静态流水线
静态流水线
标准五级静态流水线
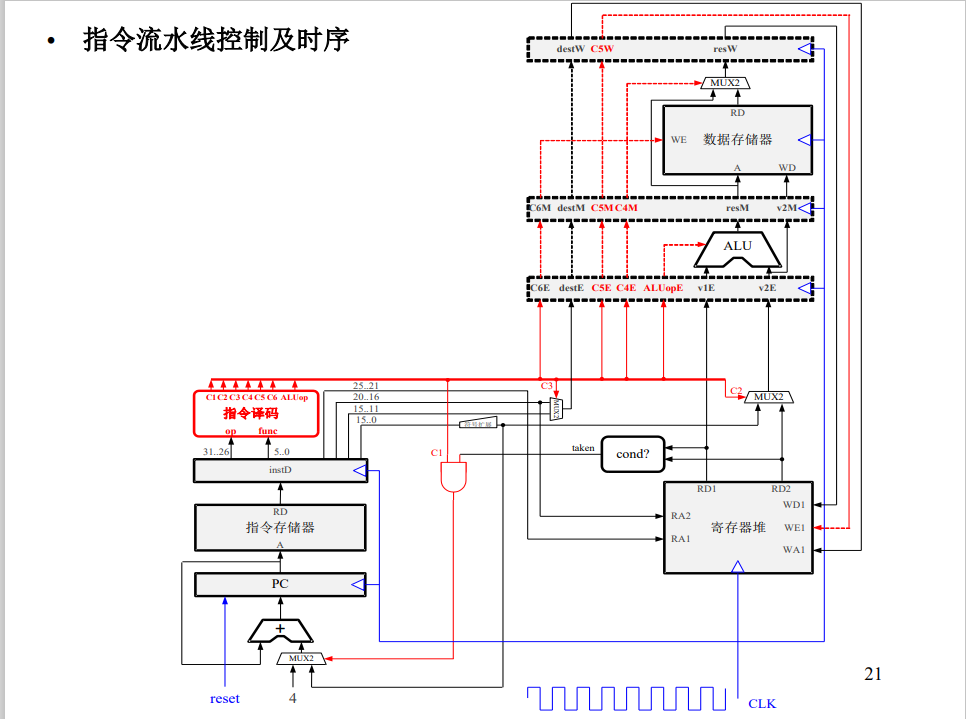
按照上面的设计,指令流水线是五级流水线如下图所示。
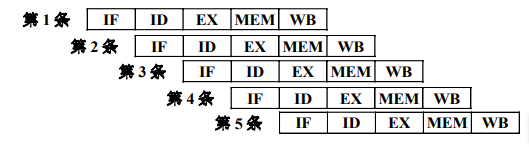
IF 取指
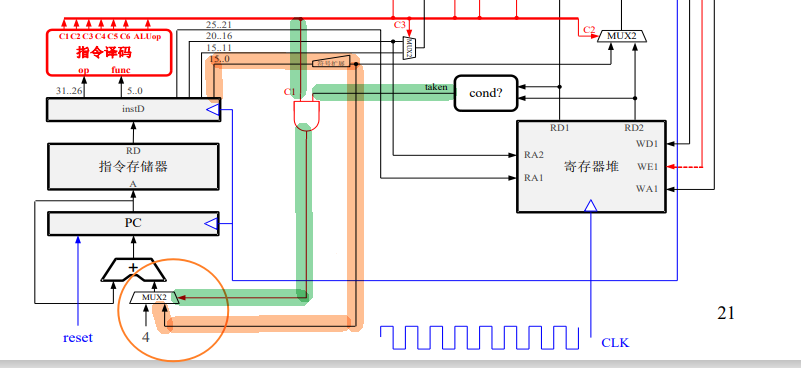
IF阶段pc取指,从上图中可以看出,pc取值有俩个来源:pc+4即顺序取值。和来自转移指令计算得到的地址。从下图中可以看出,当为转移指令时,地址是立即数的有符号扩展(有符号表明PC指针可以往前跳也可以往后跳)。这个MUX2的控制逻辑由两部分组成:判断指令是不是条件转移指令(C1),以及是否满足跳转条件(由cond产生)。
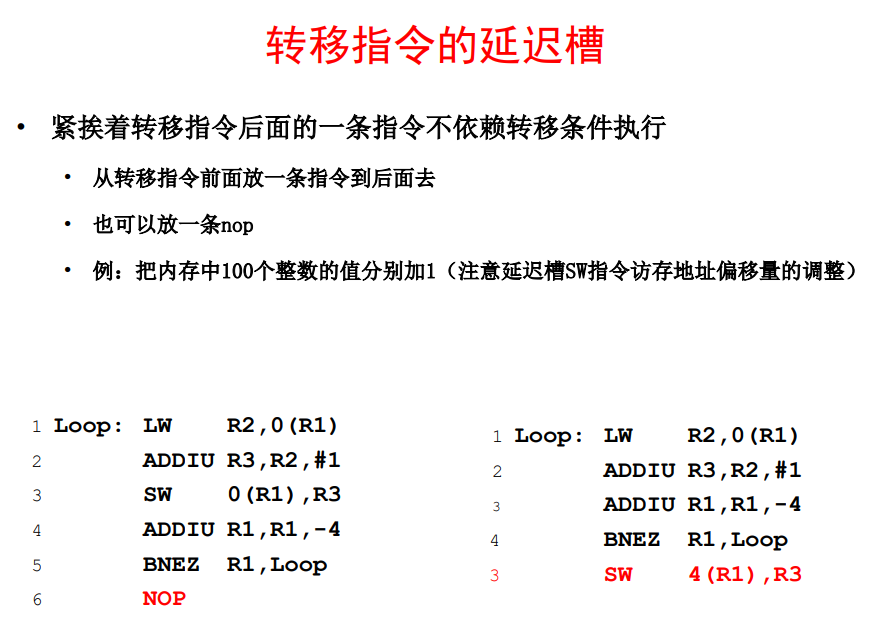
