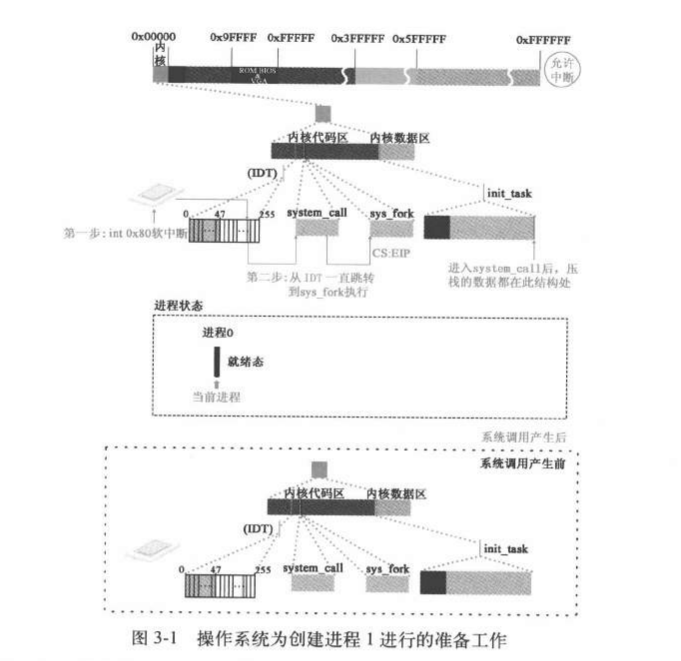
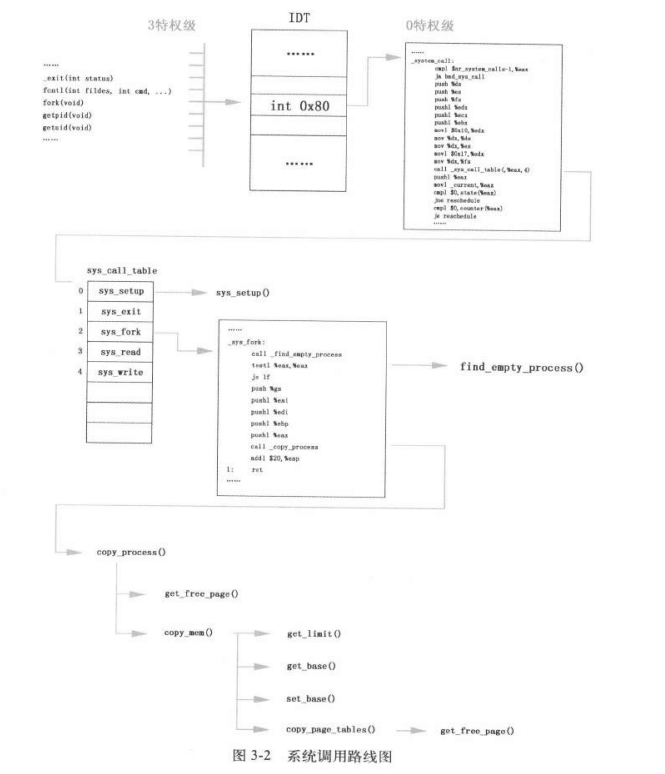
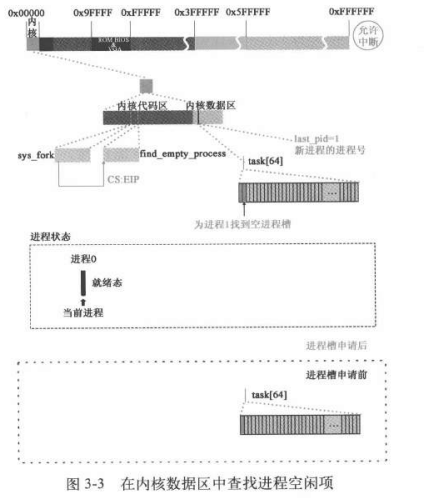
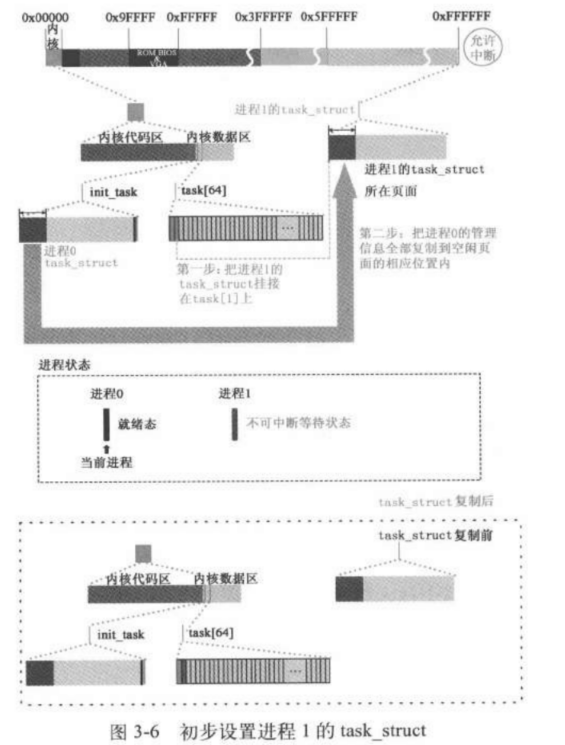
进程1的创建和运行与缓冲区相关操作
进程0创建进程1
在linux系统中所有进程都是基于父子进程创建机制,由父进程创建的。通过父进程调用fork函数实现
1 2 3 4 5 6 7 8 static inline _syscall0(int ,fork) void main (void ) {... if (!fork())init(); ... }
syscall0
执行fork函数实际是执行到unistd.h的syscall0():
image-20231021140609566
**_syscall0** 是一个宏定义,其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 #define _syscall0(type,name) \ type name(void) \ { \ long __res; \ __asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_##name)); \ if (__res >= 0) \ return (type) __res; \ errno = -__res; \ return -1; \ }
因此这里_syscall0(int,fork) 展开后是这样的:.
1 2 3 4 5 6 7 8 9 10 11 12 type fork (void ) \ { \ long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_fork)) ; \ if (__res >= 0 ) \ return (type) __res; \ errno = -__res; \ return -1 ; \}
__NR_fork=2,其实是描述了操作系统专用性的那几个函数,体现了操作系统的确定性。其定义了
fork 函数,其通过 0x80
中断进入系统调用。
在 Linux
内核中,每个系统调用都具有唯一的一个系统调用功能号。这些功能号定义在文件
include/unistd.h 中第 60 行开始处。例如,fork系统调用的功能号是
2,定义为符号 ___NR_fork 。这些系统调用功能号实际上对应于
include/linux/sys.h 中定义的系统调用处理程序指针数组表 sys_call_table[]
中项的索引值。因此 write() 系统调用的处理程序指针就位于该数组的项 2 处。
sys_call_table:
1 2 fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read, sys_write, ...(此处省略)) };
当应用程序经过库函数向内核发出一个中断调用 int 0x80
时,就开始执行一个系统调用。其中寄存器 eax
中存放着系统调用号,而携带的参数可依次存放在寄存器 ebx、ecx 和 edx
中。因此 Linux 0.11
内核中用户程序能够向内核最多直接传递三个参数,当然也可以不带参数。上面fork就是向内核传了一个参数,处理系统调用中断
int 0x80 的过程是程序 kernel/system_call.s 中的 system_call 。
调用流程:
image-20231021142821942
调用int
$0x80cpu从三特权级转到0特权级,硬件对ss,ESP,EFLAGS,CS,EIP进行压栈 ,压栈的EIP指向当前指令的下一行即if(__res>=0)这一行,这就是进程0从fork函数系统调用中断返回后执行的第一条指令位置。跳转到system_call执行:
system_call
system_call程序解读如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 _system_call: cmpl $nr_system_calls-1,%eax #判断是否越界了,系统调用一共72个(sys_call_table),eax 是传入参数,以fork为例传入的eax=2,是_NR_fork ja bad_sys_call #如果越界了则跳到越界代码,中断返回,返回eax的值为-1,以fork为例代表创建失败 push %ds #下面的6个push都是为了copy_process()的参数 push %es push %fs pushl %edx pushl %ecx # push %ebx,%ecx,%edx as parameters pushl %ebx # to the system call movl $0x10,%edx # set up ds,es to kernel space mov %dx,%ds mov %dx,%es movl $0x17,%edx # fs points to local data space mov %dx,%fs call _sys_call_table(,%eax,4) #通过查_sys_call_table确定要调用的函数,以fork为例,eax=2,这里就是 # call ( _sys_call_table+2*4),也就是_sys_fork的入口 pushl %eax movl _current,%eax cmpl $0,state(%eax) # state jne reschedule cmpl $0,counte
call _sys_call_table(,%eax,4)
#通过查_sys_call_table确定要调用的函数,以fork为例,eax=2,这里就是 call
(
_sys_call_table+2*4),偏移寻址,也就是_sys_fork的入口,因为sys_call_table的每一项都有四个字节,所有就是sys_call_table[2]
注意 :这里system_call函数还没执行完,因此调用sys_call_table会压栈保护现场,这里压栈体现在后面copy_process函数的第六个参数long
none
sys_fork
sys_fork 函数解析如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 _sys_fork: call _find_empty_process #调用找到空进程的函数 testl %eax,%eax #如果返回的是-EAGAIN说明已经有64个进程运行没有空进程 testl 是指令的名称, #它用于执行逻辑“与”操作。测试%eax中的值,将结果存储在标志寄存器中,而不更改%eax的值。如果%eax中的值为零 #那么零标志位(ZF)将被设置为1;否则,ZF将被清除为0。 js 1f #跳转到ret #1f 中的 1 表示标签的唯一标识符或编号。在某些汇编语言中,数字编号用于标识不同的标签,使程序员能够更容易地跟踪和管理它们。 # f 表示标签的类型。在汇编语言中,f 可能表示 "forward", # 表示这是一个向前跳转的标签。这意味着在程序执行期间,它将在后续的指令中使用,通常用于条件分支或循环的目标。 push %gs #这5个参数也作为copy_process的参数 pushl %esi pushl %edi pushl %ebp pushl %eax call _copy_process #调用赋值进程函数,这里call没有传参就是因为其实上面压栈的把参数压进去了 addl $20,%esp 1: ret
find_empty_process
在task[64]中为进程1申请空闲位置并获取进程号
sched_init()函数已经对task[64]除了o以外的项都清空了,这里调用函数得到的就是1,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #define EAGAIN 11 int find_empty_process (void ) { int i; repeat: if ((++last_pid)<0 ) last_pid=1 ; for (i=0 ; i<NR_TASKS ; i++) if (task[i] && task[i]->pid == last_pid) goto repeat; for (i=1 ; i<NR_TASKS ; i++) if (!task[i]) return i; return -EAGAIN; }
image-20231021194439886
copy_process
一个函数的参数不是由函数定义的,而是由函数定义以外的程序通过压栈的方式做出来的,是操作系统底层代码与应用层代码的差异之一。
call _copy_process #调用赋值进程函数,这里call没有传参就是因为其实上面压栈的把参数压进去了
输入参数的分析 :1 2 3 4 5 6 7 int copy_process (int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss)
gcc 编译器传参:进栈,在栈里面传参,从右到左压栈
long eip,long cs,long eflags,long esp,long ss是指发生init
0x80软中断的时候cpu硬件压栈的,EIP指向当前指令的下一行即if(__res>=0)这一行,这就是进程0从fork函数系统调用中断返回后执行的第一条指令位置,cs,是用户的代码段
long ebx,long ecx,long edx,long fs,long es,long ds在systemcall里面被压栈:
1 2 3 4 5 6 push %ds #下面的6个push都是为了copy_process()的参数 push %es push %fs pushl %edx pushl %ecx # push %ebx,%ecx,%edx as parameters pushl %ebx # to the system call
long none 是现场保护,是call_system_table
还没运行完没出栈
int nr,long ebp,long edi,long esi,long gs是sys_fork里面的压栈部分:
1 2 3 4 5 push %gs #这5个参数也作为copy_process的参数 pushl %esi pushl %edi pushl %ebp pushl %eax
eax是空闲进程号,对应nr
为进程1创建task_struct,将进程0的task_struct内容复制给1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int copy_process (int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) { struct task_struct *p ; int i; struct file *f ; p = (struct task_struct *) get_free_page(); if (!p) return -EAGAIN; task[nr] = p; ... }
get_free_page()算法是从主内存地址的高端向低端递进寻找,进程1是开机以来操作系统第一次在主内存申请空闲页面,因此是16M的最末端。
get_free_page()代码分析如下所示:
get_free_page get_free_page()函数用于在主内存区中申请一页空闲内存页,并返回物理内存页的起始地址。它首先
扫描内存页面字节图数组 mem_map[],寻找值是 0
的字节项(对应空闲页面)。若无则返回 0 结束,表
示物理内存已使用完。若找到值为 0 的字节,则将其置
1,并换算出对应空闲页面的起始地址。然后对
该内存页面作清零操作。最后返回该空闲页面的物理内存起始地址。
"std ; repne ; scasb\n\t"
std:这是 "set direction flag"
的缩写,用于设置字符串操作方向。在使用scasb等指令进行字符串操作时,方向标志的设置将影响字符串操作的方向。std
指令设置方向标志,使字符串操作向前(高地址到低地址)进行。通常,std
用于向后搜索或处理字符串。repne:这是 "repeat while not equal"
的缩写,通常与字符串操作指令一起使用,表示重复执行字符串操作,直到特定条件不再满足。在这种情况下,它可能与
scasb
一起使用,以重复执行比较操作,直到找到匹配的字节或直到遍历整个字符串。scasb:这是 "scan string, compare with byte"
的缩写,用于在字符串中扫描并比较字节。它通常与repne结合使用,以在字符串中搜索特定字节值,并在找到匹配值时停止搜索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 unsigned long get_free_page (void ) { register unsigned long __res asm ("ax" ) ;__asm__("std ; repne ; scasb\n\t" "jne 1f\n\t" "movb $1,1(%%edi)\n\t" "sall $12,%%ecx\n\t" "addl %2,%%ecx\n\t" "movl %%ecx,%%edx\n\t" "movl $1024,%%ecx\n\t" "leal 4092(%%edx),%%edi\n\t" "rep ; stosl\n\t" "movl %%edx,%%eax\n" "1:" :"=a" (__res) :"0" (0 ),"i" (LOW_MEM),"c" (PAGING_PAGES), "D" (mem_map+PAGING_PAGES-1 ) :"di" ,"cx" ,"dx" ); return __res; }
编译函数返回值一般是eax寄存器 >为啥是从高往低找空闲页?
让线性地址和物理地址之间的映射关系更加难以捉摸
>拿的是线性页还是物理页? >拿的页是0特权还是三特权
拿的是物理内存的页,16M的最后一个页
>为什么用父进程创建子进程而不是用模版的机制?
引导,子进程先共享父进程的代码 >父进程怎么没倒腾页表?
