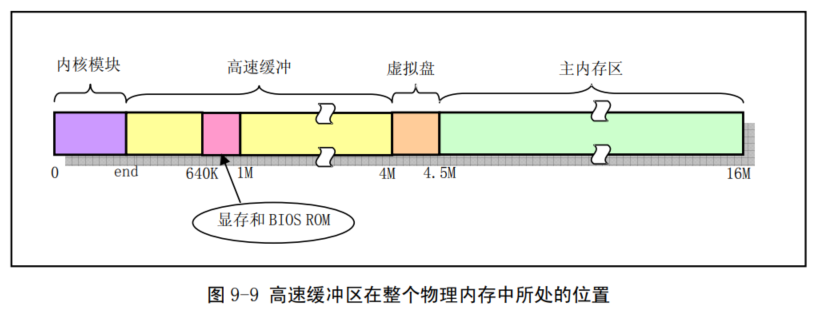
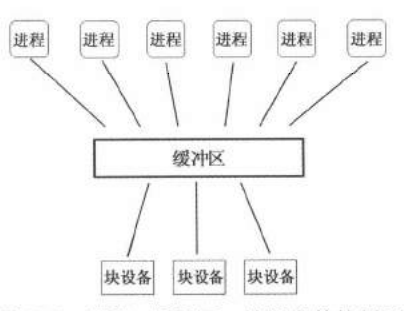
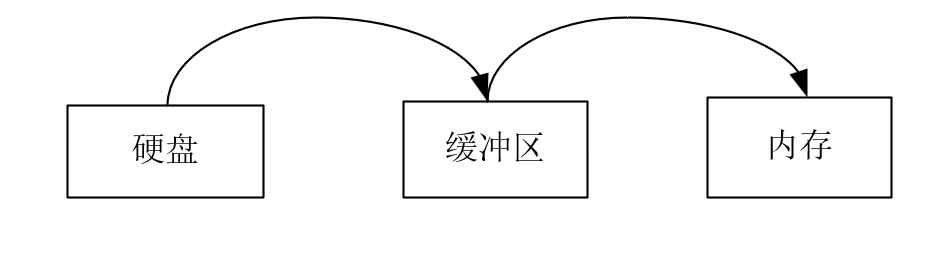
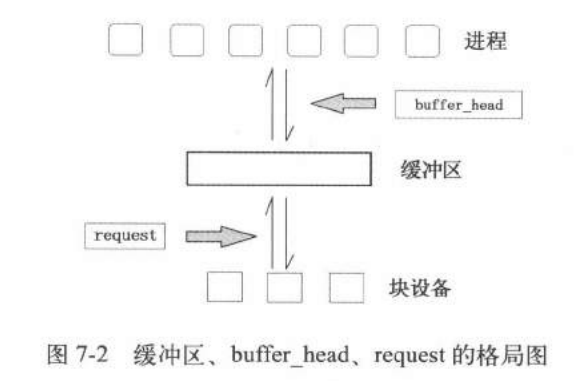
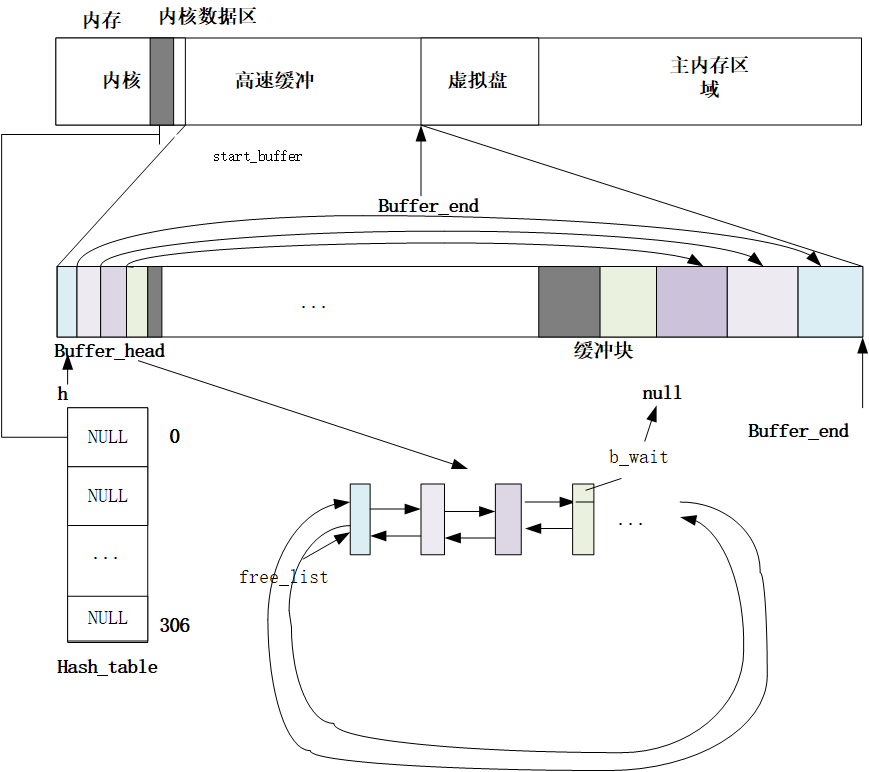
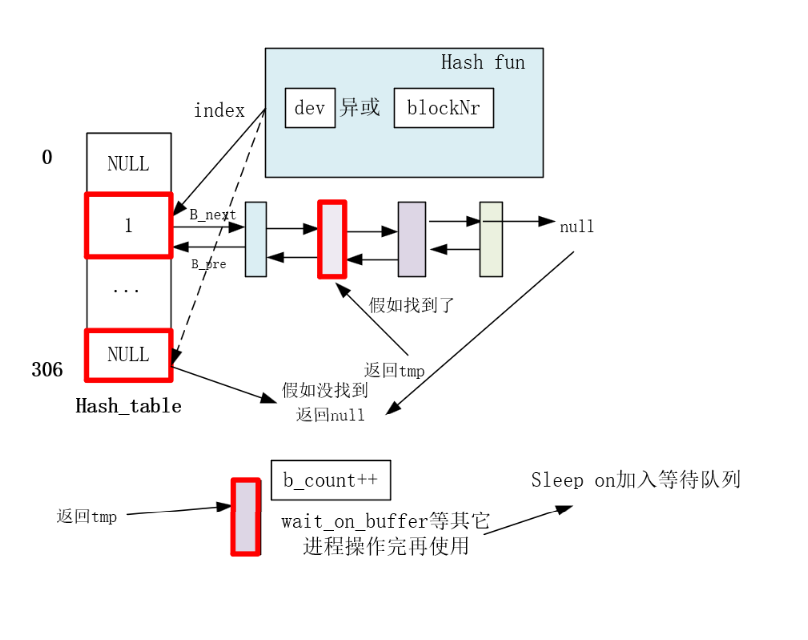
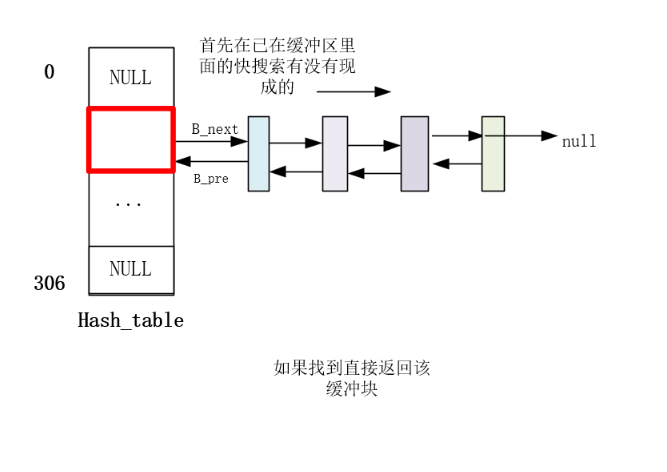
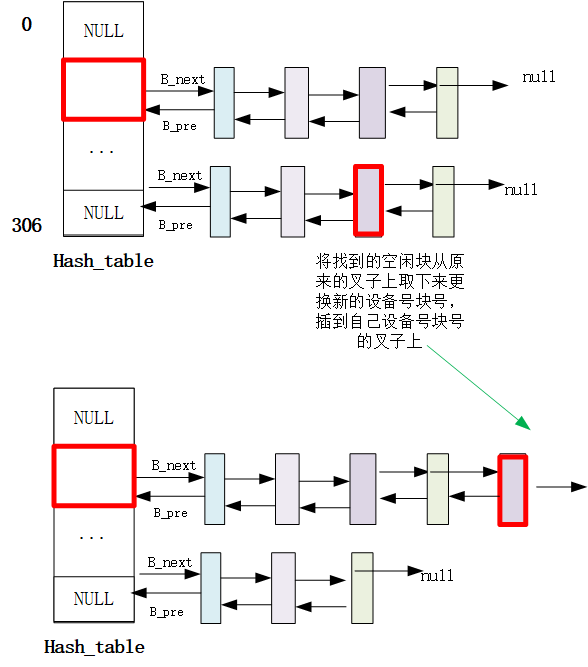
struct buffer_head * getblk(int dev,int block) { ... //终于申请到能用的缓冲块了,发现有好兄弟进程先自己一步找到了缓冲块并且加入了hash表里面,自己有白忙活了,只能去等好兄弟用完用他的缓冲块了。 