绑定自己的仓库
1 2 3 git remote -v origin git://g.csail.mit.edu/xv6-labs-2021 (fetch) origin git://g.csail.mit.edu/xv6-labs-2021 (push)
使用git remote remove命令移除远程仓库的关联。请将`替换为要移除的远程仓库的名称,一般为origin`。
然后绑定自己的仓库:git remote add origin git@github.com:sherecho/MyOS_Prj.git
gdb 调试
设置.gdbinit 文件
1 2 3 4 5 6 7 8 9 10 11 add-auto-load-safe-path /xv6-labs-2021/.gdbinit set confirm off set architecture riscv:rv64 target remote 127.0.0.1:25000 symbol-file kernel/kernel set disassemble-next-line auto set riscv use-compressed-breakpoints yes file user/_primes layout src b main c
运行make qemu-gdb
在另一个shell里面运行
gdb-multiarch -x .gdbinit
primes
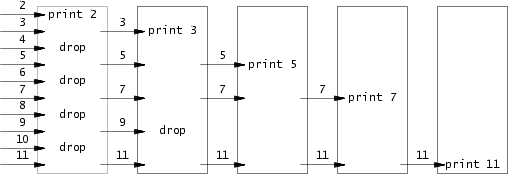
创建一系列的进程,父子进程之间通过管道进行通信,以此实现质数过滤的效果。第一个进程将2-35通过管道送入子进程,子进程打印第一个2,然后将管道中剩余数中能被2整除的丢弃 ,剩余的数通过管道送入它自己的子进程,如此递归。
img
设计思路:
首先最初始的父进程负责将所有的数字通过管道协调如
子进程递归调用:每次从传入的管道段读取数值并过滤,然后将剩余的数通过管道传给下一个子进程
注意:读取管道时要关闭管道的输入端,管道输入端不关闭时,输出端使用
read读取时会阻塞不返回,程序就死在了某处。
程序代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include "kernel/types.h" #include "user/user.h" void childproc (int *p) { int num; int ret; if ((ret=read(p[0 ],&num,sizeof (int )))!=sizeof (int )){ printf ("program finished!\n" ); exit (0 ); } printf ("prime %d\n" ,num); int p1[2 ]; int pr=pipe(p1); if (pr<0 ){ fprintf (2 , "pipe p1 err\n" ); exit (1 ); } int pid; if ((pid = fork()) < 0 ) { fprintf (2 , "fork err\n" ); exit (1 ); } else if (pid==0 ){ close(p1[1 ]); close(p[0 ]); childproc(p1); } else { close(p1[0 ]); int num2; int ret; while ((ret=read(p[0 ],&num2,sizeof (int )))==sizeof (int )){ if (num2%num!=0 ){ if ((ret=write(p1[1 ],&num2,sizeof (int )))!