进程0和内核的代码是在一起的,段是重叠的,进程0用了一部分kernel的代码
子进程tss寄存器等设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 int copy_process (int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) { ... task[nr] = p; *p = *current; p->state = TASK_UNINTERRUPTIBLE; p->pid = last_pid; p->father = current->pid; p->counter = p->priority; p->signal = 0 ; p->alarm = 0 ; p->leader = 0 ; p->utime = p->stime = 0 ; p->cutime = p->cstime = 0 ; p->start_time = jiffies; p->tss.back_link = 0 ; p->tss.esp0 = PAGE_SIZE + (long ) p; p->tss.ss0 = 0x10 ; p->tss.eip = eip; p->tss.eflags = eflags; p->tss.eax = 0 ; p->tss.ecx = ecx; p->tss.edx = edx; p->tss.ebx = ebx; p->tss.esp = esp; p->tss.ebp = ebp; p->tss.esi = esi; p->tss.edi = edi; p->tss.es = es & 0xffff ; p->tss.cs = cs & 0xffff ; p->tss.ss = ss & 0xffff ; p->tss.ds = ds & 0xffff ; p->tss.fs = fs & 0xffff ; p->tss.gs = gs & 0xffff ; p->tss.ldt = _LDT(nr); p->tss.trace_bitmap = 0x80000000 ; if (last_task_used_math == current) __asm__("clts ; fnsave %0" ::"m" (p->tss.i387)); }
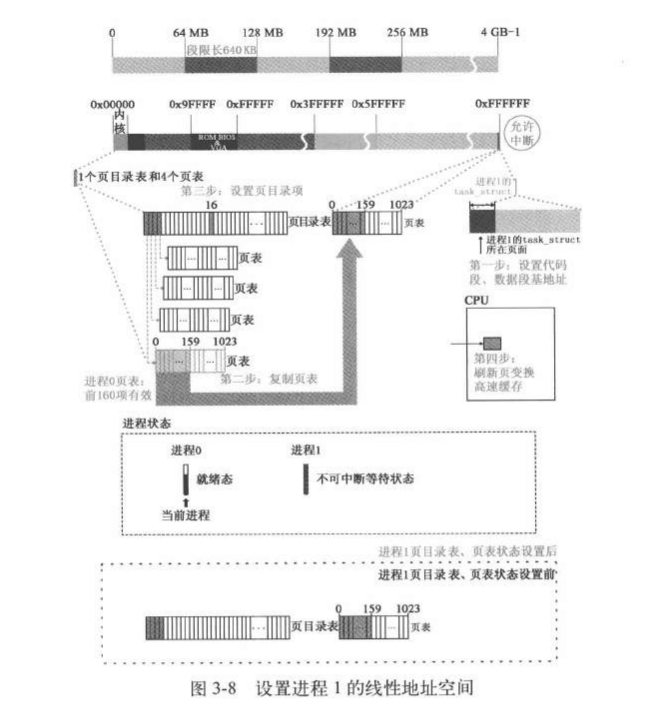
设置进程1的分页管理
4GB的空间 ,64个进程,4*1024 MB \(2^{12}/2^6=64\)
MB,进程段限长:0~0x9f:0xa0. 段限长 \(160\times4KB=640KB\)
image-20231025115927391
分页机制是基于保护模式的,访问控制是基于段的,不存在没有pe的pg。要设置进程1的分页,首先要设置进程1的分段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int copy_process (int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) { ... if (last_task_used_math == current) __asm__("clts ; fnsave %0" ::"m" (p->tss.i387)); if (copy_mem(nr,p)) { task[nr] = NULL ; free_page((long ) p); return -EAGAIN; } ... }
copy_mem
设置子进程的代码段,数据段及创建复制子进程的第一个页表
设置新的进程的代码段基址是nr*64MB,每个进程分配了64MB的线性地址空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int copy_mem (int nr,struct task_struct * p) { unsigned long old_data_base,new_data_base,data_limit; unsigned long old_code_base,new_code_base,code_limit; code_limit=get_limit(0x0f ); data_limit=get_limit(0x17 ); old_code_base = get_base(current->ldt[1 ]); old_data_base = get_base(current->ldt[2 ]); if (old_data_base != old_code_base) panic("We don't support separate I&D" ); if (data_limit < code_limit) panic("Bad data_limit" ); new_data_base = new_code_base = nr * 0x4000000 ; p->start_code = new_code_base; set_base(p->ldt[1 ],new_code_base); set_base(p->ldt[2 ],new_data_base); if (copy_page_tables(old_data_base,new_data_base,data_limit)) { free_page_tables(new_data_base,data_limit); return -ENOMEM; } return 0 ; }
求段基址和段限长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #define get_limit(segment) ({ \ unsigned long __limit; \ __asm__("lsll %1,%0\n\tincl %0" :"=r" (__limit):"r" (segment)); \ __limit;}) #define get_base(ldt) _get_base( ((char *)&(ldt)) ) #define _get_base(addr) ({\ unsigned long __base; \ __asm__("movb %3,%%dh\n\t" \ "movb %2,%%dl\n\t" \ "shll $16,%%edx\n\t" \ "movw %1,%%dx" \ :"=d" (__base) \ :"m" (*((addr)+2 )), \ "m" (*((addr)+4 )), \ "m" (*((addr)+7 ))); \ __base;})
copy_page_tables
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 int copy_page_tables (unsigned long from,unsigned long to,long size) { unsigned long * from_page_table; unsigned long * to_page_table; unsigned long this_page; unsigned long * from_dir, * to_dir; unsigned long nr; if ((from&0x3fffff ) || (to&0x3fffff )) panic("copy_page_tables called with wrong alignment" ); from_dir = (unsigned long *) ((from>>20 ) & 0xffc ); to_dir = (unsigned long *) ((to>>20 ) & 0xffc ); size = ((unsigned ) (size+0x3fffff )) >> 22 ; for ( ; size-->0 ; from_dir++,to_dir++) { if (1 & *to_dir) panic("copy_page_tables: already exist" ); if (!(1 & *from_dir)) continue ; from_page_table = (unsigned long *) (0xfffff000 & *from_dir); if (!(to_page_table = (unsigned long *) get_free_page())) return -1 ; *to_dir = ((unsigned long ) to_page_table) | 7 ; nr = (from==0 )?0xA0 :1024 ; for ( ; nr-- > 0 ; from_page_table++,to_page_table++) { this_page = *from_page_table; if (!(1 & this_page)) continue ; this_page &= ~2 ; *to_page_table = this_page; if (this_page > LOW_MEM) { *from_page_table = this_page; this_page -= LOW_MEM; this_page >>= 12 ; mem_map[this_page]++; } } } invalidate(); return 0 ; }
free_page_tables/free tables
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int free_page_tables (unsigned long from,unsigned long size) { unsigned long *pg_table; unsigned long * dir, nr; if (from & 0x3fffff ) panic("free_page_tables called with wrong alignment" ); if (!from) panic("Trying to free up swapper memory space" ); size = (size + 0x3fffff ) >> 22 ; dir = (unsigned long *) ((from>>20 ) & 0xffc ); for ( ; size-->0 ; dir++) { if (!(1 & *dir)) continue ; pg_table = (unsigned long *) (0xfffff000 & *dir); for (nr=0 ; nr<1024 ; nr++) { if (1 & *pg_table) free_page(0xfffff000 & *pg_table); *pg_table = 0 ; pg_table++; } free_page(0xfffff000 & *dir); *dir = 0 ; } invalidate(); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 void free_page (unsigned long addr) { if (addr < LOW_MEM) return ; if (addr >= HIGH_MEMORY) panic("trying to free nonexistent page" ); addr -= LOW_MEM; addr >>= 12 ; if (mem_map[addr]--) return ; mem_map[addr]=0 ; panic("trying to free free page" ); }
copy_process小结:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 int copy_process (int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) { struct task_struct *p ; int i; struct file *f ; p = (struct task_struct *) get_free_page(); if (!p) return -EAGAIN; task[nr] = p; *p = *current; p->state = TASK_UNINTERRUPTIBLE; p->pid = last_pid; ... if (last_task_used_math == current) __asm__("clts ; fnsave %0" ::"m" (p->tss.i387)); if (copy_mem(nr,p)) { task[nr] = NULL ; free_page((long ) p); return -EAGAIN; } for (i=0 ; i<NR_OPEN;i++) if (f=p->filp[i]) f->f_count++; if (current->pwd) current->pwd->i_count++; if (current->root) current->root->i_count++; if (current->executable) current->executable->i_count++; set_tss_desc(gdt+(nr<<1 )+FIRST_TSS_ENTRY,&(p->tss)); set_ldt_desc(gdt+(nr<<1 )+FIRST_LDT_ENTRY,&(p->ldt)); p->state = TASK_RUNNING; return last_pid; }
想要创建子进程主要包括以下几个阶段:
首先要挂号注册,相当于公安局上户口。这一步需要为进程1创建task_struct(其实和PCB的概念一样)。task_struct的内容复制进程0,并对进程1的task_struct,tss做个性化设置。注意,此时数据栈没有复制,这是因为两个进程代码可以是同一份,但是数据不能是同一个。此时用一个空闲页存放task_struct
和内核栈的共用体。
第二步要建立实体,因为此时虽然登记了,但是没有给子进程分配内存。一个程序要运行要完成取指执行的过程,因此必须要把代码加载到内存中。因此需要建立内存调用的机制,也就是要完善(线性地址和分页)段->逻辑(线性)地址,和逻辑(线性)地址->物理地址的映射关系。
这一部分由copy_mem函数完成。首先要维护线性地址,因此需要得到父进程代码段数据
段的基址和限长,这个基址存在于当前进程的ldt中给子进程分配新的代码段和数据段,系统设置给每个进程分配64M的虚拟内存空间,因此第nr个进程代码段和数据段的基址就是nr
*
0x4000000(因为linux0.11版本默认的虚拟空间是共用一个虚拟空间互不重叠的,这个在高版本是有所变化的。然后把设置好的基
址填到子进程的ldt中。至此就完成了段-线性地址的设置,下面设置分页。这里的策略是拷贝父进程的页表,也就是说子进程和父进程共享相同的页面,完成这个过程需要用到copy_page_tables函数进行操作。
copy_page_tables:
==先拷贝页目录表项再拷贝页表项==,这里子进程拥有自己的页表项,这里页表创建以后由于子进程的页面共享了父进程的页面,因此要把父进程的页表项内容复制给子进程的页表项。而页目录项的空间在分页机制建立的时候就已经建好了。这一个函数干的事情就是:填子进程的页目录项,页目录项需要指向的页表就从内存中申请页面把地址填进去,页表指向的页面就是父进程的页面。疑问:既然都是复制,为啥不直接复制父进程的页表(frame
页框)?因为那子进程就完全没有自主性了,也就是说进程的内存共享是页面的共享,但是页表项和页目录项是独立的。这样后面子进程想写入的时候可以copy
on write ,让页表指向新的页面。
这里为啥不用创建页目录表。因为低版本的linux是不同进程共用了一个虚拟空间
,所以是本来就有页目录表的,填进去就可以了,所以里不用创建。
进程1共享进程0的文件,设置进程1的GDT项
将进程1设置为就绪态,使得进程可以参与进程间的轮转。
几个小问题 :
一个进程线性地址空间:64M,最多页表:\(64/4=16个\)
(一个页表管理的空间是4K*1K=4M),那么实际物理内存就16M,可以填满64M的虚拟内存吗?答:可以填满,因为存在共享内存,可以一个物理地址映射到多个线性地址,这实际上就会涉及内存的装入装出问题)
问:为啥head.s设置分页的时候是+7 ,111(user r/w
p)。因为是进程0要用,必须是用户而不是su因此是7不是3
代码哪里体现进程不能访问页表的?
get free page 是物理的地址还是线性的地址?
线性地址。因为恒等映射看上去一样
为什么要用父进程创建子进程,共享了一部分父进程的的代码?因为此时子进程的代码还在磁盘里面,需要利用父进程的机制把子进程的代码加载进来子进程才能运行。
copy_process 后时代
_sys_fork
执行完copy_process return 返回到sys_fork
1 2 3 4 5 6 7 8 9 _sys_fork: push %gs #这5个参数也作为copy_process的参数 pushl %esi pushl %edi pushl %ebp pushl %eax call _copy_process #调用赋值进程函数,这里call没有传参就是因为其实上面压栈的把参数压进去了 addl $20,%esp #清栈,把上面push的那五个清理了。因为栈是从高到低生长的,入栈栈顶指针减小,出栈栈顶指针增加。注意:eax是4个字节,gs是两个字节,那为啥是20个字节,因为这里有字节对齐:align 2(2个字(4个字节)对齐)) 1: ret #目前还在0特权级,返回system call
_system_call
sys_fork
返回则返回到system_call,注意这里的sys_fork是通过call _sys_call_table调用的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 reschedule: pushl $ret_from_sys_call #先push再jmp其实就是call _schedule jmp _schedule _system_call: ... call _sys_call_table(,%eax,4) #通过查_sys_call_table确定要调用的函数,以fork为例,eax=2,这里就是 # call ( _sys_call_table+2*4),也就是_sys_fork的入口 pushl %eax #eax是函数的返回值,也就是sys_fork的返回值:last pid movl _current,%eax #把当前的子进程task_struct 复制给eax cmpl $0,state(%eax) # state 判断当前的子进程状态是不是就绪态0,不是的话可能当前进程时间片到了需要重新调度 jne reschedule #重新调度 cmpl $0,counter(%eax) # counter,检测时间片是否跑完 je reschedule#如果时间片跑完了重新调度 ret_from_sys_call: movl _current,%eax # task[0] cannot have signals cmpl _task,%eax #将task的首地址(task[0]的地址)和eax做比较,也就是判断当前进程是否为进程0 je 3f #如果是进程0,则直接跳转到下面的3执行 cmpw $0x0f,CS(%esp) # was old code segment supervisor ? ... 3: popl %eax # 将last pid 出栈给cpu的eax#将7个寄存器的值出栈给cpu ,对应前面push进来的七个值 popl %ebx popl %ecx popl %edx pop %fs pop %es pop %ds iret #中断返回,将cpu硬件在int 80中断压栈的ss esp eflags cs eip的值出栈给cpu对应的寄存器,此时cs:eip指向fork()中int 0x80的下一行 if(__res>=0)处执行
回到原点fork: if(__res>=0)
绕了一大圈,诸位可能都忘了我们从哪里进来的,进程0创建进程1调用了fork的宏展开,现在我们又回到了fork
1 2 3 4 5 6 7 8 9 10 11 12 type fork (void ) \ { \ long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_fork)) ; \ if (__res >= 0 ) \ return (type) __res; \ errno = -__res; \ return -1 ; \}
注意此处,res代表的就是eax::"=a" (__res),因此if (__res >= 0)判断eax是不是大于等于0.此时的eax就是上面popl的eax,也就是last
pid=1(进程1),所以这里是大于等于0的,所以fork返回last pid=1。
回到main
fork 返回值是last pid=1,也就是刚创建的子进程pid,这里!last
pid=0,因此跳到pause()函数中执行,这是一个死循环,因为如果不是死循环操作系统就退出了。进入pause就即将开始第一次进程调度过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void main (void ) { ... if (!fork()) { init(); } for (;;) pause(); }}
小结
:图解进程0创建进程1全过程
内核做第一次进程调度
在linux 0.11 进程调度机制中,发生进程切换存在两种情形:
image-20231106001422585
pause
上一小结说到,fork后,执行到了死循环里面的pause,pause和fork调用一样,也是syscall0的一个宏展开。
1 2 3 4 static inline _syscall0(int ,fork) static inline _syscall0(int ,pause)
1 2 3 4 5 6 7 8 9 10 11 12 type pause (void ) \ { \ long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_pause)) ; \ if (__res >= 0 ) \ return (type) __res; \ errno = -__res; \ return -1 ; \}
至此我们又跳回了熟悉的system_call
,下面的压栈过程和fork的时候如出一辙,只是在call _sys_call_table(,%eax,4)的时候出现差别,这里调用的是sys_pause。因为这里传入的eax是_NR_pause
1 2 3 4 5 6 7 _system_call: cmpl $nr_system_calls-1,%eax ja bad_sys_call #如果越界了则跳到越界代码,中断返回,返回eax的值为-1,以fork为例代表创建失败 push %ds #下面的6个push都是为了copy_process()的参数 ... call _sys_call_table(,%eax,4) #通过查_sys_call_table确定要调用的函数,以fork为例,eax=2,这里就是 ...