if (find_buffer(dev,block)) goto repeat; /* OK, FINALLY we know that this buffer is the only one of it's kind, */ /* and that it's unused (b_count=0), unlocked (b_lock=0), and clean */ bh->b_count=1;//占用该缓冲块 bh->b_dirt=0;//还没有读盘dirt不置1 bh->b_uptodate=0; remove_from_queues(bh);//假设都满了就会在叉子上面摘下来,放到其他的设备号块号上面 bh->b_dev=dev;//更换设备号块号 bh->b_blocknr=block; //要把缓冲块叉在hash上面才算纳入了缓冲区的管理范围 insert_into_queues(bh);//重新插到合适的位置 return bh; }
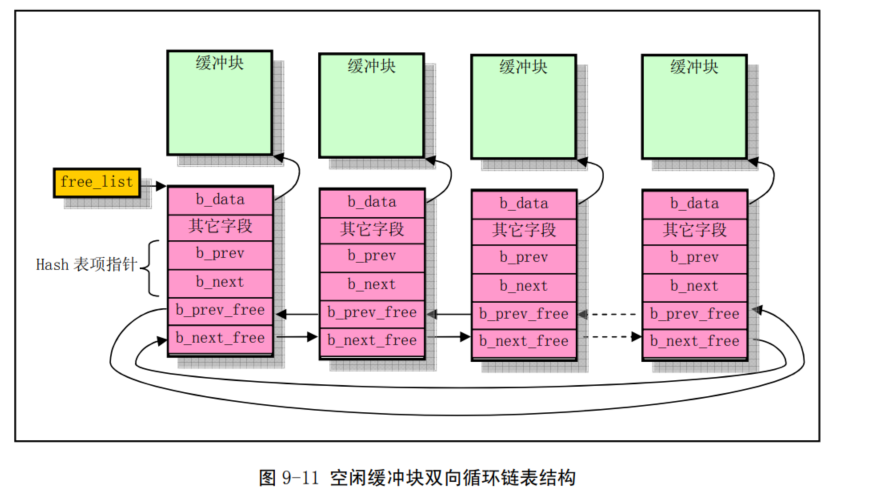
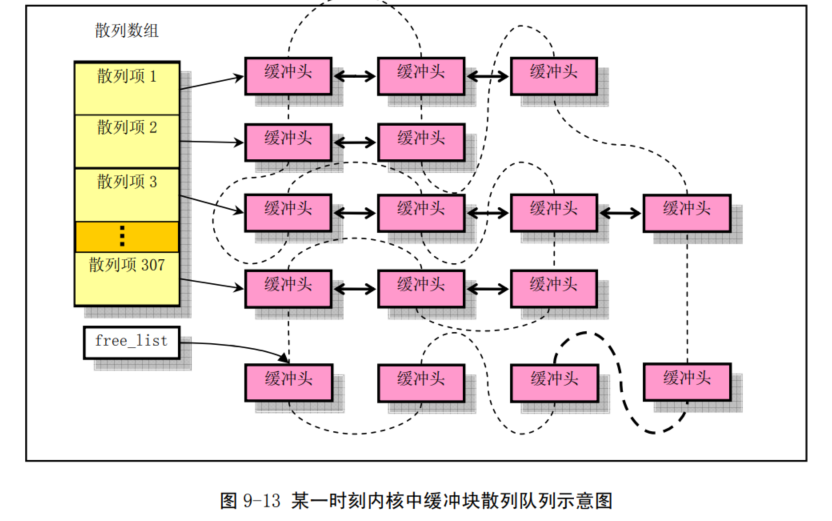