转移指令是否跳转如果在EX执行阶段才能算出来的话,会导致流水线堵塞两拍(下级的IF要到EX执行完以后才能完成)。因此为例减少堵塞,转移指令的地址在cond也就是ID阶段就完成了判断。这样后面只需要卡一拍。MIPS为了解决这个问题,设计了转移指令延迟槽,也就是不管指令要不要跳转,转移指令的下一条指令都要执行,这样就避免了流水线阻塞。一般可以通过调度,填充NOP提高效率,如下所示。
ID译码
以MIPS为例,根据指令格式进行译码,然后从寄存器中读数为执行级做准备。转移指令比较特殊,会在ID判断是否需要taken

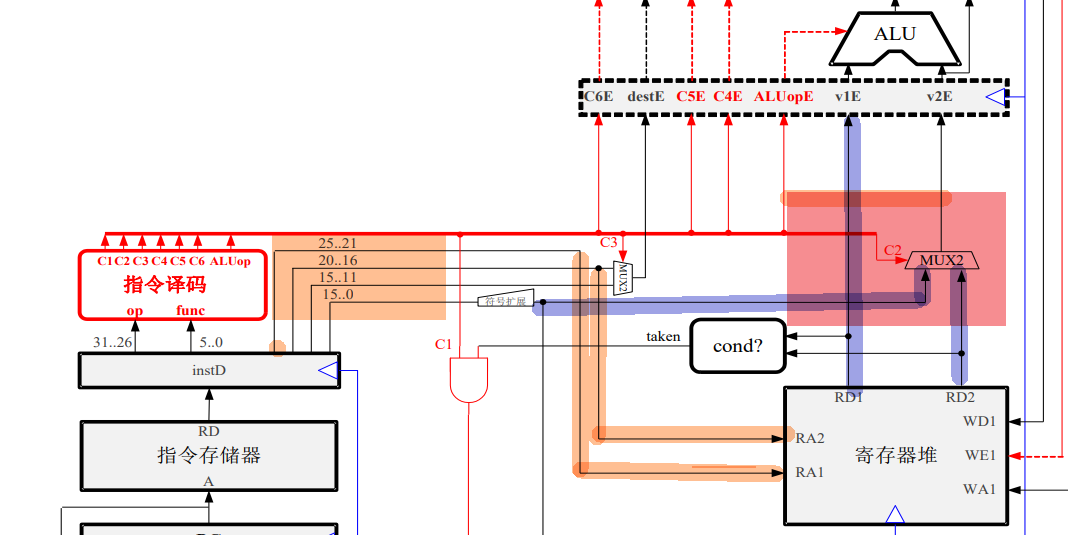
EX执行与ALU
ALU简单的实现:
1 | module alu_module |
简单例子

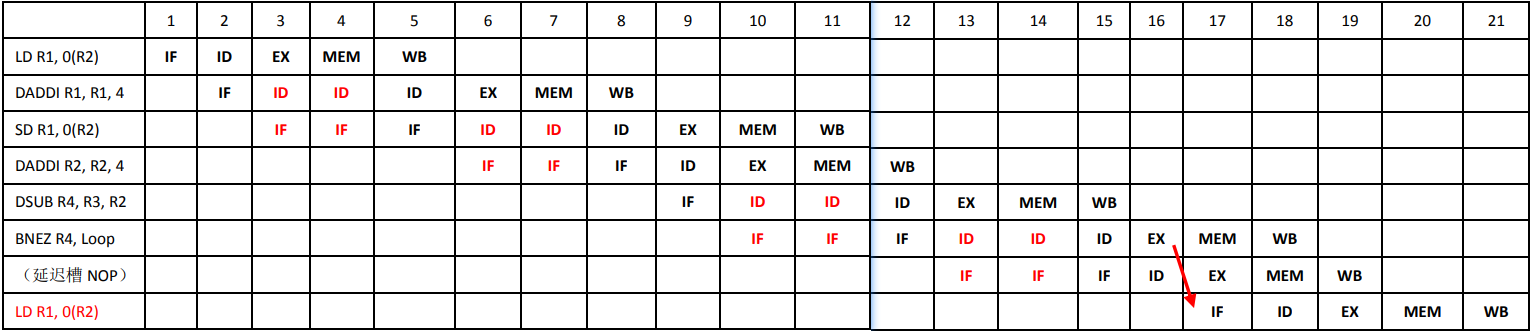
1 | LW R2,0(R1) |


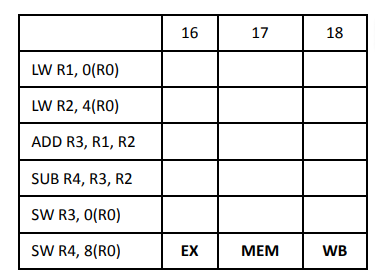
指令相关和流水线冲突

数据相关
