什么是并行计算
并行并发
并行和并发的区别

- 并行 (Parallelism):
- 并行指的是同时执行多个操作,它们在同一时刻发生,可以是在多个处理单元(如多核处理器)上同时执行,也可以是在多台计算机上同时执行。
- 在并行中,多个任务被同时处理,它们的执行时间是重叠的。这意味着这些任务同时在不同的处理单元上进行,可以显著地提高整体性能。
- 典型的例子包括多线程并行执行、多进程并行执行以及分布式系统中的并行计算。
- 并发 (Concurrency):
- 并发指的是在同一时间段内处理多个任务,但并不一定是同时执行。任务可能交替执行,每个任务在一段时间内执行一部分,然后切换到另一个任务继续执行。
- 在并发中,任务可能通过时间片轮转或事件驱动等方式交替执行,以便利用系统资源,同时让多个任务看起来好像是同时在运行。
- 典型的例子包括操作系统中的多任务处理、网络服务器同时处理多个客户端请求以及图形用户界面(GUI)程序中的事件处理。
Type of Parallelism
Job Level Parallelism
- Inter-Job Parallelism(任务间并行性):
- Inter-Job Parallelism 涉及多个独立任务或作业之间的并行执行。
- 在这种并行性中,每个任务都是独立的,彼此之间没有直接的依赖关系,因此可以同时执行。
- 典型的例子包括批处理系统中的并行作业,或者在云计算环境中同时运行的多个虚拟机实例。
- Intra-Job Parallelism(任务内部并行性):
- Intra-Job Parallelism 指的是在单个任务或作业内部的并行执行。
- 在这种并行性中,一个单独的任务被分解为多个子任务,这些子任务可以并行执行以提高整体性能。
- 典型的例子包括在一个大型计算任务中使用多线程或多进程并行处理数据,或者使用向量化指令集来加速数值计算。

task level
程序级别的并行
thread level

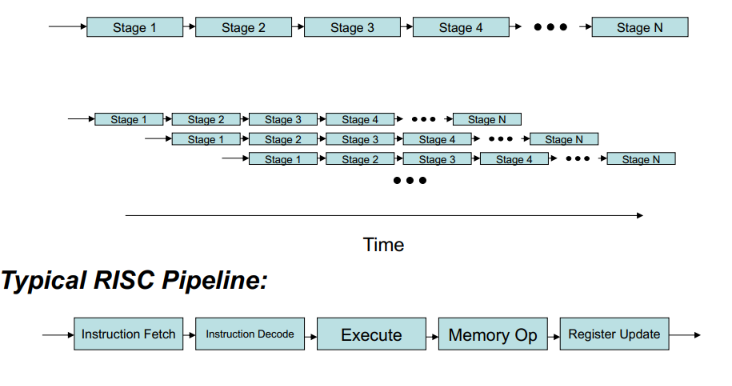
instruction level
- 独立的指令运行在硬件上
- 假设:有多个硬件资源(ALU,Adder,MUltiplier,Loader,MAC unit等)
- 例如指令流水线
并行计算的原则
- 找到足够多的并行(Amdahl 定律)
- 粒度:每一个并行的任务应该有多大
- Locality: 移动数据的开销比计算要大
- 负载均衡:不能让1k个处理器等一个慢的处理器
- 协调和同步:安全的共享数据

即使并行部分完全加速,性能也会受到串行部分的限制
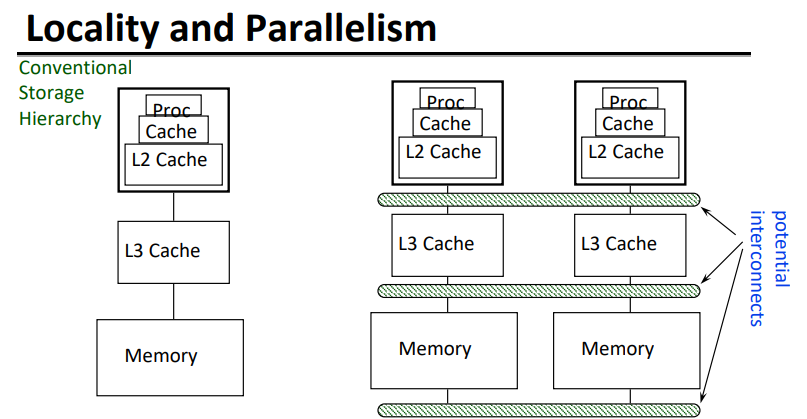
大的内存很慢,快的内存很小
平均而言,存储层次结构大且快
并行处理器总体上具有大而快的cache
对“远程”数据的缓慢访问,我们称之为“通信”。
算法应该在本地数据上做大部分工作