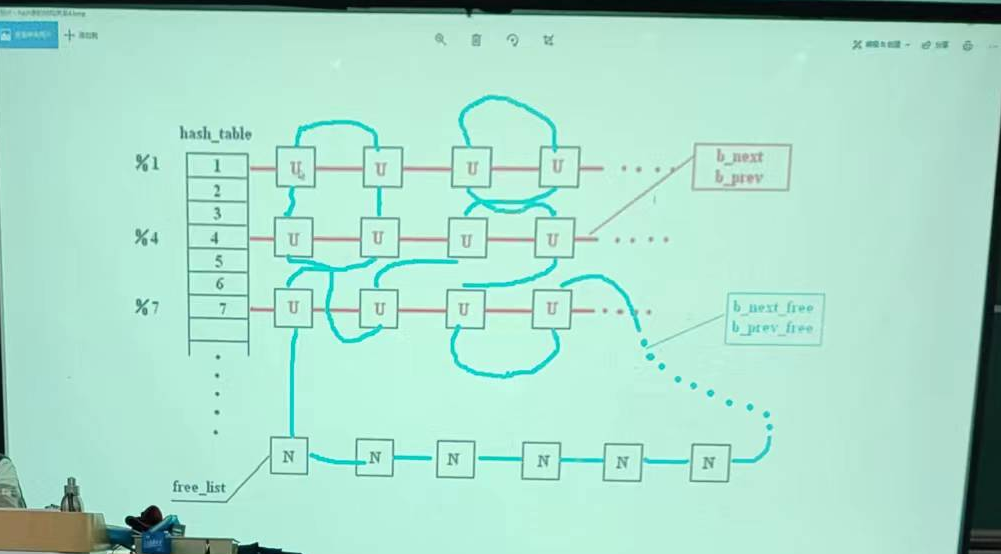
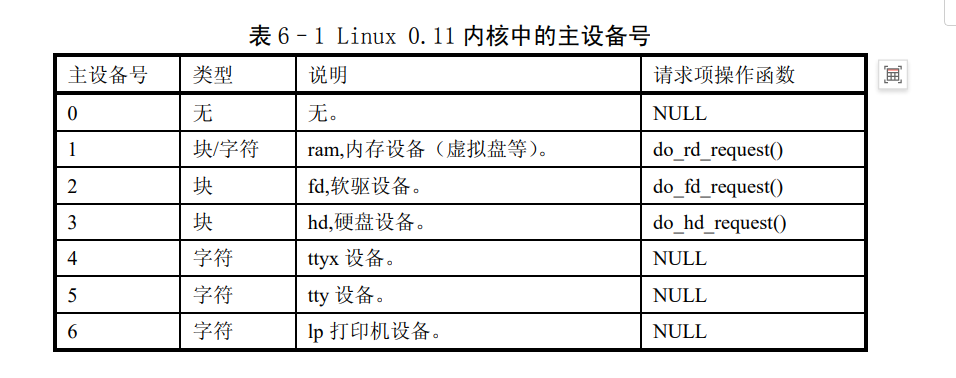
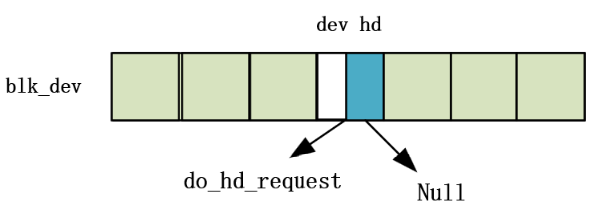
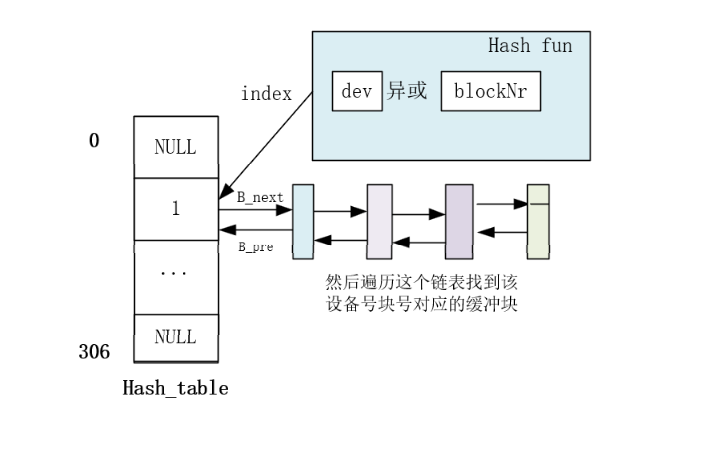
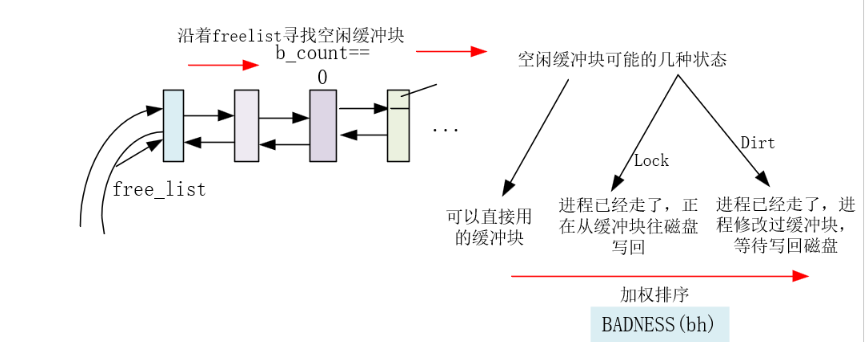
/* 从 hash 队列中移除缓冲块 */ staticinlinevoidremove_from_queues(struct buffer_head * bh) { /* remove from hash-queue */ //hash队列链表上删除结点,但是始终都在双向环链表上面 if (bh->b_next) bh->b_next->b_prev = bh->b_prev; if (bh->b_prev) bh->b_prev->b_next = bh->b_next; // 如果该缓冲区是该队列的头一个块,则让 hash 表的对应项指向本队列中的下一个缓冲区。 