数据相关按照读写次序可以分为三种:RAW,WAR,WAW
RAW:后面指令用到前面指令所写的数据 ,是真相关
WAW和WAR又称为名字相关,是寄存器相同导致的相关,可以通过寄存器重命名来消除
WAW(Write After Write)
两条指令写同一个单元
在简单流水线中没有此类相关,因为不会乱序执行。乱序执行后存在WAW
WAR(Write After Read)
后面指令覆盖前面指令所读的单元
在简单流水线中没有此类相关,在乱序执行时会遇到这类相关
访存相关:寄存器不一样但是内存物理地址可能相同造成的相关,这个比较麻烦,因为虚实地址转换是比较慢的。
请给出一种在多发射动态调度的处理器上解决访存相关的方案。
1)使用 store buffer 来作为一个临时性位置存放写操作的值。在 store 指令提交的时候才写入到 cache 中。
2)store 指令按程序的顺序写回到 cache 中。任何访问相同地址的 load 可以从之前的 store 指令中获得值,即 load forwarding 技术
3)两种方法:一是非推测的方法,后续的 load 指令不能超过前面的 store 指令,通常采用 load forwarding 技术;二是推测的方法,speculative load execution。例如一条 store 指令后面有一条 load 指令,而 store 指令的访存地址还没有计算出来,很可能 load 的地址 就是 store 的指令的地址,因此可能存在着 RAW 相关。推测的方法 speculative load-store reordering 是一种推测执行的技术,就像分支预测之后的推测执行一样,可以把阻塞的 store 指令之后的 load 指令提前执行,等 store 指令访存地址计算之后,和其后续的 load 指令的访存地址进行比较,如果访存地址有交叉,则需要取消该 load 指令,以及和它相关 的后续指令,重新开始执行,和分支误预测一样处理
控制相关