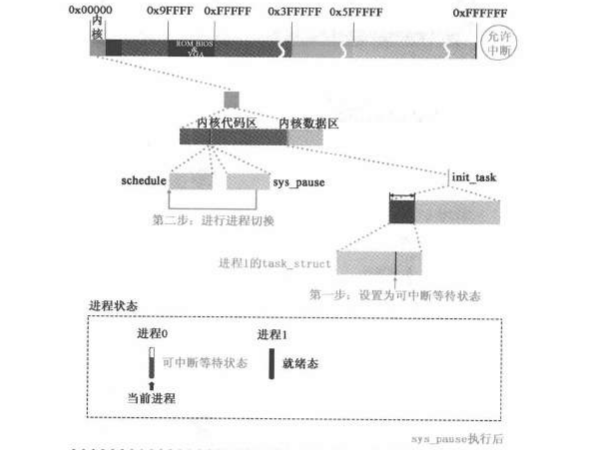
1 2 3 4 5 6 7 8 int sys_pause (void ) { current->state = TASK_INTERRUPTIBLE; schedule(); return 0 ; }
schedule
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 void schedule (void ) { int i,next,c; struct task_struct ** p ; for (p = &LAST_TASK ; p > &FIRST_TASK ; --p) if (*p) { if ((*p)->alarm && (*p)->alarm < jiffies) { (*p)->signal |= (1 <<(SIGALRM-1 )); (*p)->alarm = 0 ; } if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) && (*p)->state==TASK_INTERRUPTIBLE) (*p)->state=TASK_RUNNING; } while (1 ) { c = -1 ; next = 0 ; i = NR_TASKS; p = &task[NR_TASKS]; while (--i) { if (!*--p) continue ; if ((*p)->state == TASK_RUNNING && (*p)->counter > c) c = (*p)->counter, next = i; } if (c) break ; for (p = &LAST_TASK ; p > &FIRST_TASK ; --p) if (*p) (*p)->counter = ((*p)->counter >> 1 ) + (*p)->priority; } switch_to(next); }
switch_to
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 //这段代码属于内核态 #define switch_to(n) {\ struct {long a,b;} __tmp; \ __asm__("cmpl %%ecx,_current\n\t" \ // 任务 n 是当前任务吗?(current ==task[n]?) "je 1f\n\t" \ // 如果是当前任务,则什么都不做,退出。 "movw %%dx,%1\n\t" \ //把edx的里面的tss复制给tmp.b也就是基址,把edx低16位给b,也就是把cs赋值给b //这里1%是tmp.b存放tss的段选择子,也就是基址。其中tss任务切换的时候偏移就是0,所以不用给tmp.a赋值,初始化的时候就是0 "xchgl %%ecx,_current\n\t" \ //交换把目标进程里面tss保存的东西恢复 // current = task[n];ecx = 被切换出的任务。 //上面是进程0的内核态,ljmp以后就跑到了进程1.注意此时进程0还没跑完,还挂着呢,切换以后到res跑到三特权的进程1运行了 "ljmp %0\n\t" \ // 执行长跳转至*&__tmp,造成任务切换。 //因此这里偏移是0,不是要跳到tss数据段执行,而是要让tss段东西恢复当前进程状态 //ljmp以后后面的代码段就不执行了,要看tss里面的eip指向的是哪里就执行哪里,此时task0 的栈没清理 //这里的ljmp不是一个简单的跳转,是一个进程切换的机制,要参考IA32手册。先保存进程0的状态,保存在tss0里面,然后再恢复tss1 //那后面这几条语句什么时候执行? 的切回进程0的时候才继续跑。 //进程1eip跳哪里去了? 在copy process里面有eip,保存的位置是 init80 压入的syscall0的if( res__>=0) //此时已经走了两次init80 ,一个是fork 一个是pause 这里的init 80 是fork的时候存入的,现在它的res是0,因为copy process里面存的eax=0 所以res=0 "cmpl %%ecx,_last_task_used_math\n\t" \ // 新任务上次使用过协处理器吗? "jne 1f\n\t" \ // 没有则跳转,退出。 "clts\n" \ // 新任务上次使用过协处理器,则清 cr0 的 TS 标志。 "1:" \ ::"m" (*&__tmp.a),"m" (*&__tmp.b), \ //一个是段选择子(b是段选择子),一个是偏移(a是偏移),任务门切换只需要跳到新的tss段就可,不需要偏移 "d" (_TSS(n)),"c" ((long) task[n])); \ //在进程切换走的时候,当前进程的状态保存在了tss(n)里面,edx保存了tss n的索引号 //因此在切回来的时候,tss段里面有当前的进程状态。 }
tss_n:
tss位于gdt中的第四项,其中每项8字节,所以(FIRST_TSS_ENTRY<<3)
,每个进程tss+ldt16个字节,所以第n个进程在gdt表中的相对第0个tss的偏移量:(((unsigned long) n)<<4)
,由于这个段选择子是0特权+gdt后三位是0,不用改,所以段选择子就是长这样了。
1 2 3 #define FIRST_TSS_ENTRY 4 #define FIRST_LDT_ENTRY (FIRST_TSS_ENTRY+1) #define _TSS(n) ((((unsigned long) n)<<4)+(FIRST_TSS_ENTRY<<3))
轮转到进程1执行
进程1的eip在tss初始化的时候由进程0进程赋值,因此切换到进程1时,程序跳转到fork结束后的if (__res >= 0)处执行,此时的eax是在父进程创建子进程的时候,copy
process个性化设置tss的时候赋值的
1 2 3 4 5 6 7 8 9 10 11 12 type fork (void ) \ { \ long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_fork)) ; \ if (__res >= 0 ) \ return (type) __res; \ errno = -__res; \ return -1 ; \}
1 2 p->tss.eax = 0 ; p->tss.ecx = ecx;
因此res=0,fork的返回值是0
因此回到main函数中!fork()为真,因此下一步就开始执行init
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void main (void ) { ... if (!fork()) { init(); } ... }
init
setup
1 2 3 4 5 6 7 8 void init (void ) { int pid,i; setup((void *) &drive_info); ... }
首先调用setup函数
setup不是通过syscall0而是通过syscall1实现的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static inline _syscall1(int ,setup,void *,BIOS) #define _syscall1(type,name,atype,a) \ type name(atype a) \ { \ long __res; \ __asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_##name),"b" ((long)(a))); \ if (__res >= 0) \ return (type) __res; \ errno = -__res; \ return -1; \ }
因此这里展开就是:
1 2 3 4 5 6 7 8 9 10 11 int setup (void * BIOS) \{ \ long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_setup),"b" ((long )(a))) ; \if (__res >= 0 ) \ return (type) __res; \ errno = -__res; \ return -1 ; \}
运行时依旧会调用init 0x80 ,
__system_call,call_sys_table(,%eax,4),最后调用到sys_setup
注意:进程0 pause函数的init
0x80中断还没有返回,而setup又产生了·一个中断
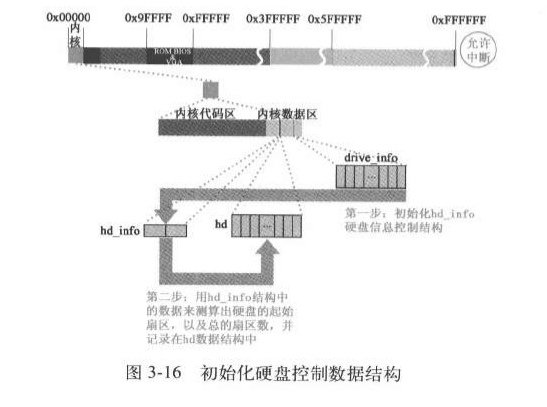
进程1设置硬盘的hd_info
根据机器系统数据中的drive_info 设置内核hd_info
image-20231111154453412
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 int sys_setup (void * BIOS) { static int callable = 1 ; int i,drive; unsigned char cmos_disks; struct partition *p ; struct buffer_head * bh ; if (!callable) return -1 ; callable = 0 ; #ifndef HD_TYPE for (drive=0 ; drive<2 ; drive++) { hd_info[drive].cyl = *(unsigned short *) BIOS; hd_info[drive].head = *(unsigned char *) (2 +BIOS); hd_info[drive].wpcom = *(unsigned short *) (5 +BIOS); hd_info[drive].ctl = *(unsigned char *) (8 +BIOS); hd_info[drive].lzone = *(unsigned short *) (12 +BIOS); hd_info[drive].sect = *(unsigned char *) (14 +BIOS); BIOS += 16 ; } if (hd_info[1 ].cyl) NR_HD=2 ; else NR_HD=1 ; #endif for (i=0 ; i<NR_HD ; i++) { hd[i*5 ].start_sect = 0 ; hd[i*5 ].nr_sects = hd_info[i].head* hd_info[i].sect*hd_info[i].cyl; } if ((cmos_disks = CMOS_READ(0x12 )) & 0xf0 ) if (cmos_disks & 0x0f ) NR_HD = 2 ; else NR_HD = 1 ; else NR_HD = 0 ; for (i = NR_HD ; i < 2 ; i++) { hd[i*5 ].start_sect = 0 ; hd[i*5 ].nr_sects = 0 ; } for (drive=0 ; drive<NR_HD ; drive++) { if (!(bh = bread(0x300 + drive*5 ,0 ))) { printk("Unable to read partition table of drive %d\n\r" , drive); panic("" ); } .... }
读取硬盘的引导块到缓冲区
在linux0.11中,硬盘最基础的信息就是分区表,其它信息都可以从这个信息引导出来,这个信息所在的块就是引导块。一块硬盘只有唯一的一个引导块(0号逻辑盘)。引导块有两个扇区,真正有用的是第一个扇区。bread函数实现读取引导快到缓冲区
1 2 3 4 5 6 7 8 9 10 11 int sys_setup (void * BIOS) { ... for (drive=0 ; drive<NR_HD ; drive++) { if (!(bh = bread(0x300 + drive*5 ,0 ))) { printk("Unable to read partition table of drive %d\n\r" , drive); panic("" ); } ... }
数量级关系
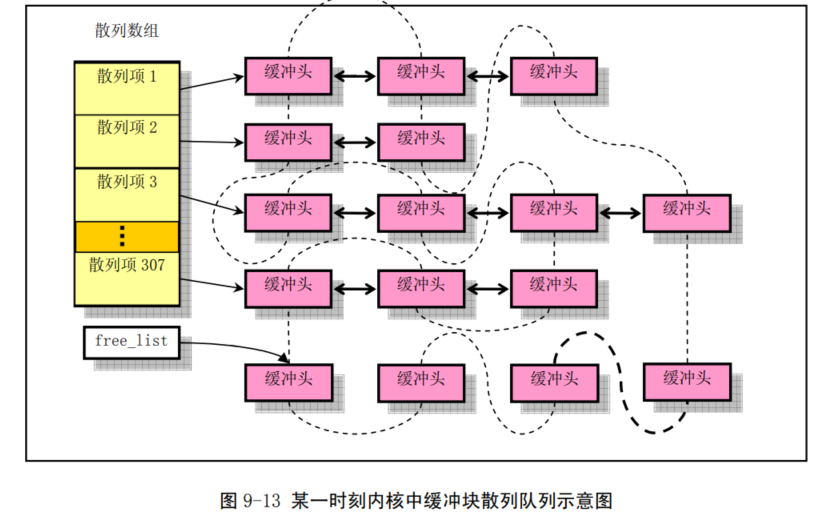
一般hash数据结构数组比链表快一个数量级左右所以307个哈希块,每个后面串10个,一共是3000多个buffer块。
为啥是307?缓冲区和硬盘的速度差了两个量级。缓冲区3000多对应请求项32.缓冲区对应缓冲区到用户进程的东西,request负责缓冲区到硬盘,速度差了两个数量级
1 2 3 4 5 6 #define NR_HASH 307 #define NR_BUFFERS nr_buffers #define _hashfn(dev,block) (((unsigned)(dev^block))%NR_HASH) #define hash(dev,block) hash_table[_hashfn(dev,block)]
缓冲区
初始化在上一章节中做过: 缓冲区初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct buffer_head { char * b_data; unsigned long b_blocknr; unsigned short b_dev; unsigned char b_uptodate; unsigned char b_dirt; unsigned char b_count; unsigned char b_lock; struct task_struct * b_wait ; struct buffer_head * b_prev ; struct buffer_head * b_next ; struct buffer_head * b_prev_free ; struct buffer_head * b_next_free ; };
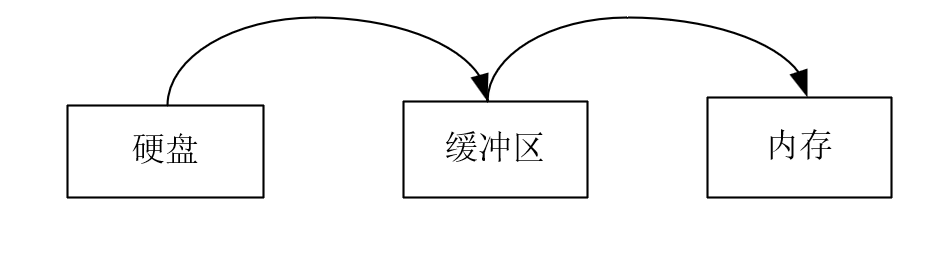
缓冲区:开一块内存,磁盘内容先读到缓冲区,在缓冲区读到内存
//怎么设计缓冲区才能重复使用。
为啥使用缓冲区快:存在重复读写的时候变快,有点像catche
怎么设计缓冲区才能满足重复使用,使得读写变快?
思路:缓冲区的数据一旦进了缓冲区就尽可能呆在缓冲区时间长:怎么设计
如果counter=0且没有新的请求或者缓冲区没满,那么这个conuter的buffer
head还得在缓冲区里面放着,满足在缓冲区时间长
如果缓冲区满了,有新的请求,则把counter=0的挪出去,把新的加进来
如果缓冲区满了,没有counter=0的,有新的请求,则新的请求等待。
前提:从内存读比从磁盘读快200倍
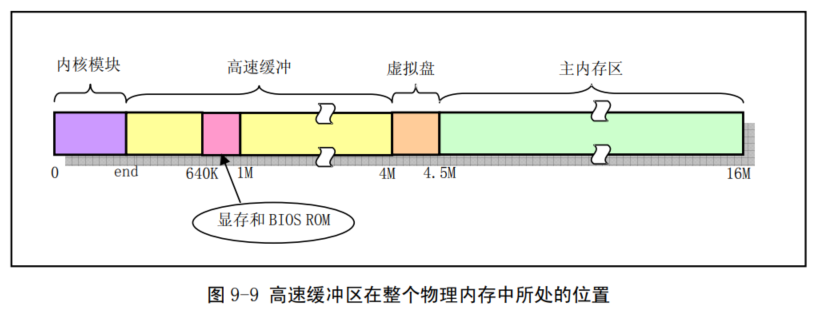
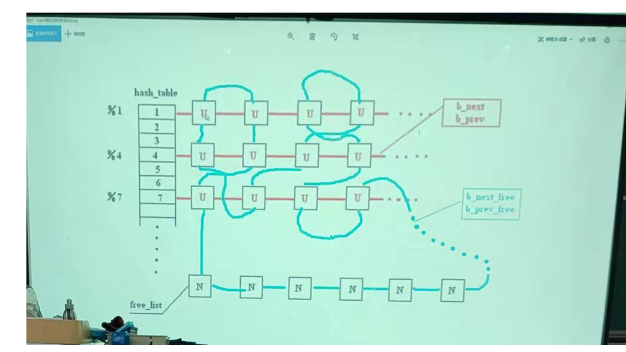
缓冲区:高速缓冲区位于内核代码块和主内存区之间