=sizeof (int )){ fprintf (2 , "write err1\n" ); exit (1 ); } } } close(p1[1 ]); close(p[0 ]); wait(0 ); exit (0 ); } } int main (int argc,char * argv[]) { int p[2 ]; pipe(p); int pid; if ((pid=fork())<0 ){ fprintf (2 ,"fork error\n" ); exit (1 ); } else if (pid==0 ){ close(p[1 ]); printf ("in child: %d\n" ,getpid()); childproc(p); exit (0 ); } else { close(p[0 ]); for (int i=2 ;i<=35 ;i++){ if (write(p[1 ],&i,sizeof (int ))!=sizeof (int )){ fprintf (2 , "write err\n" ); exit (1 ); } } close(p[1 ]); wait(0 ); exit (0 ); } }
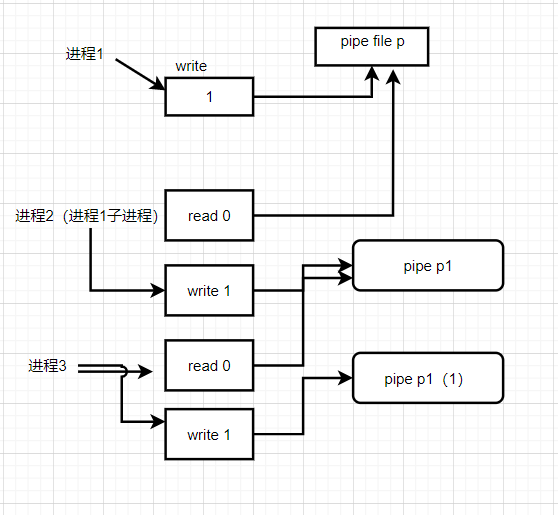
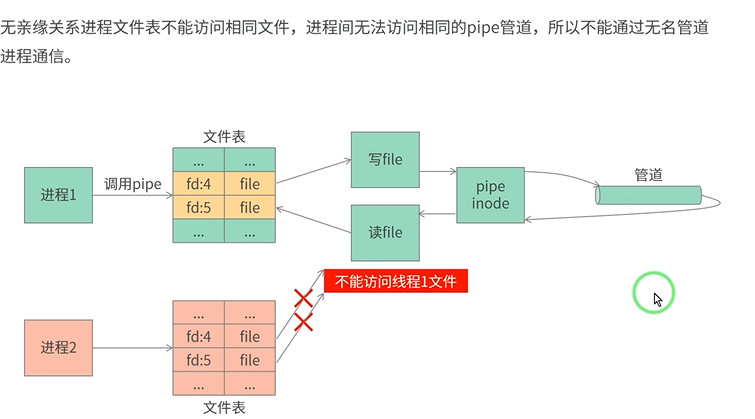
匿名管道通信
在实验过程中,发现如果加入close(p[1])
见代码。会导致程序错误无法完成写管道操作。为了仔细分析一下产生这种情况的原因,首先分析管道的原理:
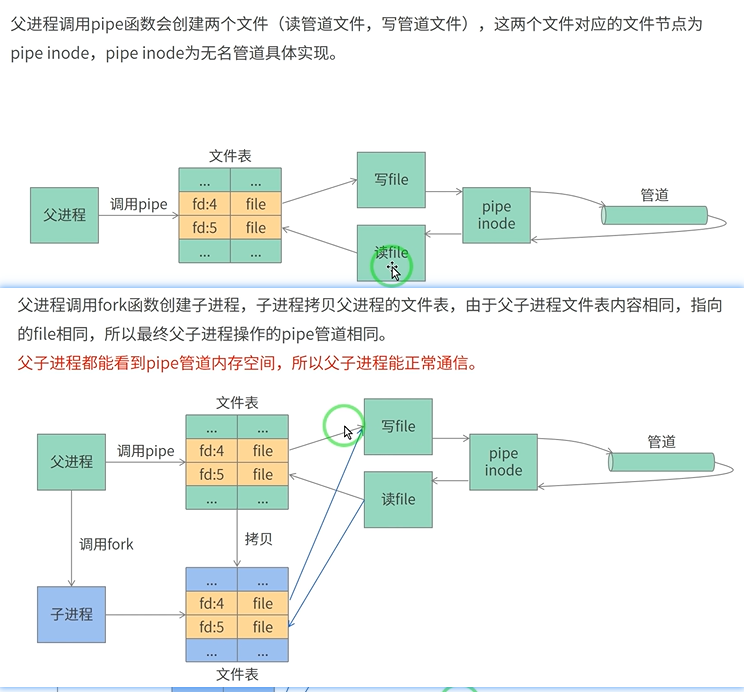
首先,因为进程之间具有独立性,一个进程是看不到另一个进程的资源的。
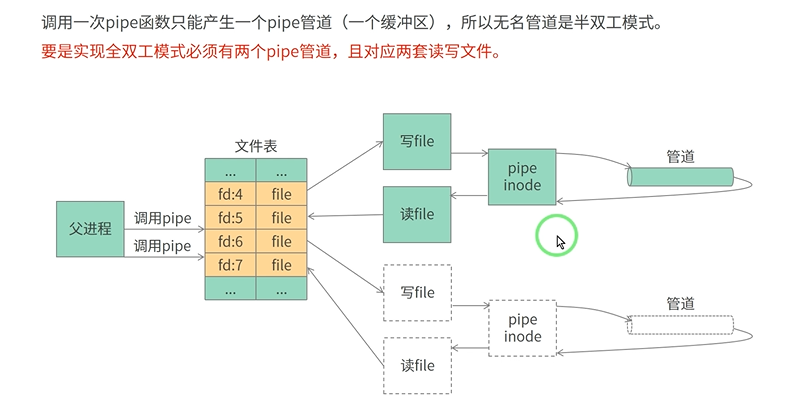
一个管道是半双工的,所以一般使用两个管道进行通信
如果所有指向管道写端的文件描述符都关闭了(管道写端的引用计数等于0),而仍然有进程从管道的读端读数据,那么管道中剩余的数据都被读取后,再次
read 会返回0,就像读到文件末尾一样。
如果有指向管道写端的文件描述符没关闭(管道写端的引用计数大于0),而持有管道写端的进程也没有向管道中写数据,这时有进程从管道读端读数据,那么管道中剩余的数据都被读取后,再次
read 会阻塞,直到管道中有数据可读了才读取数据并返回。
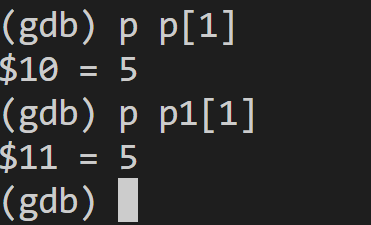
通过gdb调试多进程分析错误原因
这里虽然是进程,但是实际上属于一种线程。可以用gdb info threads
查看线程并调试
调试的时候发现,不知道为啥p和p1的写管道描述符是一样的,所以关了p的话会存在问题
但是为啥会是一样的呢?这看起来不太合理。
find
这道题是要求实现一个简易版本的find命令,思路也是比较简单,递归的遍历目录中的子文件或子目录,可以参考ls.c文件来实现。需要注意细节问题,也就是关于.和..目录的处理,遍历遇到这两个目录时不要进去,不然会无穷递归。
首先,通过 kernel/fs.h 中的 fstat
可以读取路径信息,
1 2 3 4 5 6 7 int fd = open(path, 0 ); struct stat st ;fstat(fd, &st); if (st.type == T_FILE) {} if (st.type == T_DIR) {}
首先看下fmtname是干啥的:
