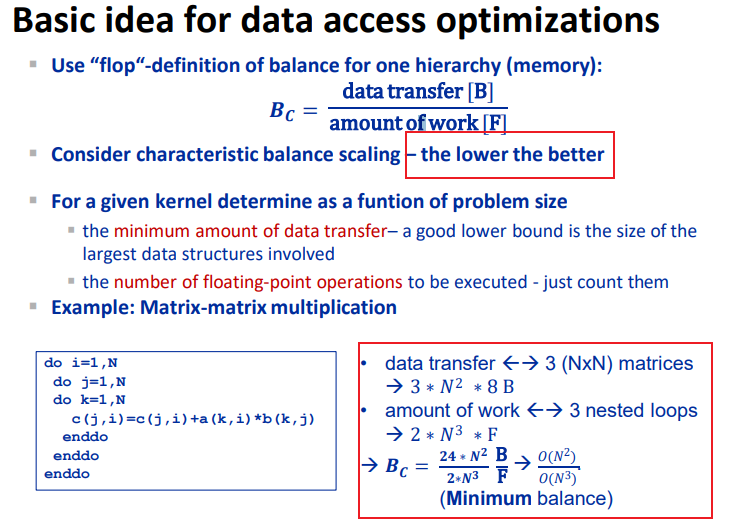 image-20240604092834160
image-20240604092834160
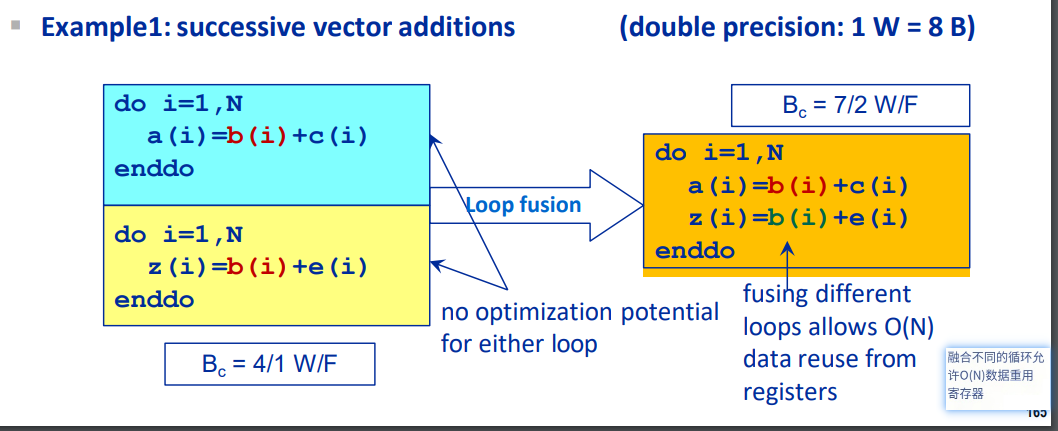 image-20240604093159626
image-20240604093159626
 image-20240604094252125
image-20240604094252125
 image-20240604095524207
image-20240604095524207
 image-20240604101637559
image-20240604101637559