if (hash(bh->b_dev,bh->b_blocknr) == bh) hash(bh->b_dev,bh->b_blocknr) = bh->b_next; /* remove from free list */ /* 从空闲缓冲区的双向环链表中移除缓冲块 */ if (!(bh->b_prev_free) || !(bh->b_next_free)) panic("Free block list corrupted"); bh->b_prev_free->b_next_free = bh->b_next_free; bh->b_next_free->b_prev_free = bh->b_prev_free; if (free_list == bh) free_list = bh->b_next_free; }
insert_into_queues
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
//// 将指定缓冲区插入空闲链表尾并放入 hash 队列中。 staticinlinevoidinsert_into_queues(struct buffer_head * bh) { /* put at end of free list */ /* 放在空闲链表末尾处 */ bh->b_next_free = free_list; bh->b_prev_free = free_list->b_prev_free; free_list->b_prev_free->b_next_free = bh; free_list->b_prev_free = bh; /* put the buffer in new hash-queue if it has a device */ /* 如果该缓冲块对应一个设备,则将其插入新 hash 队列中,头插入 */ bh->b_prev = NULL; bh->b_next = NULL; if (!bh->b_dev) return; bh->b_next = hash(bh->b_dev,bh->b_blocknr); hash(bh->b_dev,bh->b_blocknr) = bh; bh->b_next->b_prev = bh; }