printf("buf:%s, fmtnamr(buf):%s %d %d %d\n", buf,fmtname(buf), st.type, st.ino, st.size);
可以看出,fmtname是把名字打印出来了。考虑修改fmtname是可能实现题目要求的
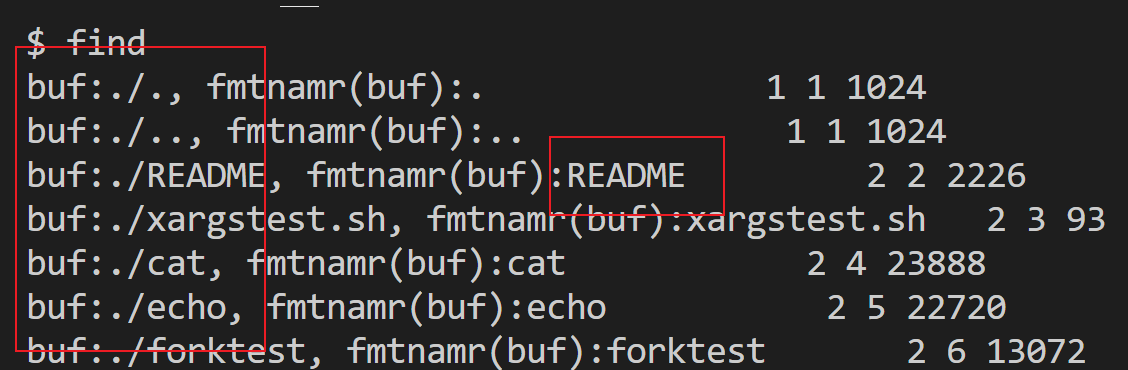
注意:memset(buf+strlen(p), ' ', DIRSIZ-strlen(p));
是用空格填充了字符串,我们可以看出如果字符填充,调用fmtname可能会出现不等的情况如下图所示:
所以要改成memset(buf+strlen(p), 0, DIRSIZ-strlen(p));用结束符号填充
实验代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" char *fmtname (char *path) { static char buf[DIRSIZ+1 ]; char *p; for (p=path+strlen (path); p >= path && *p != '/' ; p--) ; p++; if (strlen (p) >= DIRSIZ) return p; memmove(buf, p, strlen (p)); memset (buf+strlen (p), 0 , DIRSIZ-strlen (p)); return buf; } int iffrec (char * path) { char * buf; buf=fmtname(path); if (buf[0 ]=='.' &&buf[1 ]==0 ){ return 0 ; } if (buf[0 ]=='.' &&buf[1 ]=='.' ){ return 0 ; } return 1 ; } void find (char *path,char * target) { char buf[512 ], *p; int fd; struct dirent de ; struct stat st ; if ((fd = open(path, 0 )) < 0 ){ fprintf (2 , "ls: cannot open %s\n" , path); return ; } if (fstat(fd, &st) < 0 ){ fprintf (2 , "ls: cannot stat %s\n" , path); close(fd); return ; } if (strcmp (path,target)==0 ){ printf ("%s\n" ,path); } switch (st.type){ case T_DIR: if (strlen (path) + 1 + DIRSIZ + 1 > sizeof buf){ printf ("ls: path too long\n" ); break ; } strcpy (buf, path); p = buf+strlen (buf); *p++ = '/' ; while (read(fd, &de, sizeof (de)) == sizeof (de)){ if (de.inum == 0 ) continue ; memmove(p, de.name, DIRSIZ); p[DIRSIZ] = 0 ; if (stat(buf, &st) < 0 ){ printf ("ls: cannot stat %s\n" , buf); continue ; } if (strcmp (fmtname(buf),target)==0 ){ printf ("%s\n" ,buf); } if (iffrec(buf)){ find(buf,target); } } break ; } close(fd); } int main (int argc, char *argv[]) { if (argc==1 ){ printf ("error wrong input num\n" ); exit (0 ); } if (argc == 2 ){ find("." , argv[1 ]); exit (0 ); } if (argc==3 ){ find(argv[1 ], argv[2 ]); exit (0 ); } exit (0 ); }
xargs
第一个命令的输出会变成第二个命令的输入
-n 表示遇到一个换行符执行一次命令,所以这里有两行,执行两次命令
1 2 3 4 $ echo "1\n2" | xargs -n 1 echo line line 1 line 2 $
首先,如何获取前一个命令的标准化输出,如何获取自己的命令后参数。如何使用exec执行命令
在内部,xv6内核为每一个进程单独维护一个以文件描述符为索引的表,因此每个进程都有一个从0开始的文件描述符私有空间。按照约定,一个进程从文件描述符0(标准输入)读取数据,向文件描述符1(标准输出)写入输出,向文件描述符2(标准错误)写入错误信息。
1 2 3 4 5 6 7 8 9 10 11 12 #define BUFSIZE 16 int main (int argc,char * argv[]) { char buf[BUFSIZE]; read(0 ,buf,BUFSIZE); printf ("input:%s\n" ,buf); for (int i=0 ;i<argc;++i){ printf ("argv: %c\n" ,argv[i]); } exec("echo" ,argv); exit (0 ); }
通过将 p 赋值为 buf,p
就指向了缓冲区 buf 的首地址。这样,通过操作指针
p,可以对缓冲区进行读取、写入等操作。
在这段代码中,p
的作用是用于处理从标准输入读取的一行字符串。通过不断地移动
p,可以逐个字符地处理输入的字符串,直到遇到换行符,表示读取完一行。在处理完一行后,通过将
p 重新指向 buf
的起始位置,准备处理下一行。这样循环处理,达到逐行处理输入的效果。
解题代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/param.h" #define BUF_SIZE 512 int main (int argc, char * argv[]) { if (argc < 2 ) { fprintf (2 , "Usage: xargs command\n" ); exit (1 ); } char * args[MAXARG+1 ]; int index = 0 ; for (int i=1 ; i<argc; ++i) { args[index++] = argv[i]; } char buf[BUF_SIZE]; char *p = buf; while (read(0 , p, 1 ) == 1 ) { if ((*p) == '\n' ) { *p = 0 ; int pid; if ((pid = fork()) == 0 ) { args[index] = buf; exec(argv[1 ], args); fprintf (2 , "exec %s failed\n" , argv[1 ]); exit (0 ); } wait(0 ); p = buf; } else { ++p; } } exit (0 ); }