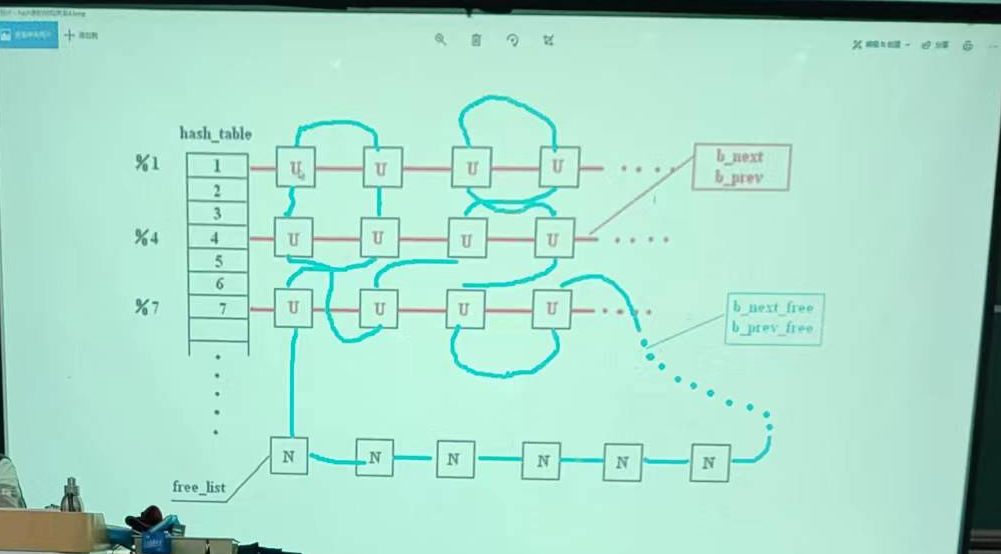
image-20231115095947238
整个高速缓冲区被划分成 1024
字节大小的缓冲块,正好与块设备上的磁盘逻辑块大小相同。高速缓冲采用 hash
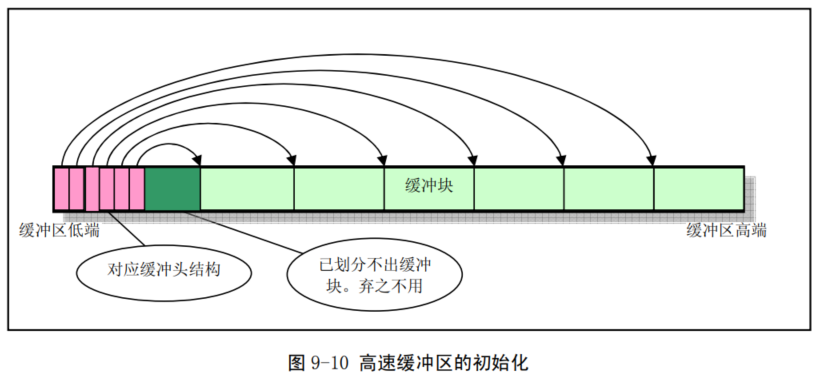
表和空闲缓冲块队列进行操作管理。在缓冲区初始化过程中,从缓冲区的两端开始,同时分别设置缓冲块头结构和划分出对应的缓冲块。缓冲区的高端被划分成一个个
1024 字节的缓冲块,低端则 分别建立起对应各缓冲块的缓冲头结构
buffer_head,用于描述对应缓冲块的
属性和把所有缓冲头连接成链表。直到它们之间已经不能再划分出缓冲块为止。
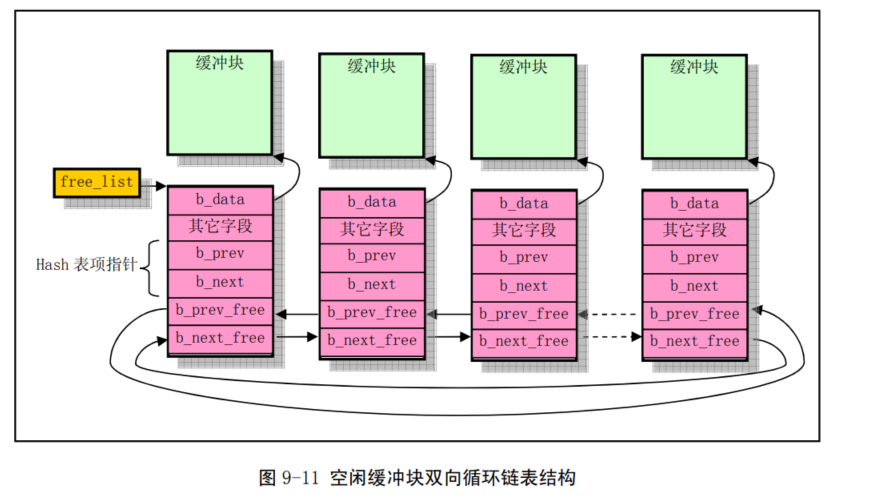
buffer_head 被链接成一个空闲缓冲块双向链表结构。
image-20231115101114916
为了能够快速地在缓冲区中寻找请求的数据块是否已经被读入到缓冲区中,buffer.c
程序使用了具有307 个 buffer_head 指针项的==hash 表结构==。上图中
buffer_head 结构的指针 b_prev、b_next 就是用于
hash表中散列在同一项上多个缓冲块之间的双向连接。Hash
表所使用的散列函数由==设备号和逻辑块号组合而成==。程序中使用的具体函数是:==(设备号^逻辑块号)
Mod 307==。
什么是哈希表
image-20231115101151894
image-20231120095719241
bread
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct buffer_head * bread (int dev,int block) { struct buffer_head * bh ; if (!(bh=getblk(dev,block))) panic("bread: getblk returned NULL\n" ); if (bh->b_uptodate) return bh; ll_rw_block(READ,bh); wait_on_buffer(bh); if (bh->b_uptodate) return bh; brelse(bh); return NULL ; }
getblk
缓冲块搜索函数 getblk(),以获取适合的缓冲块。该函数首先 调用
get_hash_table()函数,在 hash
表队列中搜索指定设备号和逻辑块号的缓冲块是否已经存在。如果存在就立刻返回对应缓冲头结构的指针;
1 2 3 4 5 6 7 8 9 struct buffer_head * getblk (int dev,int block) { struct buffer_head * tmp , * bh ; repeat: if (bh = get_hash_table(dev,block)) return bh; ... }
如果不存在,则从空闲链表头开始,对空闲链表进行扫描,寻找
一个空闲缓冲块。在寻找过程中还要对找到的空闲缓冲块作比较,根据赋予修改标志和锁定标志组合而成的权值,比较哪个空闲块最适合。若找到的空闲块既没有被修改也没有被锁定,就不用继续寻找了。
这里的dirt指的是进程方向的,dirt=1指的是进程修改了缓冲块,还没有写到硬盘中,而update是硬盘方向的,update=1指的是硬盘刷新过的缓冲块,数据已经读入内存。dirt和lock的区别体现在,lock是指缓冲块正在同步(正在写入硬盘),而dirt还不知道什么时候写,所以相比之下,dirt位比lock位更加的不好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #define BADNESS(bh) (((bh)->b_dirt<<1)+(bh)-> b_lock) static struct buffer_head * free_list ;struct buffer_head * getblk (int dev,int block) { ... tmp = free_list; do { if (tmp->b_count) continue ; if (!bh || BADNESS(tmp)<BADNESS(bh)) { bh = tmp; if (!BADNESS(tmp)) break ; } } while ((tmp = tmp->b_next_free) != free_list); if (!bh) { sleep_on(&buffer_wait); goto repeat; } ... }
若没有找到空闲块,则让当前进程进入睡眠状态,待继续执行时再次寻找。若该空闲块被锁定,则进程也需进入睡眠,等待其它进程解锁。
若在睡眠等待的过程中,该缓冲块又被其它进程占用,那么只要再
重头开始搜索缓冲块。
1 2 3 wait_on_buffer(bh); if (bh->b_count) goto repeat;
否则判断该缓冲块是否已被修改过,若是,则将该块写盘,并等待该块解锁。此
时如果该缓冲块又被别的进程占用,那么又一次全功尽弃,只好再重头开始执行
getblk()。
1 2 3 4 5 6 7 while (bh->b_dirt) { sync_dev(bh->b_dev); wait_on_buffer(bh); if (bh->b_count) goto repeat; }
在经历了以上
折腾后,此时有可能出现另外一个意外情况,也就是在我们睡眠时,可能其它进程已经将我们所需要的
缓冲块加进了 hash 队列中,因此这里需要最后一次搜索一下 hash
队列。如果真的在 hash 队列中找到了
我们所需要的缓冲块,那么我们又得对找到的缓冲块进行以上判断处理,因此,又一次需要重头开始执
行
getblk()。最后,我们才算找到了一块没有被进程使用、没有被上锁,而且是干净(修改标志未置位)
的空闲缓冲块。于是我们就将该块的引用次数置
1,并复位其它几个标志,然后从空闲表中移出该块的
缓冲头结构。在设置了该缓冲块所属的设备号和相应的逻辑号后,在将其放入
hash 表对应表项的第一个
和空闲队列的末尾处。最终,返回该缓冲块头的指针。
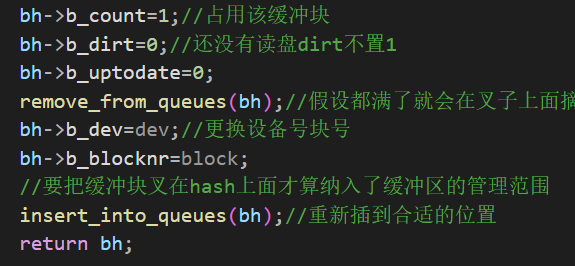
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct buffer_head * getblk (int dev,int block) { ... if (find_buffer(dev,block)) goto repeat; bh->b_count=1 ; bh->b_dirt=0 ; bh->b_uptodate=0 ; remove_from_queues(bh); bh->b_dev=dev; bh->b_blocknr=block; insert_into_queues(bh); return bh; }
get_hash_table
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct buffer_head * get_hash_table (int dev, int block) { struct buffer_head * bh ; for (;;) { if (!(bh=find_buffer(dev,block))) return NULL ; bh->b_count++; wait_on_buffer(bh); if (bh->b_dev == dev && bh->b_blocknr == block) return bh; bh->b_count--; } }
一些同步加锁等待函数解析
加锁
1 2 3 4 5 6 7 8 9 static inline void lock_buffer (struct buffer_head * bh) { cli(); while (bh->b_lock) sleep_on(&bh->b_wait); bh->b_lock=1 ; sti(); }
等待缓冲区
1 2 3 4 5 6 7 8 9 static inline void wait_on_buffer (struct buffer_head * bh) { cli(); while (bh->b_lock) sleep_on(&bh->b_wait); sti(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int sys_sync (void ) { int i; struct buffer_head * bh ; sync_inodes(); bh = start_buffer; for (i=0 ; i<NR_BUFFERS ; i++,bh++) { wait_on_buffer(bh); if (bh->b_dirt) ll_rw_block(WRITE,bh); } return 0 ; }
remove_from_queues
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static inline void remove_from_queues (struct buffer_head * bh) { if (bh->b_next) bh->b_next->b_prev = bh->b_prev; if (bh->b_prev) bh->b_prev->b_next = bh->b_next; if (hash(bh->b_dev,bh->b_blocknr) == bh) hash(bh->b_dev,bh->b_blocknr) = bh->b_next; if (!(bh->b_prev_free) || !(bh->b_next_free)) panic("Free block list corrupted" ); bh->b_prev_free->b_next_free = bh->b_next_free; bh->b_next_free->b_prev_free = bh->b_prev_free; if (free_list == bh) free_list = bh->b_next_free; }
insert_into_queues
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static inline void insert_into_queues (struct buffer_head * bh) { bh->b_next_free = free_list; bh->b_prev_free = free_list->b_prev_free; free_list->b_prev_free->b_next_free = bh; free_list->b_prev_free = bh; bh->b_prev = NULL ; bh->b_next = NULL ; if (!bh->b_dev) return ; bh->b_next = hash(bh->b_dev,bh->b_blocknr); hash(bh->b_dev,bh->b_blocknr) = bh; bh->b_next->b_prev = bh; }
ll_rw_block
ll底层的读写块操作
blk.h:
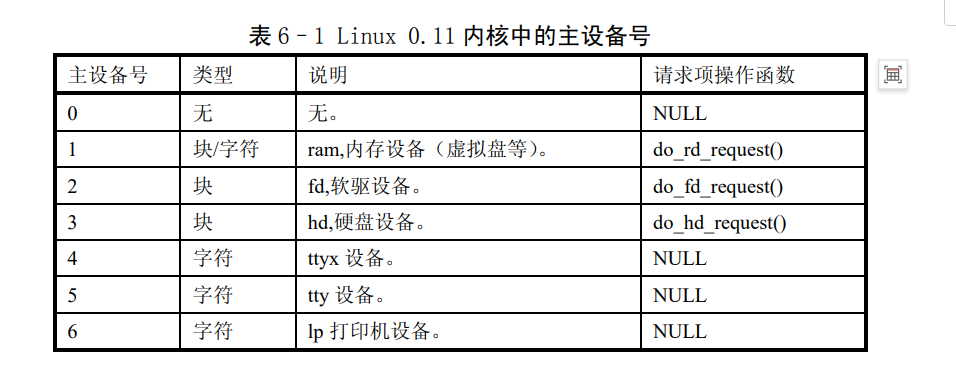
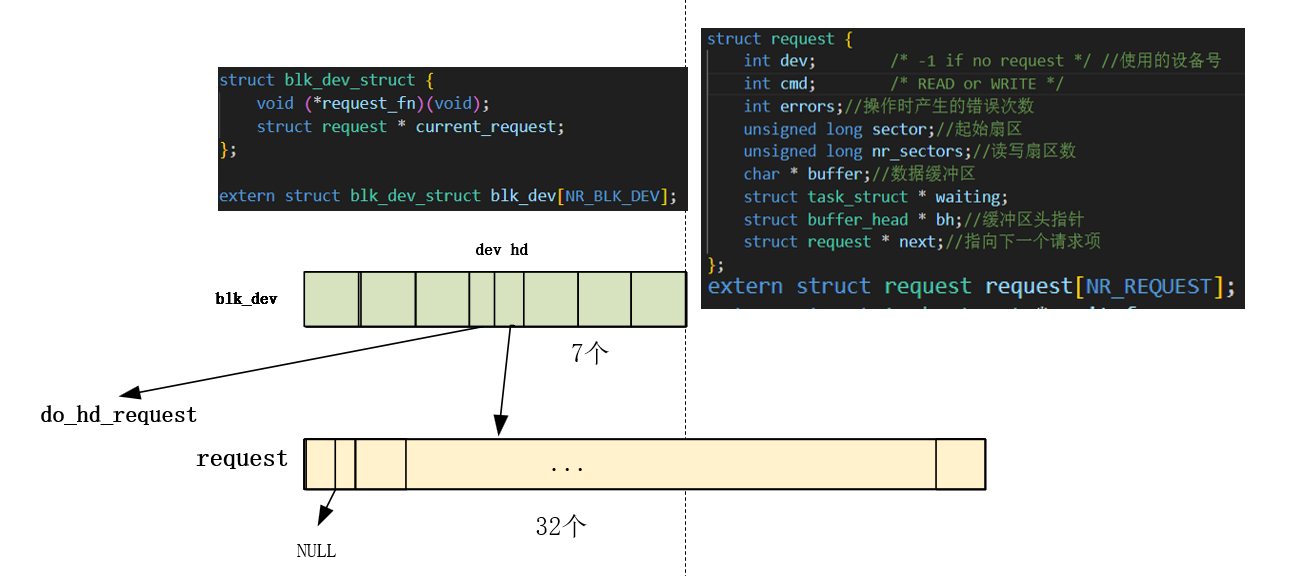
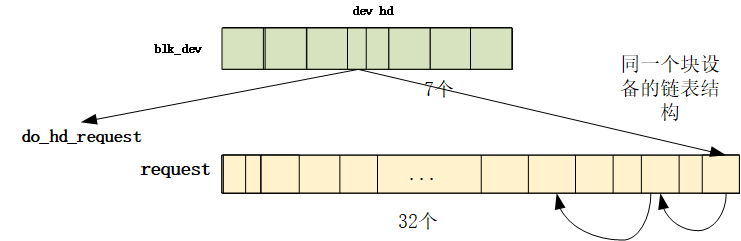
\#define NR_BLK_DEV 7
系统管理外设的重要数据结构:对于各种块设备,内核使用了一张块设备表
blk_dev[]来进行管理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct blk_dev_struct { void (*request_fn)(void ); struct request * current_request ; }; struct blk_dev_struct blk_dev [NR_BLK_DEV ] = { NULL , NULL }, { NULL , NULL }, { NULL , NULL }, { NULL , NULL }, { NULL , NULL }, { NULL , NULL }, { NULL , NULL } };
image-20231120112732685
1 2 3 4 5 6 7 8 9 10 11 12 13 void ll_rw_block (int rw, struct buffer_head * bh) { unsigned int major; if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV ||!(blk_dev[major].request_fn)) { printk("Trying to read nonexistent block-device\n\r" ); return ; } make_request(major,rw,bh); }
if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV ||!(blk_dev[major].request_fn))
这段的条件解析:或条件,说明两个满足一个就会报错试图读不存在的块设备
(major=MAJOR(bh->b_dev)) >= NR_BLK_DEV
#define MAJOR(a) (((unsigned)(a))>>8)右移8位取高字节(主设备号)。
将bh->b_dev主设备号是0~6,NR_BLK_DEV是7,大于说明不存在。
!(blk_dev[major].request_fn)
blk_dev[major].request
在hd_init里面做了初始化,挂载了请求项函数:do_hd_request
1 2 3 4 5 6 7 8 #define DEVICE_REQUEST do_hd_request void hd_init (void ) { blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST; ... }
这里的判断语句是指如果没有初始化,对应的就是上面表里面的NULL,!null为真,就会报错
挂载的另一个request*也在之前做过初始化:
1 2 3 4 5 6 7 8 9 void blk_dev_init (void ) { int i; for (i=0 ; i<NR_REQUEST ; i++) { request[i].dev = -1 ; request[i].next = NULL ; } }
一个是七个blk_dev的一个是32个的request(是一个数组链表)
image-20231122092315542
make_request