例如转移指令造成的相关

结构相关
两条指令要同时访问流水线中同一个功能部件造成的。例如控制相关本质上就是PC指针的控制相关
流水线前递技术
如下所示就是EX和MEM实现前递的通路,前递后下一级需要使用寄存器的值就不用等到wb写回后才能完成ID了,可以减少流水线阻塞。
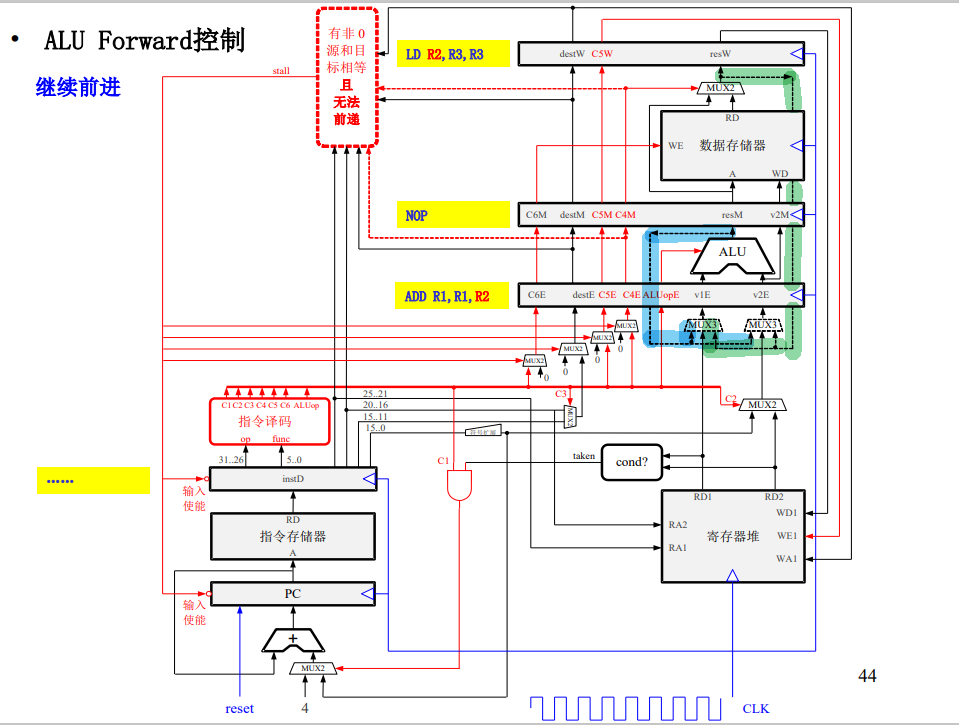
寄存器堆的读写端口内部也可以做前递即WB级的前递。
例子

1 | ADDIU R5,R0,N |
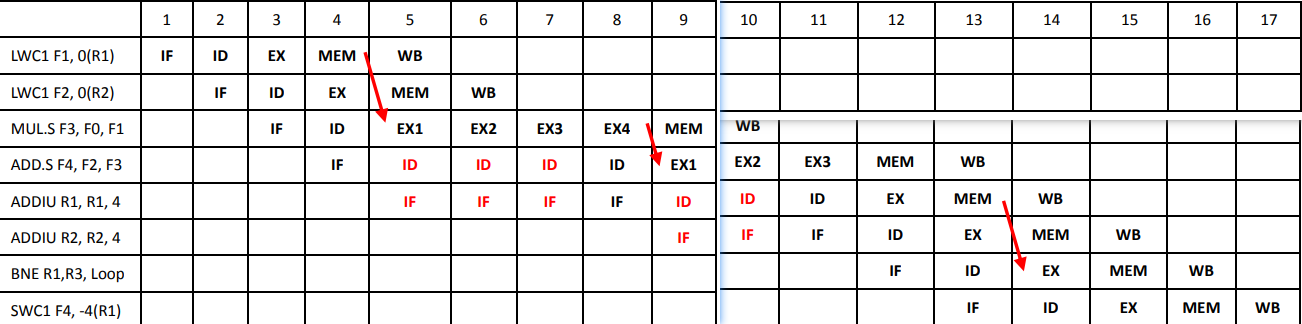
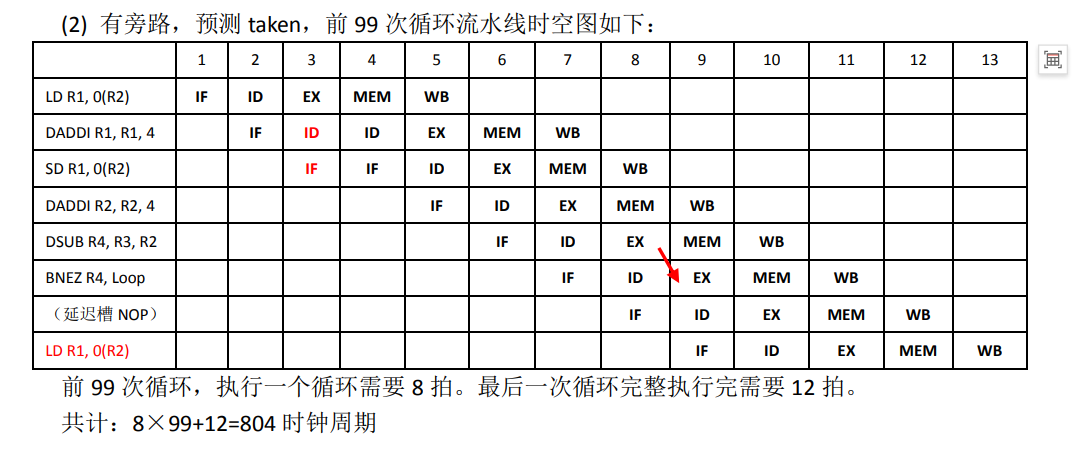
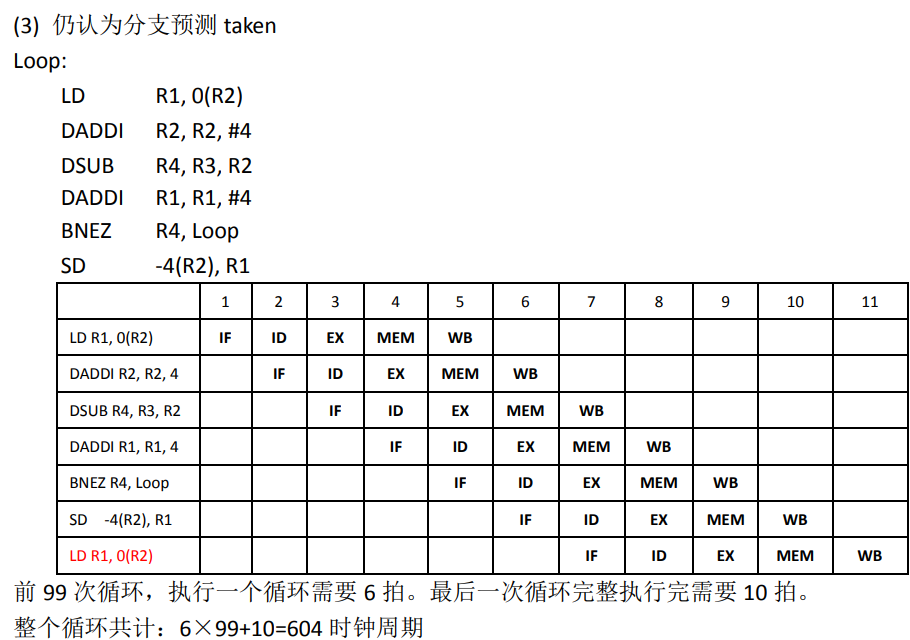
taken/not taken 策略
taken:默认会发生跳转,所以取指是取要跳转的指令
not taken:默认不会发生跳转,取下一条指令
例子