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 static void make_request (int major,int rw, struct buffer_head * bh) { struct request * req ; int rw_ahead; if (rw_ahead = (rw == READA || rw == WRITEA)) { if (bh->b_lock) return ; if (rw == READA) rw = READ; else rw = WRITE; } if (rw!=READ && rw!=WRITE) panic("Bad block dev command, must be R/W/RA/WA" ); lock_buffer(bh); if ((rw == WRITE && !bh->b_dirt) || (rw == READ && bh->b_uptodate)) { unlock_buffer(bh); return ; } repeat: if (rw == READ) req = request+NR_REQUEST; else req = request+((NR_REQUEST*2 )/3 ); while (--req >= request) if (req->dev<0 ) break ; if (req < request) { if (rw_ahead) { unlock_buffer(bh); return ; } sleep_on(&wait_for_request); goto repeat; } req->dev = bh->b_dev; req->cmd = rw; req->errors=0 ; req->sector = bh->b_blocknr<<1 ; req->nr_sectors = 2 ; req->buffer = bh->b_data; req->waiting = NULL ; req->bh = bh; req->next = NULL ; add_request(major+blk_dev,req); }
add_request
缓冲绘图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static void add_request (struct blk_dev_struct * dev, struct request * req) { struct request * tmp ; req->next = NULL ; cli(); if (req->bh) req->bh->b_dirt = 0 ; if (!(tmp=dev->current_request)){ dev->current_request = req; sti(); (dev->request_fn)(); return ; } for ( ; tmp->next ; tmp=tmp->next) if ((IN_ORDER(tmp,req) || !IN_ORDER(tmp,tmp->next)) && IN_ORDER(req,tmp->next)) break ; req->next=tmp->next; tmp->next=req; sti(); }
(dev->request_fn)();
do_hd_request
hd_init的时候挂载了请求项函数:#define DEVICE_REQUEST do_hd_request
blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST;
do_hd_request()是硬盘请求项的操作函数。其操作流程如下:
首先判断当前请求项是否存在,若当前请求项指针为空,则说明目前硬盘块设备已经没有待处理
的请求项,因此立刻退出程序。这是在宏 INIT_REQUEST
中执行的语句。否则就继续处理当前请 求项。
对当前请求项中指明的设备号和请求的盘起始扇区号的合理性进行验证;
根据当前请求项提供的信息计算请求数据的磁盘磁道号、磁头号和柱面号;
如果复位标志(reset)已被设置,则也设置硬盘重新校正标志(recalibrate),并对硬盘执行复位操
作,向控制器重新发送“建立驱动器参数”命令(WIN_SPECIFY)。该命令不会引发硬盘中断;
如果重新校正标志被置位的话,就向控制器发送硬盘重新校正命令(WIN_RESTORE),并在发送
之前预先设置好该命令引发的中断中需要执行的 C
函数(recal_intr()),并退出。recal_intr()函数的
主要作用是:当控制器执行该命令结束并引发中断时,能重新(继续)执行本函数。
如果当前请求项指定是写操作,则首先设置硬盘控制器调用的 C 函数为
write_intr(),向控制器发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 void do_hd_request (void ) { int i,r; unsigned int block,dev; unsigned int sec,head,cyl; unsigned int nsect; INIT_REQUEST; dev = MINOR(CURRENT->dev); block = CURRENT->sector; if (dev >= 5 *NR_HD || block+2 > hd[dev].nr_sects) { end_request(0 ); goto repeat; } block += hd[dev].start_sect; dev /= 5 ; __asm__("divl %4" :"=a" (block),"=d" (sec):"0" (block),"1" (0 ), "r" (hd_info[dev].sect)); __asm__("divl %4" :"=a" (cyl),"=d" (head):"0" (block),"1" (0 ), "r" (hd_info[dev].head)); sec++; nsect = CURRENT->nr_sectors; if (reset) { reset = 0 ; recalibrate = 1 ; reset_hd(CURRENT_DEV); return ; } if (recalibrate) { recalibrate = 0 ; hd_out(dev,hd_info[CURRENT_DEV].sect,0 ,0 ,0 , WIN_RESTORE,&recal_intr); return ; } if (CURRENT->cmd == WRITE) { hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr); for (i=0 ; i<3000 && !(r=inb_p(HD_STATUS)&DRQ_STAT) ; i++) ; if (!r) { bad_rw_intr(); goto repeat; } port_write(HD_DATA,CURRENT->buffer,256 ); } else if (CURRENT->cmd == READ) { hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr); } else panic("unknown hd-command" ); }
hd_out
hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr);
hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr);
后两个实参read_intr
是读盘对应的中断服务函数,是一个钩子,要提取这个函数的地址准备挂接,读挂接read_intr,写挂接write_intr
unsigned int cmd对应接下来要进行的操作
是硬盘控制器操作命令发送函数。该函数带有一个中断过程中调用的 C
函数指针参数,在
向控制器发送命令之前,它首先使用这个参数预置好中断过程中会调用的函数指针(do_hd)
然后它按 照规定的方式依次向硬盘控制器 0x1f0 至 0x1f7
发送命令参数块。:\#define outb_p(value,port)
除控制器诊断(WIN_DIAGNOSE)和
建立驱动器参数(WIN_SPECIFY)两个命令以外,硬盘控制器在接收到任何其它命令并执行了命令以后,
都会向 CPU 发出中断请求信号,从而引发系统去执行硬盘中断处理过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static void hd_out (unsigned int drive,unsigned int nsect,unsigned int sect, unsigned int head,unsigned int cyl,unsigned int cmd, void (*intr_addr)(void )) { register int port asm ("dx" ) ; if (drive>1 || head>15 ) panic("Trying to write bad sector" ); if (!controller_ready()) panic("HD controller not ready" ); do_hd = intr_addr; outb_p(hd_info[drive].ctl,HD_CMD); port=HD_DATA; outb_p(hd_info[drive].wpcom>>2 ,++port); outb_p(nsect,++port); outb_p(sect,++port); outb_p(cyl,++port); outb_p(cyl>>8 ,++port); outb_p(0xA0 |(drive<<4 )|head,++port); outb(cmd,++port); }
_hd_interrupt:
do_hd已经挂接了函数,在执行硬盘中断函数的时候会自动执行
_hd_interrupt位于system_call.s
这里中断函数的挂接在hd_init中完成
1 2 3 4 5 6 void hd_init (void ) { ... set_intr_gate(0x2E ,&hd_interrupt); ... }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 _hd_interrupt: pushl %eax pushl %ecx pushl %edx push %ds push %es push %fs movl $0x10,%eax ## ds,es 置为内核数据段。 mov %ax,%ds mov %ax,%es movl $0x17,%eax #fs置为调用程序的局部数据段。 mov %ax,%fs # 由于初始化中断控制芯片时没有采用自动 EOI,所以这里需要发指令结束该硬件中断。 movb $0x20,%al outb %al,$0xA0 # EOI to interrupt controller #1 jmp 1f # give port chance to breathe 1: jmp 1f 1: xorl %edx,%edx #清零 xchgl _do_hd,%edx # do_hd 定义为一个函数指针,将被赋值 read_intr()或write_intr()函数地址。(kernel/blk_drv/hd.c) # 放到 edx 寄存器后就将 do_hd 指针变量置为 NULL。 testl %edx,%edx # 测试函数指针是否为 Null。 jne 1f # 若空,则使指针指向 C 函数 unexpected_hd_interrupt() movl $_unexpected_hd_interrupt,%edx # 送主 8259A 中断控制器 EOI 指令(结束硬件中断)。 1: outb %al,$0x20 call *%edx # "interesting" way of handling intr. pop %fs #上句调用 do_hd 指向的 C 函数 pop %es pop %ds popl %edx popl %ecx popl %eax iret
硬盘开始将引导块中的数据不断读入缓存中,同时函数一路返回到bread
读盘还没完成这个过程中进程0,1的切换
进入wait_on_buffer(bh);
进入sleep_on,此时进程1设置为不可中断等待状态,进入schedule函数
image-20231127094912326
sleep_on
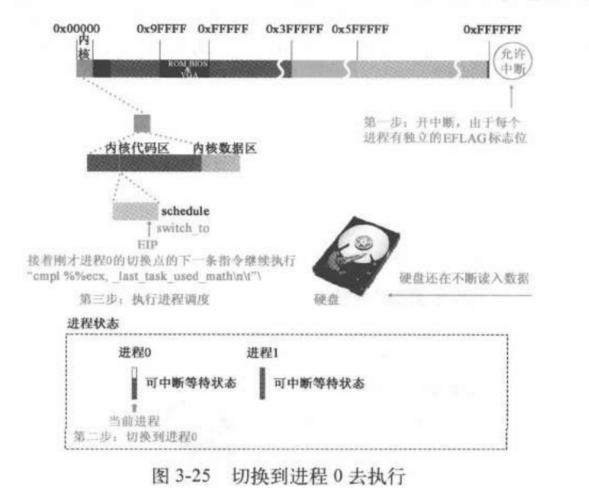
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void sleep_on (struct task_struct **p) { struct task_struct *tmp ; if (!p) return ; if (current == &(init_task.task)) panic("task[0] trying to sleep" ); tmp = *p; *p = current; current->state = TASK_UNINTERRUPTIBLE; schedule(); if (tmp) tmp->state=0 ; }
getblk 是先进去再读写数据
可能不同进程用同一个缓冲块。因为进入队列以后没有立刻写数据,getblk找现成的找到了同一个缓冲块,一个进程sleep
on的时候,其他的进程也sleep on 了 目前在内核态,tmp在内核栈里面
buffer head是全局的变量(buffer init) ##### 进程0被强制唤醒
这次遍历task的时候,进程0和进程1都是不可中断等待状态,这时进程0就以不可中断状态的姿态强制执行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void schedule (void ) { ... if (c) break ; for (p = &LAST_TASK ; p > &FIRST_TASK ; --p) if (*p) (*p)->counter = ((*p)->counter >> 1 )+ (*p)->priority; } switch_to(next); }
之前进程0被切换到进程1的时候,进程0停在了switch_to函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 #define switch_to(n) {\ struct {long a,b;} __tmp; \ __asm__("cmpl %%ecx,_current\n\t" \ ... "ljmp %0\n\t" \ "cmpl %%ecx,_last_task_used_math\n\t" \ "jne 1f\n\t" \ "clts\n" \ "1:" \ ::"m" (*&__tmp.a),"m" (*&__tmp.b), \ "d" (_TSS(n)),"c" ((long ) task[n])); \ }
切到进程1的时候执行了ljmp %0\n\进程切走了,而进程0自己的tss里面保存的要执行的下一条指令的eip:cmpl %%ecx,_last_task_used_math\n\t
是这条指令,因此切回进程0从这条语句开始执行
进程0将处于挂起状态执行:pause(),sys_pause(),schedule(),switch_to(0).进程0起到怠速作用
当过了一段时间,硬盘剩下的数据读完了硬件产生中断,读盘中断服务程序响应中断,进入read_intr判断缓冲区是否读完,这里一共一个块要读两次,两次都读完就读完了
不执行if (--CURRENT->nr_sectors)里面·的·语句,直接跳到end_request(1)语句执行
read_intr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static void read_intr (void ) { if (win_result()) { bad_rw_intr(); do_hd_request(); return ; } port_read(HD_DATA,CURRENT->buffer,256 ); CURRENT->errors = 0 ; CURRENT->buffer += 512 ; CURRENT->sector++; if (--CURRENT->nr_sectors) { do_hd = &read_intr; return ; } end_request(1 ); do_hd_request(); }
image-20231203231230513
end_request
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #define CURRENT (blk_dev[MAJOR_NR].current_request) struct task_struct * wait_for_request =NULL ;extern inline void end_request (int uptodate) { DEVICE_OFF(CURRENT->dev); if (CURRENT->bh) { CURRENT->bh->b_uptodate = uptodate; unlock_buffer(CURRENT->bh); } if (!uptodate) { printk(DEVICE_NAME " I/O error\n\r" ); printk("dev %04x, block %d\n\r" ,CURRENT->dev, CURRENT->bh->b_blocknr); } wake_up(&CURRENT->waiting); wake_up(&wait_for_request); CURRENT->dev = -1 ; CURRENT = CURRENT->next; }
此时磁盘已经全部读进来,update=1位置1
进程1唤醒
unlock_buffer
1 2 3 4 5 6 7 extern inline void unlock_buffer (struct buffer_head * bh) { if (!bh->b_lock) printk(DEVICE_NAME ": free buffer being unlocked\n" ); bh->b_lock=0 ; wake_up(&bh->b_wait); }
wake_up
1 2 3 4 5 6 7 8 9 10 void wake_up (struct task_struct **p) { if (p && *p) { (**p).state=0 ; *p=NULL ; } }
这里是null还是tmp的讨论---sleep_on深层逻辑基于内核栈的唤醒队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void sleep_on (struct task_struct **p) { struct task_struct *tmp ; if (!p) return ; if (current == &(init_task.task)) panic("task[0] trying to sleep" ); tmp = *p; *p = current; current->state = TASK_UNINTERRUPTIBLE; schedule(); if (tmp) tmp->state=0 ; *p=tmp; }
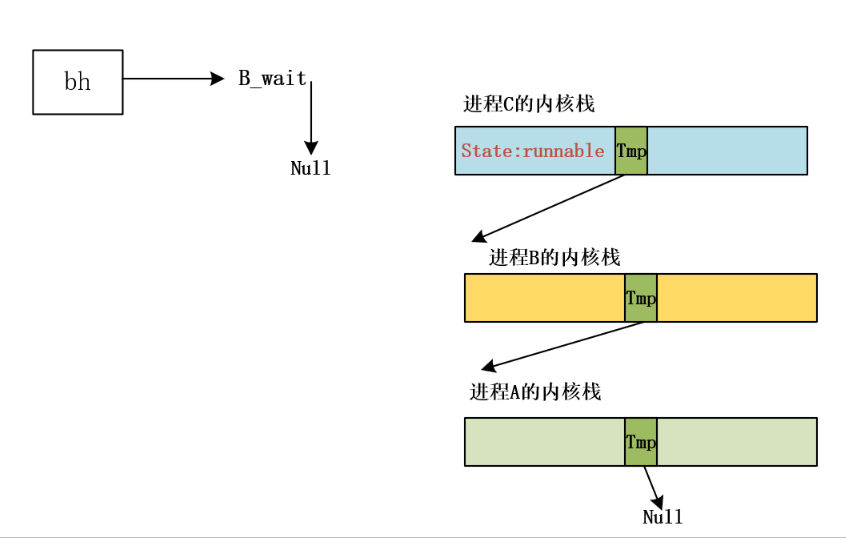
sleep on 构成的队列分析:
因为sleep_on是在内核态调用的,所以这里的tmp是在内核栈中,b_wait是全局变量。一开始只有进程A申请的时候,最开始的b_wait=null
假设一开始只有进程A,A申请缓冲块,一开始没有现成的的缓冲块,进程A调用getblk,首先在hash表里面找get_hash_table
没有现成的,然后沿着free_list在缓冲块的双向环链表上面寻找,顺着链找一块没被别的进程占用(引用计数为0(别的进程已经走了),并且最好是lock或者完全没被用过的,其次才是dirt的),此时假设缓冲区全是新的(和进程1一样),此时A会把该缓冲块插入hash的叉子上,然后进程A需要等待磁盘将内容加载到它选择的这块缓冲块里面,在等待的过程中进程A
sleep。具体而言,在make_request中开始加锁:lock_buffer,进程A在执行到bread的wait_on_buffer(bh);的时候睡眠等待磁盘把缓冲区写完。
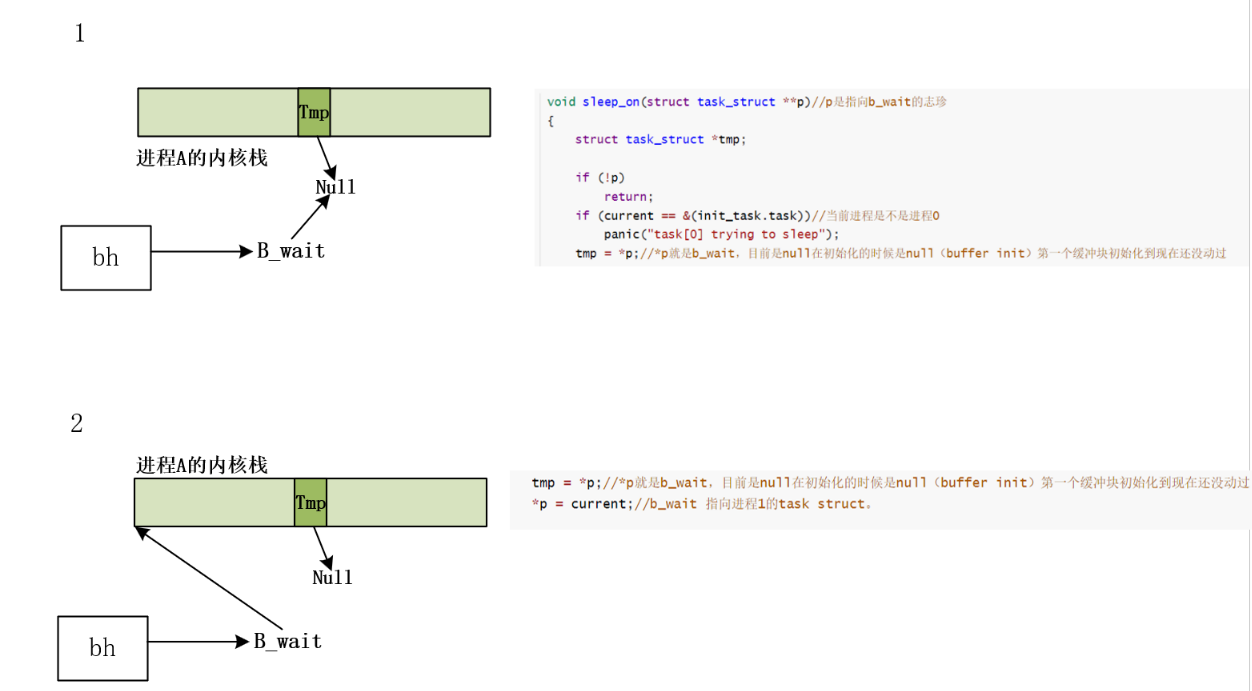
A stack
此时如果切到新的进程B也要申请和A相同的设备号块号,B在调用getblk的时候:执行if (bh = get_hash_table(dev,block)) return bh的时候,因为A已经把缓冲块放到Hash队列里面了,所以进程B找到了现成的,此时进程A还没有用完,进程B在wait
buffer的时候调用sleep_on。
B内核栈
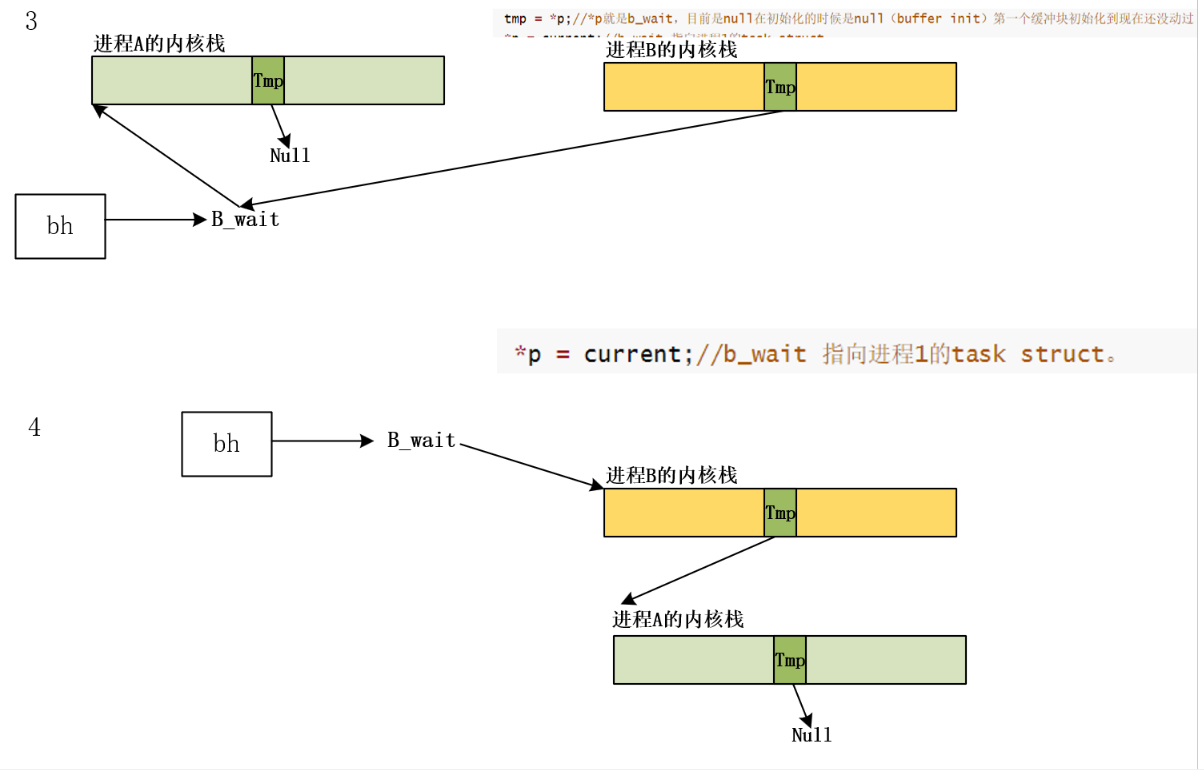
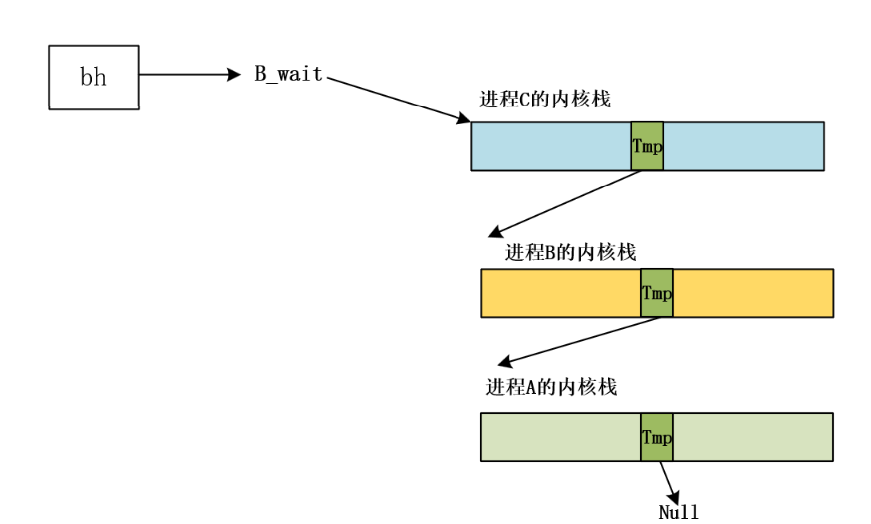
同理如果又来了进程C也请求了该缓冲块就变成:形成一个由内核栈构成的等待队列
等待队列
该缓冲块插入hash的叉子上
image-20231129095311681
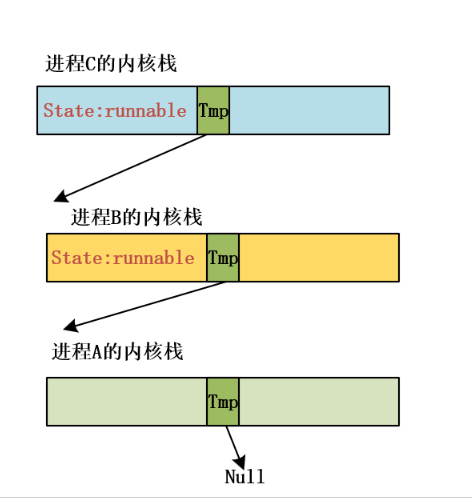
那么现在回到wake up
当进程A完成磁盘的操作后,唤醒进程的时候是通过b
wait唤醒,如果是null的效果:
1 2 3 4 5 6 7 8 9 10 void wake_up (struct task_struct **p) { if (p && *p) { (**p).state=0 ; *p=NULL ; } }
image-20231129110807043
切回来以后进程继续沿着sleep_on执行
image-20231129111725176
唤醒tmp所指的进程B
image-20231129111811437
在schedule的时候会用到state,由于此时state已经设为0解锁了,调度的时候就可以切到该进程执行。
image-20231129111130011
在这个框架下面其他的进程怎么唤醒?由链子上面的上一个进程负责唤醒下一个进程
bread后时代
回到sys_setup执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 int sys_setup (void * BIOS) { ... for (drive=0 ; drive<NR_HD ; drive++) { if (!(bh = bread(0x300 + drive*5 ,0 ))) { printk("Unable to read partition table of drive %d\n\r" , drive); panic("" ); } if (bh->b_data[510 ] != 0x55 || (unsigned char ) bh->b_data[511 ] != 0xAA ) { printk("Bad partition table on drive %d\n\r" ,drive); panic("" ); } p = 0x1BE + (void *)bh->b_data; for (i=1 ;i<5 ;i++,p++) { hd[i+5 *drive].start_sect = p->start_sect; hd[i+5 *drive].nr_sects = p->nr_sects; } brelse(bh); } if (NR_HD) printk("Partition table%s ok.\n\r" ,(NR_HD>1 )?"s" :"" ); rd_load(); mount_root(); return (0 ); }
引导块0,超级块1,一个分区一个
文件系统
MINIX 文件系统
详见:操作系统文件系统。
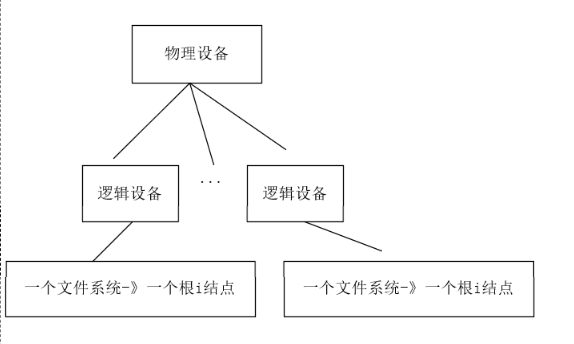
操作系统中的文件系统可以分为两部分:操作系统内核中或者在硬盘软盘虚拟盘中。一个物理设备可以分为多个逻辑设备,比如一个物理硬盘可以分为多个逻辑硬盘。而一个逻辑设备只有一个文件系统,一个文件系统只包含一个i结点的树结构。一个逻辑设备只能有一个根i结点。
image-20231203234247319
未安装文件系统的磁盘称之为生磁盘,生磁盘也可以作为文件读写,linux中一切皆文件。
生磁盘可以被分区,分区中可以安装文件系统,常见的文件系统有fat32、ext2、ext4等。
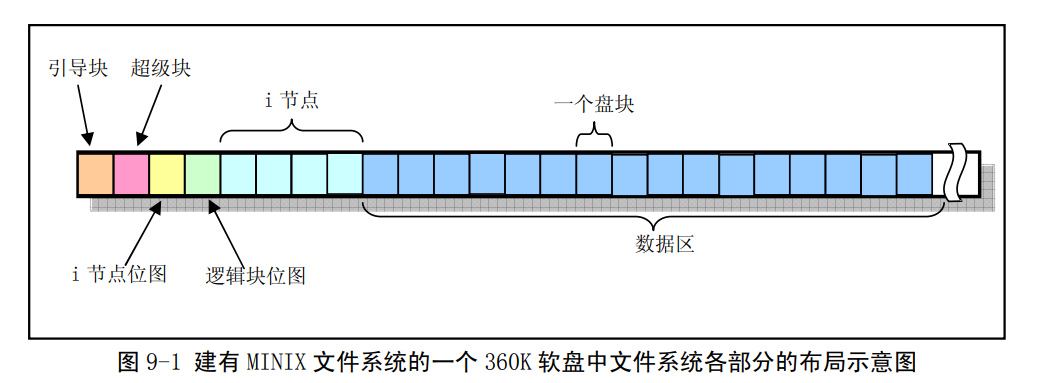
MINIX 文件系统与标准 UNIX 的文件系统基本相同。它由 6
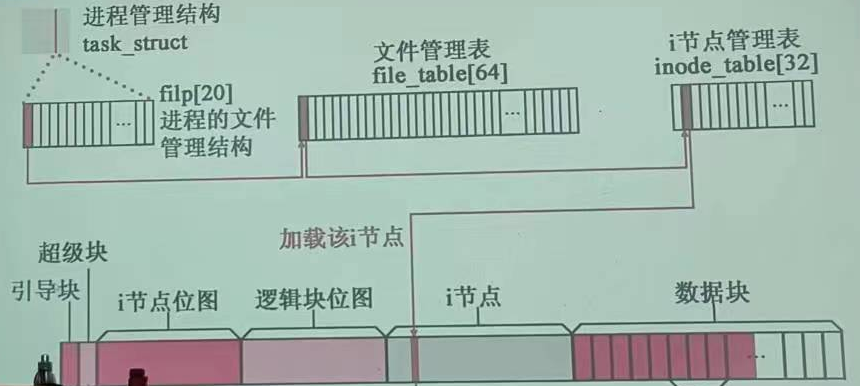
个部分组成。分区内可以安装指定文件系统,同一磁盘多个分区文件系统不要求相同。MINIX文件系统布局如下:(下述部分是在磁盘上的)
MINIX文件系统布局
引导块:若作为引导分区,将存放操作系统的引导程序代码 ,否则空置。
超级块:用于存放磁盘设备上文件系统结构的信息 ,说明各部分的大小。
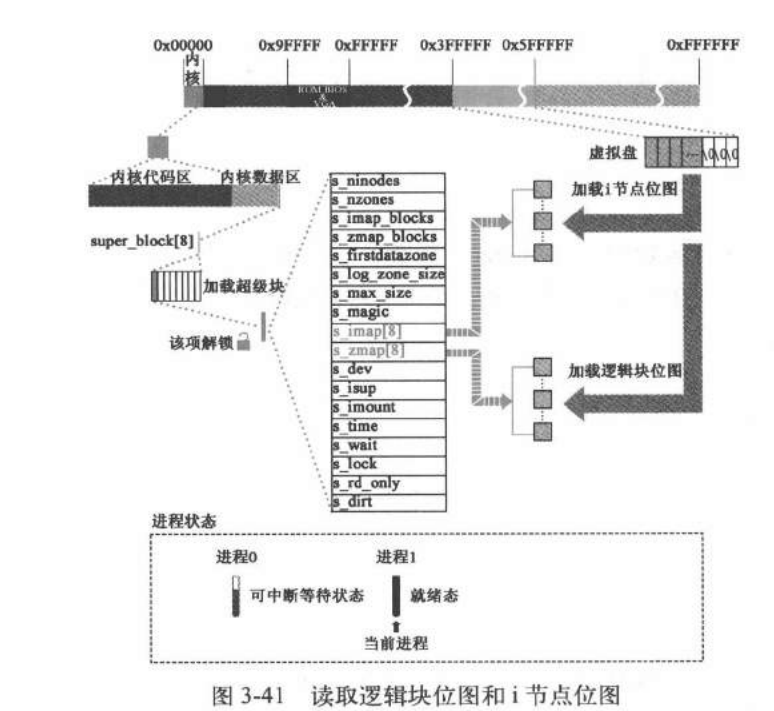
i节点位图:标记i节点数据元素是否被使用
逻辑块位图:标记磁盘数据块是否被使用
i节点区:用于存放inode节点数据,一个文件对应一个inode节点,inode节点存储文件属性数据。
数据区:以固定大小盘块(1k)为单位进行动态分配和回收,用于存储数据,类似内存分页。
位图:一个比特对应一个逻辑块,0,1代表是否被占用
删除文件:清理数据块关系清掉,对应逻辑块位图清0,清理i结点和i结点对应位图。
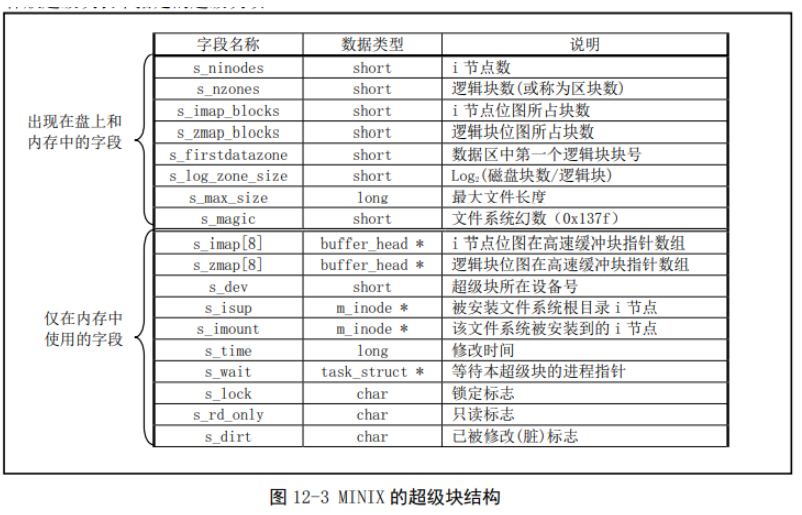
超级块结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct super_block { unsigned short s_ninodes; unsigned short s_nzones; unsigned short s_imap_blocks; unsigned short s_zmap_blocks; unsigned short s_firstdatazone; unsigned short s_log_zone_size; unsigned long s_max_size; unsigned short s_magic; struct buffer_head * s_imap [8]; struct buffer_head * s_zmap [8]; unsigned short s_dev; struct m_inode * s_isup ; struct m_inode * s_imount ; unsigned long s_time; struct task_struct * s_wait ; unsigned char s_lock; unsigned char s_rd_only; unsigned char s_dirt; };
超级块结构
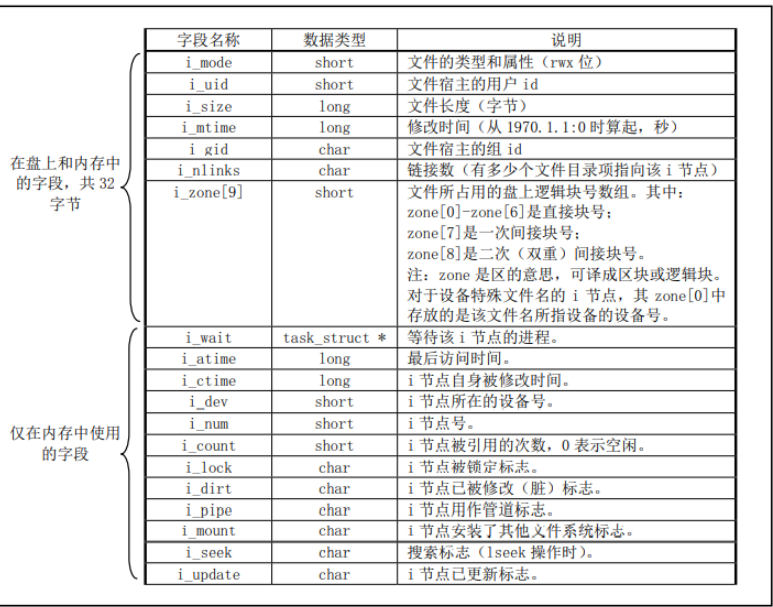
inode结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct m_inode { unsigned short i_mode; unsigned short i_uid; unsigned long i_size; unsigned long i_mtime; unsigned char i_gid; unsigned char i_nlinks; unsigned short i_zone[9 ]; struct task_struct * i_wait ; unsigned long i_atime; unsigned long i_ctime; unsigned short i_dev; unsigned short i_num; unsigned short i_count; unsigned char i_lock; unsigned char i_dirt; unsigned char i_pipe; unsigned char i_mount; unsigned char i_seek; unsigned char i_update; };
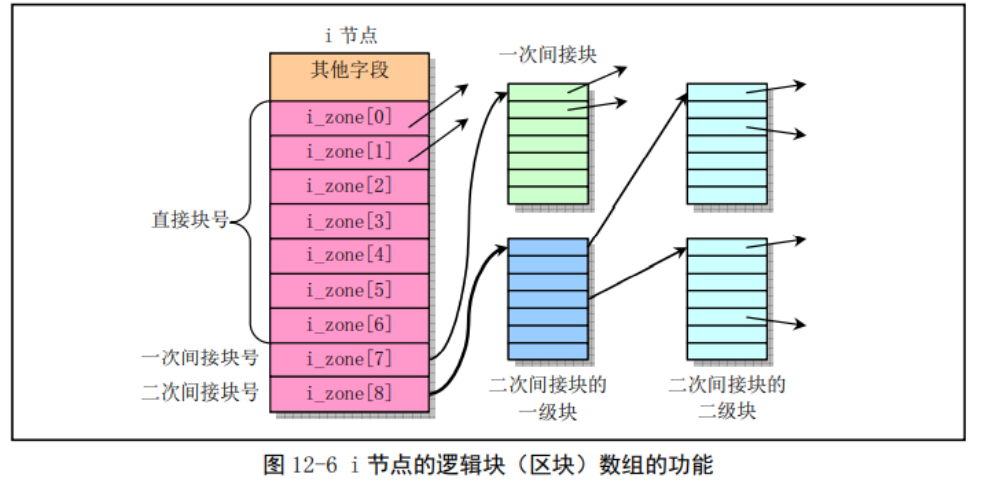
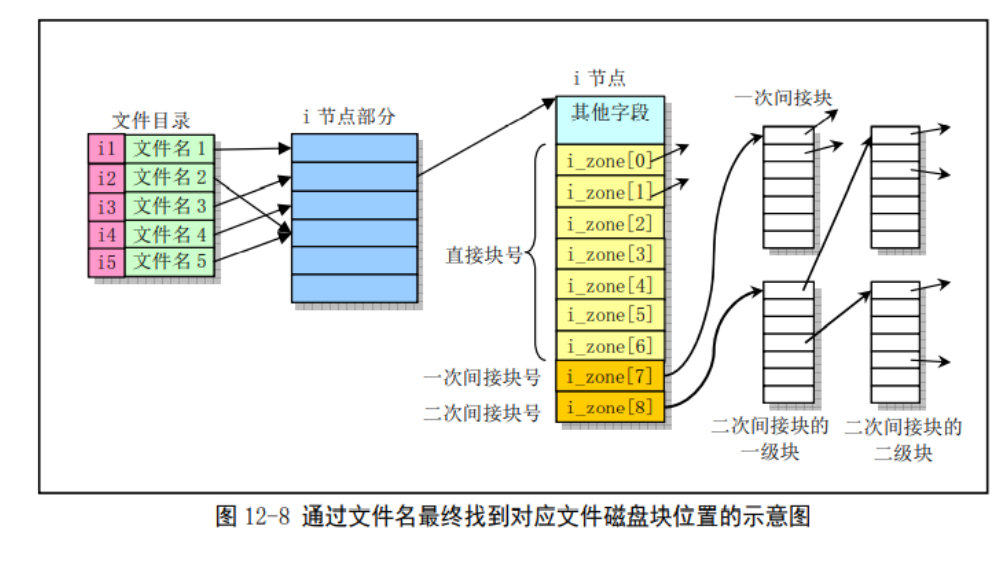
inode结构
i_zone数组
unsigned short i_zone[9];
i_zone数组包含直接盘块号、一次间接盘块号和二次间接盘块号。一次盘块号可视为单级页表,一次间接盘块号可视为二级页表、二次间接盘块号可视为三级页表。
这种处理方式的好处在于,对于小文件,通过直接块号可快速定位数据块;对于中等类型的文件,一次间接块可以维护较多数据块的同时,具有较快的访问速度;对于大型文件,二次间接盘块号可以维护大量磁盘块,但访问速度较慢。
内存多级页表与i_zone直接区别:不同进程具有固定大小的虚地址空间,并且对其整个虚地址空间的内存,都有可能访问到,因此使用多级页表。文件系统内存在很多大小不一的文件,综合考虑对不同大小文件的特点,使用1-3级磁盘块表可以分别处理小、中、大文件。
izone
文件系统
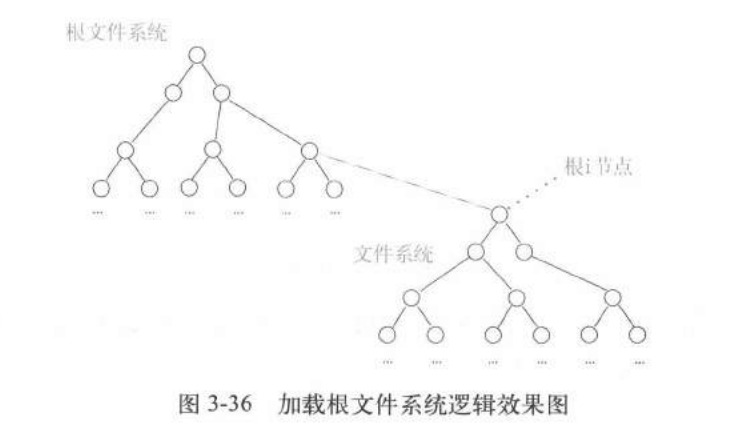
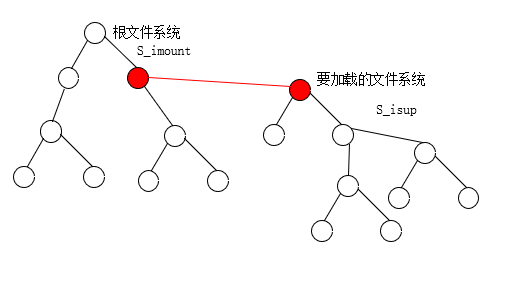
所有文件的i结点最终会挂成一个树形结构,树根i结点就是文件系统的根i结点,
加载文件系统就是把一个文件系统的根i结点挂接在另一个文件系统的i结点上,按照这个设计,一个文件系统必须要挂在另一个文件系统上面,最后最根部那个文件系统就是根文件系统
加载根文件系统
根文件系统挂在super_block[8]上。超级块:有一个超级块数组super_block[8]里面每一个元素是一个超级块,只要一个文件系统加载到内核了这个文件系统的根i结点会依次加载到这个数组里面。最多加载8个文件系统
总体效果图
文件系统用i结点来管理,一个i结点管理一个文件,目录文件也是文件,也有i结点来管理。
文件系统与i结点
加载文件过程举例 :
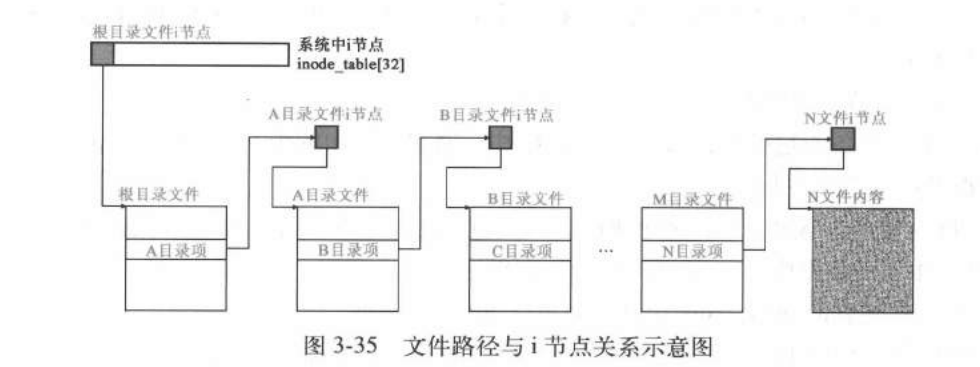
通过文件inode节点,可以定位文件数据块,那如何通过文件路径定位到具体文件?
文件系统主要包含文件和目录两种文件,目录是一种特殊的文件,其文件内容存储其目录下文件名->inode节点号的映射信息。文件查找开始于根目录,根目录号固定为0,不需要查找即可直接打开。
举例说明文件查找过程,给定存在路径/name1/name2/name3查找具体文件过程:
1)通过根节点inode号,打开根目录,读取其文件内容,即目录下文件名->inode节点号映射表,找到name1目录inode节点号n1
2)通过name1的inode号n1,打开name1目录,读取其文件内容,即目录下文件名->inode节点号映射表,找到name1目录inode节点号n2
3)通过name2的inode号n2,打开name2目录,读取其文件内容,即目录下文件名->inode节点号映射表,找到name3目录inode节点号n3
4)通过name3的inode号n3,打开name3文件
怎么打开文件:
通过文件查找找到文件inode节点号,然后打开文件,即读取inode至内存。
定位数据块:通过文件inode节点,访问其i_zone数组,进一步可以定位具体的数据所在磁盘块号。
以c语言open和close返回的是什么解释文件系统
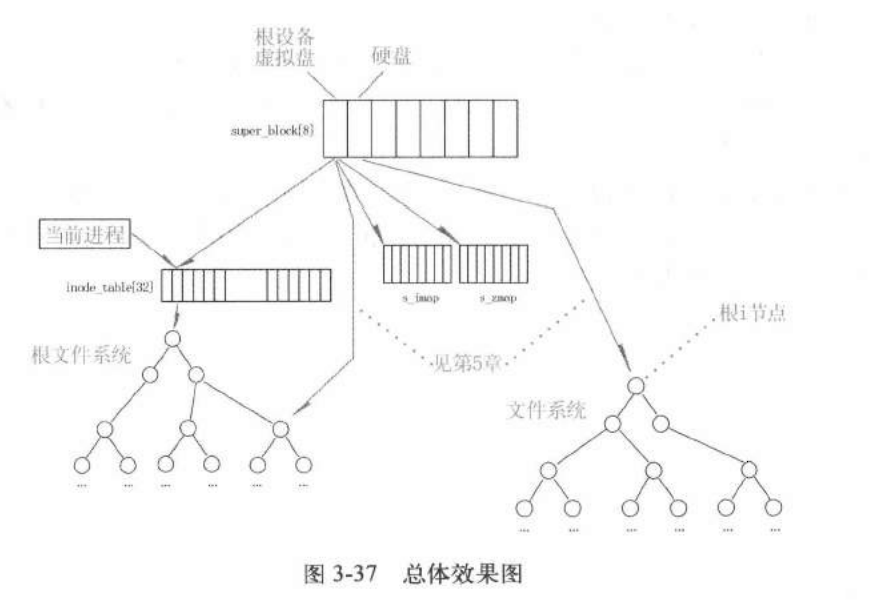
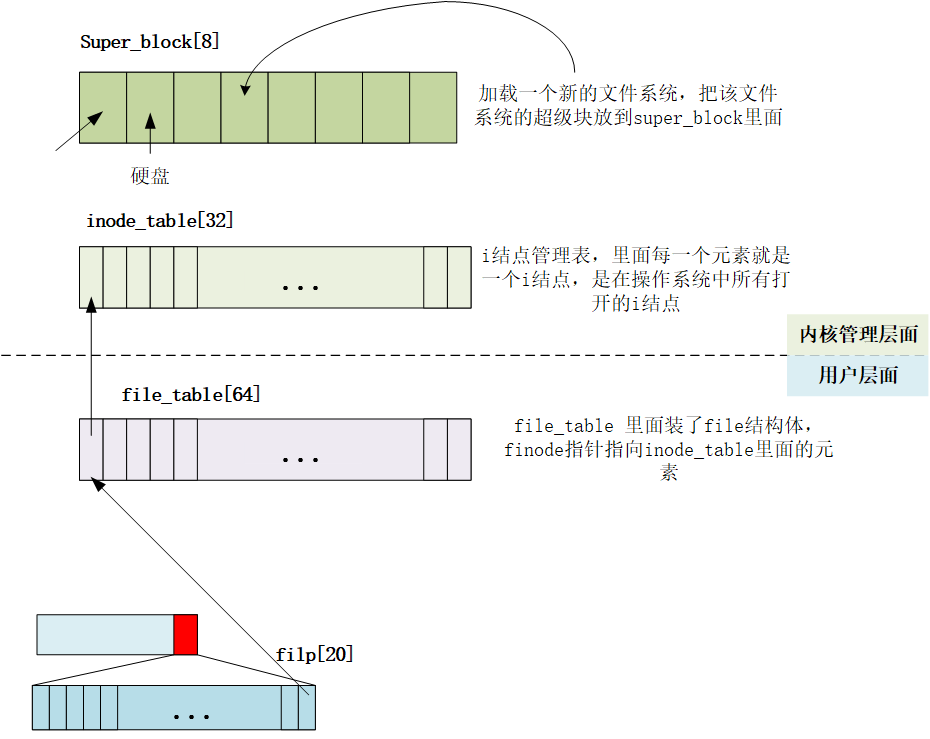
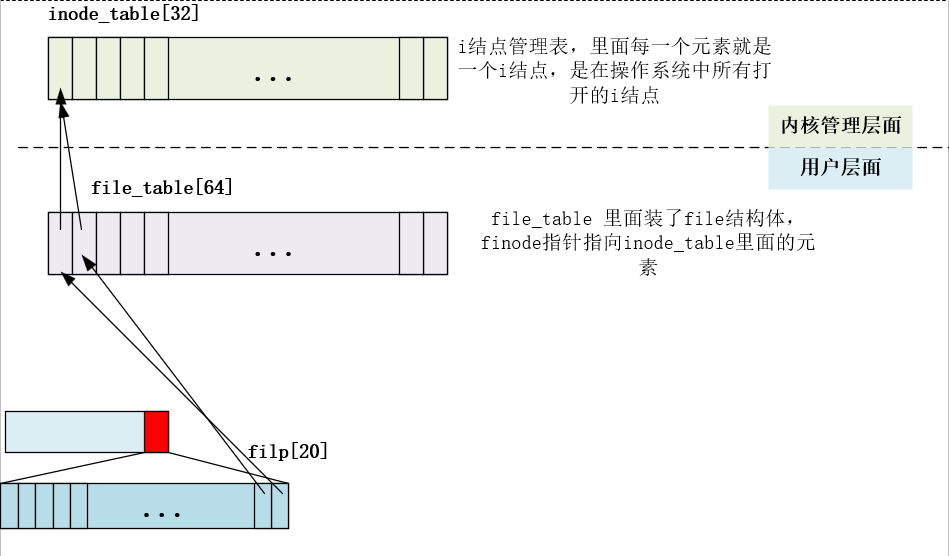
1 2 3 4 5 6 7 8 9 10 struct file file_table [NR_FILE ]; struct super_block super_block [NR_SUPER ]; struct file { unsigned short f_mode; unsigned short f_flags; unsigned short f_count; struct m_inode * f_inode ; off_t f_pos; };
操作系统只有一个super_blocks数组,每个数组元素是一个超级块,一个超级块管理一个逻辑设备,因此最多挂载8个逻辑设备,其中只有一个根设备。
inode_table[32]每一个元素就是一个i结点,是在操作系统中所有打开的i结点
file_table
里面装了file结构体,struct super_block super_block[NR_SUPER]
f_inode指针指向inode_table里面的元素
task struct里面的filp struct file * filp[NR_OPEN];/:
指针数组,每个元素都是file类型的指针
linux
0.11一个进程最多只能打开20个文件(文件是可以重复打开的)可以同一个文件占多个file_table的表项
filp归进程管。进程打开一个文件,首先在filp里面找空闲项,
将这个空闲的位置指向file_table其中的一项,这一项里面的f_inode指针指向inode_table。
c语言里面打开文件返回的句柄就是这个指向的inode_table位置对应的下标索引,例如下图就是0.打开文件就是建立这个指针链接的过程,对应的close文件就是把这个关系链断掉。
file对应的是用户的需求,inode对应的是内核管理
文件系统
打开同一个文件,指向的inode_table是一个,file_table新开了一个
file_table【64】是整个kernel只有一个,file_table[32]也是整个操作系统只有一个,每个元素是一个file对象
打开同一个文件
目录跟结点也要放到inode——table,当路径找完了就把结点pop了
image-20231205200445043
更换根设备(进程1格式化虚拟盘并更换跟设备为虚拟盘)
之前第二章设置了虚拟盘并初始化,但是当时没有进行格式化还不能作为块设备使用。格式化的信息存在boot操作系统的软盘上
进程1调用rd_load();函数格式化虚拟盘调用
rd_load()是虚拟盘根文件加载函数。在系统初始化阶段,该函数被用于尝试从启动引导盘
上指定的磁盘块位置开始处把一个根文件系统加载到虚拟盘中。在函数中,这个起始磁盘块位置被定为256。当然你也可以根据自己的具体要求修改这个值,只要保证这个值所规定的磁盘容量能容纳内核映象
文件即可。这样一个由内核引导映象文件(Bootimage)加上根文件系统映象文件(Rootiamge)组合而
成的“二合一”磁盘,就可以象启动 DOS 系统盘那样来启动 Linux
系统。在进行正常的根文件系统加载之前,系统会首先执行
rd_load()函数,试图从磁盘的第 257 块中读取
根文件系统超级块。若成功,就把该根文件映象文件读到内存虚拟盘中,并把根文件系统设备标志
ROOT_DEV 设置为虚拟盘设备(0x0101),否则退出
rd_load(),系统继续从别的设备上执行根文件加载 操作。
之前根设备是软盘:bootsect.s里面指定的
==把虚拟盘指定为根设备,读硬盘是有中断的。软盘因为比较快就在内存里。所以读软盘不用中断读软盘要用do_rd_request==
==rd虚拟盘,虚拟的是软盘==,相当于把软盘的内容映射过来,然后把虚拟盘替软盘成为根设备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 void rd_load (void ) { struct buffer_head *bh ; struct super_block s ; int block = 256 ; int i = 1 ; int nblocks; char *cp; if (!rd_length) return ; printk("Ram disk: %d bytes, starting at 0x%x\n" , rd_length, (int ) rd_start); if (MAJOR(ROOT_DEV) != 2 ) return ; bh = breada(ROOT_DEV,block+1 ,block,block+2 ,-1 ); if (!bh) { printk("Disk error while looking for ramdisk!\n" ); return ; } *((struct d_super_block *) &s) = *((struct d_super_block *) bh->b_data); brelse(bh); if (s.s_magic != SUPER_MAGIC) return ; nblocks = s.s_nzones << s.s_log_zone_size; if (nblocks > (rd_length >> BLOCK_SIZE_BITS)) { printk("Ram disk image too big! (%d blocks, %d avail)\n" , nblocks, rd_length >> BLOCK_SIZE_BITS); return ; } printk("Loading %d bytes into ram disk... 0000k" , nblocks << BLOCK_SIZE_BITS); cp = rd_start; while (nblocks) { if (nblocks > 2 ) bh = breada(ROOT_DEV, block, block+1 , block+2 , -1 ); else bh = bread(ROOT_DEV, block); if (!bh) { printk("I/O error on block %d, aborting load\n" , block); return ; } (void ) memcpy (cp, bh->b_data, BLOCK_SIZE); brelse(bh); printk("\010\010\010\010\010%4dk" ,i); cp += BLOCK_SIZE; block++; nblocks--; i++; } printk("\010\010\010\010\010done \n" ); ROOT_DEV=0x0101 ; }
加载根文件系统
进程1调用mount_root在根设备虚拟盘上加载根文件系统
1 2 3 4 5 6 struct super_block {... struct m_inode * s_isup ; struct m_inode * s_imount ; ... };
文件系统加载结点
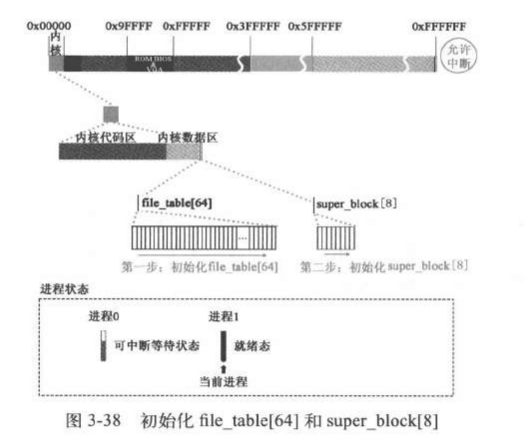
首先挂载super_block数组和file_table数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void mount_root (void ) { int i,free ; struct super_block * p ; struct m_inode * mi ; if (32 != sizeof (struct d_inode)) panic("bad i-node size" ); for (i=0 ;i<NR_FILE;i++) file_table[i].f_count=0 ; if (MAJOR(ROOT_DEV) == 2 ) { printk("Insert root floppy and press ENTER" ); wait_for_keypress(); } for (p = &super_block[0 ] ; p < &super_block[NR_SUPER] ; p++) { p->s_dev = 0 ; p->s_lock = 0 ; p->s_wait = NULL ; } ... }
image-20231211092132558
read_super加载文件系统超级块
1 2 3 4 5 6 7 void mount_root (void ) { ... if (!(p=read_super(ROOT_DEV))) panic("Unable to mount root" ); ... }
read_super()用于把指定设备的文件系统的==超级块==读入到==缓冲区==中,并登记到超级块数组中,同时也
把文件系统的 i
节点位图和逻辑块位图读入内存超级块结构的相应数组中。最后并返回该超级块结构的
指针。
首先检查这个要读的超级块是不是已经在super_block[8]中,如果有直接使用不用在加载一次了(和缓冲区看有没有现成的一个意思)
1 2 3 4 5 6 7 8 9 10 11 12 13 static struct super_block * read_super (int dev) { struct super_block * s ; struct buffer_head * bh ; int i,block; if (!dev) return NULL ; check_disk_change(dev); if (s = get_super(dev)) return s; ... }
get_super
查这个要读的超级块是不是已经在super_block[8]中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct super_block * get_super (int dev) { struct super_block * s ; if (!dev) return NULL ; s = 0 +super_block; while (s < NR_SUPER+super_block) if (s->s_dev == dev) { wait_on_super(s); if (s->s_dev == dev) return s; s = 0 +super_block; } else s++; return NULL ; }
超级块上锁等待(别的进程加载了这个文件系统)
1 2 3 4 5 6 7 8 static void wait_on_super (struct super_block * sb) { cli(); while (sb->s_lock) sleep_on(&(sb->s_wait)); sti(); }
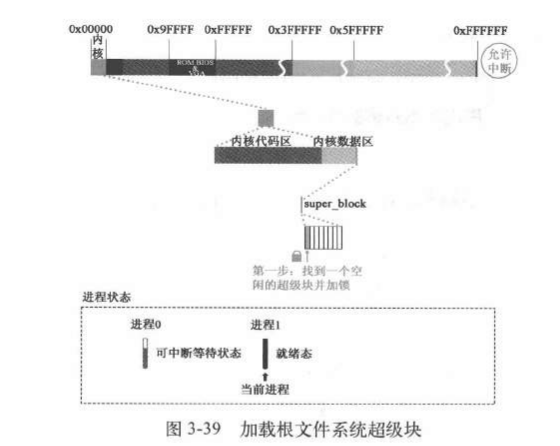
在super_block里面找到空项
在super_block中找到一项空的并加锁。这里加载根文件系统,第一项就是空的所以是选了第一个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static struct super_block * read_super (int dev) { ... for (s = 0 +super_block ;; s++) { if (s >= NR_SUPER+super_block) return NULL ; if (!s->s_dev) break ; } s->s_dev = dev; s->s_isup = NULL ; s->s_imount = NULL ; s->s_time = 0 ; s->s_rd_only = 0 ; s->s_dirt = 0 ; lock_super(s); ... }
image-20231211095203241
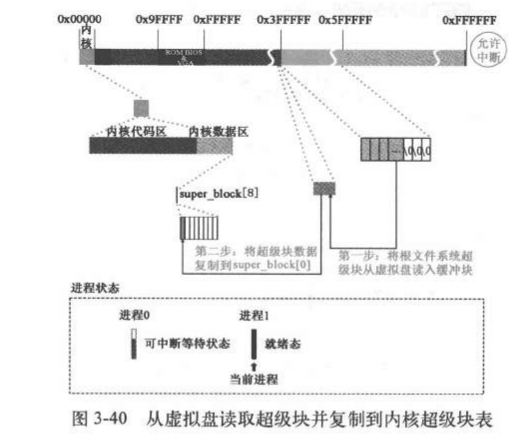
把超级块加载到缓冲区,再加载到super
block
调用bread读取超级块,这里的设备是rd虚拟盘。块号是1.因此在do
request的时候是do_rd_request.虚拟盘虽然是内存模拟的盘,但是读取的操作完全模仿了外设,但是他毕竟是内存不是外设,因此和读硬盘不同的是:不会发生类似硬盘中断的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static struct super_block * read_super (int dev) { ... if (!(bh = bread(dev,1 ))) { s->s_dev=0 ; free_super(s); return NULL ; } *((struct d_super_block *) s) = *((struct d_super_block *) bh->b_data); brelse(bh); if (s->s_magic != SUPER_MAGIC) { s->s_dev = 0 ; free_super(s); return NULL ; } ... }
image-20231211100257070
完善super
blok中i结点位图逻辑位图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 static struct super_block * read_super (int dev) { ... for (i=0 ;i<I_MAP_SLOTS;i++) s->s_imap[i] = NULL ; for (i=0 ;i<Z_MAP_SLOTS;i++) s->s_zmap[i] = NULL ; block=2 ; for (i=0 ; i < s->s_imap_blocks ; i++) if (s->s_imap[i]=bread(dev,block)) block++; else break ; for (i=0 ; i < s->s_zmap_blocks ; i++) if (s->s_zmap[i]=bread(dev,block)) block++; else break ; if (block != 2 +s->s_imap_blocks+s->s_zmap_blocks) { for (i=0 ;i<I_MAP_SLOTS;i++) brelse(s->s_imap[i]); for (i=0 ;i<Z_MAP_SLOTS;i++) brelse(s->s_zmap[i]); s->s_dev=0 ; free_super(s); return NULL ; } s->s_imap[0 ]->b_data[0 ] |= 1 ; s->s_zmap[0 ]->b_data[0 ] |= 1 ; free_super(s); return s; }
1 2 3 4 5 6 7 8 static void free_super (struct super_block * sb) { cli(); sb->s_lock = 0 ; wake_up(&(sb->s_wait)); sti(); }
image-20231211102021214
将根设备的根i结点挂载super
block上
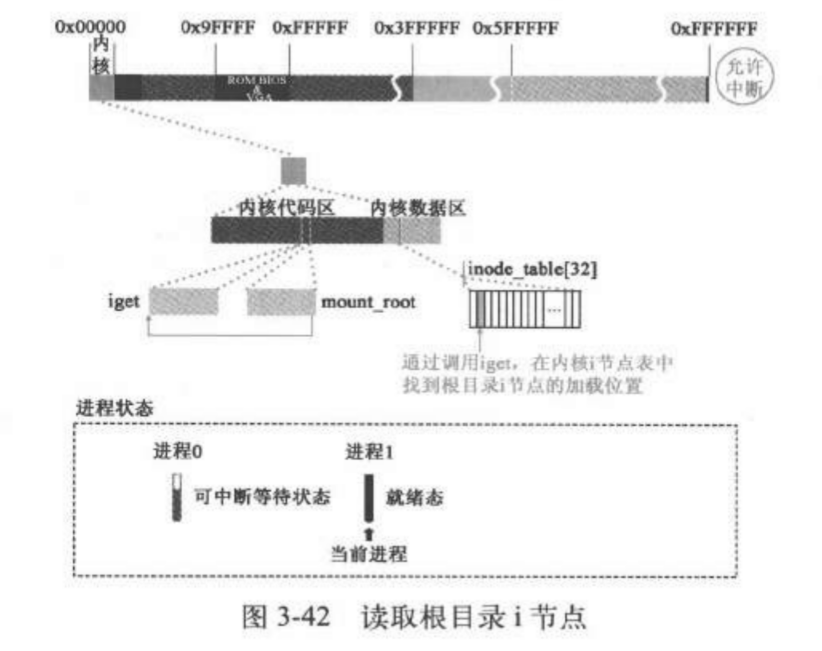
调用iget从虚拟盘上读取i结点。有了i结点,可以通过根i结点找到文件系统中的任意指定i结点
1 2 3 4 5 6 7 8 9 void mount_root (void ) { ... if (!(mi=iget(ROOT_DEV,ROOT_INO))) panic("Unable to read root i-node" ); ...
iget:get_empty_inode
首先在记载所有打开的i结点的数组中申请一个空闲的
1 2 3 4 5 6 7 8 9 struct m_inode * iget (int dev,int nr) { struct m_inode * inode , * empty ; if (!dev) panic("iget with dev==0" ); empty = get_empty_inode(); ... }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 struct m_inode * get_empty_inode (void ) { struct m_inode * inode ; static struct m_inode * last_inode = int i; do { inode = NULL ; for (i = NR_INODE; i ; i--) { if (++last_inode >= inode_table + NR_INODE) last_inode = inode_table; if (!last_inode->i_count) { inode = last_inode; if (!inode->i_dirt && !inode->i_lock) break ; } } if (!inode) { for (i=0 ; i<NR_INODE ; i++) printk("%04x: %6d\t" ,inode_table[i].i_dev, inode_table[i].i_num); panic("No free inodes in mem" ); } wait_on_inode(inode); while (inode->i_dirt) { write_inode(inode); wait_on_inode(inode); } } while (inode->i_count); memset (inode,0 ,sizeof (*inode)); inode->i_count = 1 ; return inode; }
iget
inode_table 初始化的时候:
1 struct m_inode inode_table [NR_INODE ]=0 ,},};
这是对数组进行初始化的语法。它使用了一个嵌套的大括号,将数组中的每个元素初始化为
{0,},这将初始化结构体中的所有成员为零(或NULL,具体取决于结构体的定义)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 struct m_inode * iget (int dev,int nr) { ... inode = inode_table; while (inode < NR_INODE+inode_table) { if (inode->i_dev != dev || inode->i_num != nr) { inode++; continue ; } wait_on_inode(inode); if (inode->i_dev != dev || inode->i_num != nr) { inode = inode_table; continue ; } inode->i_count++; if (inode->i_mount) { int i; for (i = 0 ; i<NR_SUPER ; i++) if (super_block[i].s_imount==inode) break ; if (i >= NR_SUPER) { printk("Mounted inode hasn't got sb\n" ); if (empty) iput(empty); return inode; } iput(inode); dev = super_block[i].s_dev; nr = ROOT_INO; inode = inode_table; continue ; } if (empty) iput(empty); return inode; } if (!empty) return (NULL ); inode=empty; inode->i_dev = dev; inode->i_num = nr; read_inode(inode); return inode; }
read_inode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static void read_inode (struct m_inode * inode) { struct super_block * sb ; struct buffer_head * bh ; int block; lock_inode(inode); if (!(sb=get_super(inode->i_dev))) panic("trying to read inode without dev" ); block = 2 + sb->s_imap_blocks + sb->s_zmap_blocks + (inode->i_num-1 )/INODES_PER_BLOCK; if (!(bh=bread(inode->i_dev,block))) panic("unable to read i-node block" ); *(struct d_inode *)inode = ((struct d_inode *)bh->b_data) [(inode->i_num-1 )%INODES_PER_BLOCK]; brelse(bh); unlock_inode(inode); }
image-20231211131847124
将根文件系统与进程1关联,设置root和pwd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void mount_root (void ) { ... if (!(mi=iget(ROOT_DEV,ROOT_INO))) panic("Unable to read root i-node" ); mi->i_count += 3 ; p->s_isup = p->s_imount = mi; current->pwd = mi; current->root = mi; ... }
计算虚拟盘空闲块信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void mount_root (void ) { ... free =0 ; i=p->s_nzones; while (-- i >= 0 ) if (!set_bit(i&8191 ,p->s_zmap[i>>13 ]->b_data)) free ++; printk("%d/%d free blocks\n\r" ,free ,p->s_nzones); free =0 ; i=p->s_ninodes+1 ; while (-- i >= 0 ) if (!set_bit(i&8191 ,p->s_imap[i>>13 ]->b_data)) free ++; printk("%d/%d free inodes\n\r" ,free ,p->s_ninodes); }
至此mount_root执行完,同时返回后sys_setip函数也执行完了:
1 2 3 4 5 6 7 int sys_setup (void * BIOS) { ... rd_load(); mount_root(); return (0 ); }
返回到之前调用system_call的地方,一路返回到一开始的init函数。
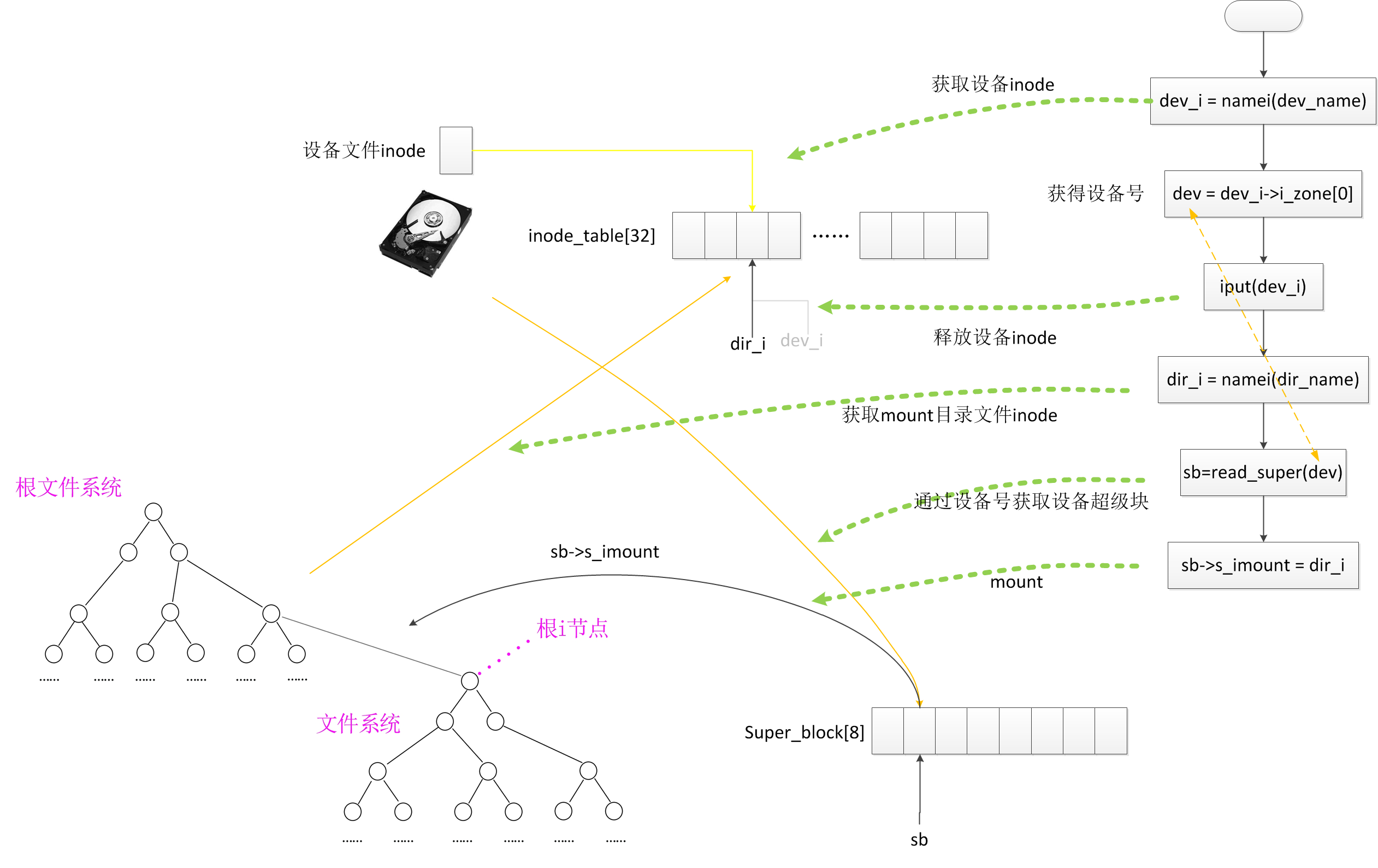
#### sys_mount
函数说明:除了根文件系统以外其它一般的文件系统挂载的流程。
完成挂载: 1.找到要安装的结点 2.找到要挂接的结点 3.连接
拿到设备号一定可以拿到超级块,把超级块加载到super
block数组里面——》安装文件系统 首先在获取设备i结点
此时再看copy_process 可以看出子进程复制了父进程打开的文件
进程0创建进程1的时候因为进程0的pwd和root都是空,因此进程1刚建立的时候还没有pwd和root
进程1是在current->pad=mi的时候才有的,后面的进程集成了基础1也有==(p= current)==
这个root不一定是根i结点的根
每个硬件设备都有一个引导块,每个逻辑设备都有一个超级块,如果一个物理设备有多个逻辑设备往后复制一下上图
iput 释放在inode_table[32]的结点 wait_on_inode:和 wait buffer 相似
get_super 在super block里面找同样的 iget
文件系统加载结点
首先获取设备inode,根据设备inode就可以获得设备号(然后这个结点就没有用了,iput释放)
目录文件的i结点指向目录文件。目录文件里面有目录项。根据目录项可以找到下一级目录文件的i结点
最后一个目录文件的i结点叫做枝梢i结点。通过枝梢i结点可以找到硬盘上包含要找的目录项的块,把这个块读到缓冲区,在缓冲区倒腾目录项都有那些内容。然后再把内容放到inode里面。这个结点最终要到inode
table32
还缺少imode :区分i结点是目录i结点还是文件i结点
dirt ,update位分析
对缓冲块的共享有两个方向:
进程方向:进程能共享哪些缓冲块,不能共享哪些
硬盘方向:哪些缓冲块需要同步到外设,哪些不用同步
缓冲块管理结构 buffer_head 的 b_uptodate 和
b_dirt 字段就是为了保证缓冲块和逻辑块数据的正确性
b_uptodate:针对进程方向。它的作用是告诉内核,只要缓冲块的
b_uptodate 字段被设置为
1,缓冲块的数据已经是最新的,可以放心地支持进程共享缓冲块的数据;反之,如果设置为
0,就提醒内核缓冲块数据并没有更新,不支持进程共享该缓冲块。
需要特别注意 的是,b_uptodate 字段为 1 并不代表缓冲块的数据跟块设备逻辑块上的数据是一致的,它们可以不一样。。
申请逻辑块是一种特殊情况。将 b_uptodate 字段设置为 1 只是表明该缓冲块的数据是最新,进程可以直接读或写,但并不意味着缓冲块的数据跟逻辑块的数据是一致的。设想将
b_uptodate 字段设置为
0,进程以为该缓冲块数据不是最新的,就会从逻辑块将数据读入,而此时逻辑块数据并没有清零,读入的必然是垃圾数据。另外,因为是新建逻辑块,内核不会去读该逻辑块,只会向该逻辑块写数据,所以当该缓冲块的
b_dirt 字段为 1
时,将缓冲块数据同步到该逻辑块自然能够覆盖掉该逻辑块之前的垃圾数据。
b_dirt:针对硬盘方向。只要缓冲块的 b_dirt 字段被设置为
1,就是告诉内核,这个缓冲块中的内容已经被进程修改过,需要同步到块设备上;反之,如果为
0,不需要同步。b_uptodate 字段设置为 1
后,内核就支持进程共享该缓冲块的数据,读写都可以。读操作不会改变缓冲块的数据;但写操作会改变缓冲块的内容,需要将
b_dirt 字段设置为 1,标志该缓冲块需要同步。
在buffer init的时候会初始化:
1 2 3 4 h->b_dirt = 0 ; h->b_count = 0 ; h->b_lock = 0 ; h->b_uptodate = 0 ;
在getblk的时候,如果没有找到现成的缓冲块,从空闲区域找到后会对块操作:
1 2 bh->b_dirt=0 ; bh->b_uptodate=0 ;
缓冲块的同步有两种方法:一种是 update
进程定期同步;另一种是因缓冲区使用达到极限,操作系统强行同步。这两种同步方法最终都会调用
sys_sync 函数
uptodate 创建新文件的时候uptodate直接置1
static 和inline分析
Linux 0.11 里面的
inline 问题
去掉inline行不行?原理是什么? #### C程序运行结构
内存:代码区,静态数据区。动态数据区 cpu:eip(指向下一条指令)
ebp(栈底) esp(栈顶指针)
函数调用时,参数入栈顺序,从右向左),函数调用的时候首先将传参压入数据栈中。
然后将函数执行完的返回地址压栈,保存main函数的栈底(压栈),ebp挪到fun函数栈底,运行函数程序
函数局部变量压栈。
函数返回,根据栈中内容恢复现场,函数传参已经没用了,进行清栈。
用的是用户栈,是共用一个栈:理由copy page tables
进程0完全复制给进程1了,因此物理内存是一个物理内存,线性地址空间不一样,但是物理空间一样,所以可以看成共用一个栈,当发生写时复制才变两个栈,因为进程0本来是可读写的所以没导致copy
on write 所以还是共用了一个栈。 注意:进程0的压栈没有导致写时复制
为啥卡在pause?
因为进程0压栈了fork和pause的返回地址,但是fork返回了就清栈了,所以现在栈里面就是pause所以fork跳出来的时候返回到pause里面去了
有没有可能跑对?有可能
为啥有的时候行有的时候不行,因为操作系统调度是根据时间片进行的,而不是指令数。时间比较依赖cpu
硬件或虚拟机类型 当前进程有tss switch to 里面也有一套tss ============|
======== c 运行的程序 | ST 里面 TSS(0) |TSS(1) CS.EiP |cs.eip
进程1第一次运行,他的运行状态记录tss是否存在?存在。是在父进程创建的时候就被创建出来,不然开始运行的时候不知道从哪里开始运行。进程1返回的时候,eip(__res_)在用户态
有两个验证: 1.iret 2.在trap设置里面设置了特权级是用户态。
## 小结 1. 进程0从哪里蹦出来的: move to usermod
2.taskstruct 是共用体前端,和内核栈在一个union ,分配了一个页:4k,task struct一般也就1k,也就是说,内核栈再怎么用页不会超过3k。注意一个进程有两个栈,调用fork的时候跑的是用户栈,copyprocess的一系列操作的时候用的是内核栈。
init 80
在用户态执行,fork进程0压栈五个,进的是内核栈还是用户栈?内核栈。进程0用户栈:user
stack 压栈最本质是为了配合iret执行,iret在内核态
假设有inline在int 80
返回之后有可能出时钟,这个时钟里面也有一堆call这会不会把fork里面的那个返回值搞乱了?不会。do
timer来了以后在内核态,用的是内核栈,fork的返回值在用户栈里
get free page 获得空闲页不是共享页,get free
page是物理地址上还是线性地址上?获得的是线性地址,但是获得的是物理页。为啥是线性的地址?
cr3时物理的,页目录表里面要指向一个页表,这里也是一个物理地址(20位),页表有1k的页表项里面指向的也是物理地址,
p=(strict
task_struct*)get_free_page(),这里面得到的页是线性地址,这里的页面有没有挂到页表里面?挂过了,在head.s里面就挂了。挂到页表和用过是不等价的,只有memmap的引用计数可以看出来有没有用过
进程1能不能访问到自己的task
struct的那个页?。不可以,这个页挂在了进程0的页表上,进程1用不了,进程1的页目录表:64M-128M上没用挂过这个页
8.是不是所有的get free page用户程序都访问不了?:不一定
get free
page是从后往前遍历?这样映射关系就变得不那么线性了,增加安全性,物理地址和线性地址的映射关系就会更复杂一点。
没有一个脱离进程的绝对的内核,内核是进程的内核态
时间片在内核态和用户态都在跑,详见do_timer
in32
里面又的指令是绝对特权的,在0特权级列表里面,还有一些是通过IOPL设定他能不能被用户态度操作的
,在init
task里面的eflags=0的时候设定的,此时IOPL也被清零了。因为存在父子进程创建机制,因此后面所有进程的eflags都等于0
要用逻辑体系的思维保证滴水不漏
为啥都从fork出来
main函数代表内核,一般肯定不能走完,结束前肯定有一个死循环:for(;;)pause();
这个死循环谁做:进程0
进程0:进程的祖宗,当其他进程都不动的时候进程0怠速状态idle
由进程0负责让操作系统不熄火。所以说,创建进程在fork,怠速在pause
那其他进程只能从fork出来了,linux的设计思想