图像分割
图像分割分类

语义分割:每一个像素必须且只能属于一类,预测结果为掩膜
实例分割:只预测前景目标的类别属性以及边框,个体ID,每一个像素可以属于多个ID
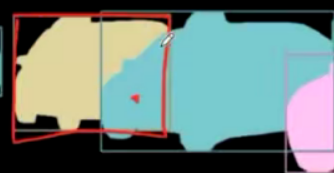
比如上面所示因为有遮挡所以每一个像素可以属于多个ID
全景分割(panoptic segmentation)每个像素点分配一个语义类别和一个唯一的实例ID
如果所有的类别都是stuff那么全景分割除了度 量,与语义分割相同。
全景分割中不允许重叠,但实例分割可以;实例分割需要每个分割的置信概率,但全景分割不需要。
经典数据集
pascal VOC
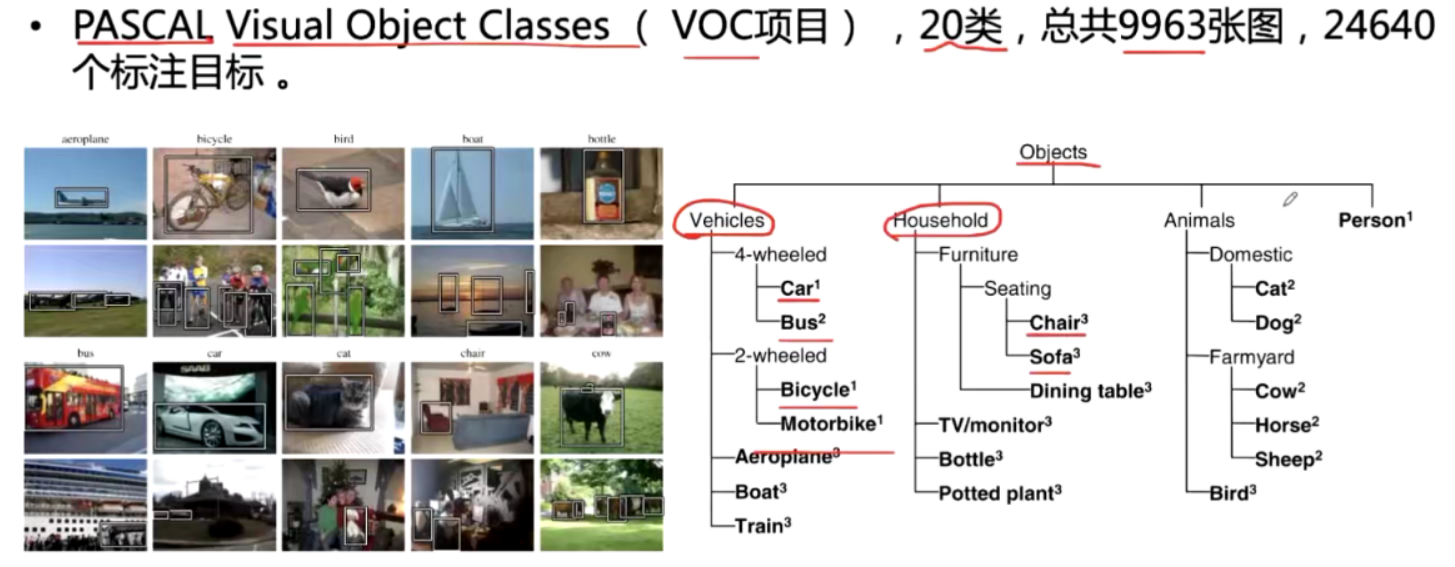
一共2913张图,1464张训练图片,1449张验证图片
Cityscape

5000张精细标注的图像(2975张训练图,立硏长验证图和1525张测试图)、20000 张粗略标注图像
COCO

共 91 类,以人类 4 岁小孩能够辨识为基准,其中 82 类有超过 5 000 个 instance。
评估指标与优化标准
评估指标
Pixel Accuracy 逐像素分类精度
\(\mathrm{PA}=\frac{\sum_{\mathrm{i}=0}^k p_{i i}}{\sum_{i=0}^k \sum_{j=0}^k p_{i j}}\)
Mean Pixel Accuracy 每个类内被正确分类像素数的比例
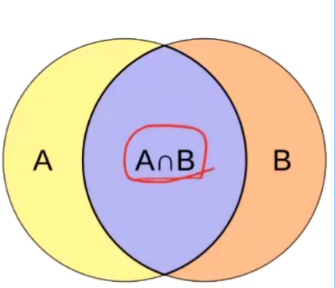
IOU :前景目标交并比。
\(I o U_0=\frac{\mathrm{A} \cap \mathrm{B}}{\mathrm{A} \cup \mathrm{B}}\)
FWIOU 每个类的 foU 平均值:根据每个类出现的频率给 mioU 计算权重
优化目标



上采样方法
上采样:得到语义分割的掩膜
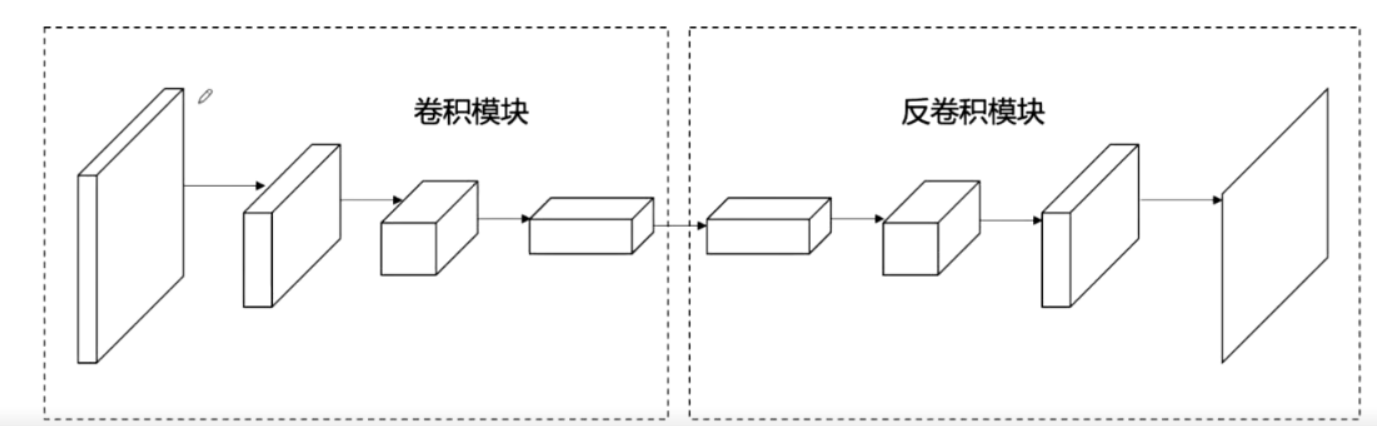
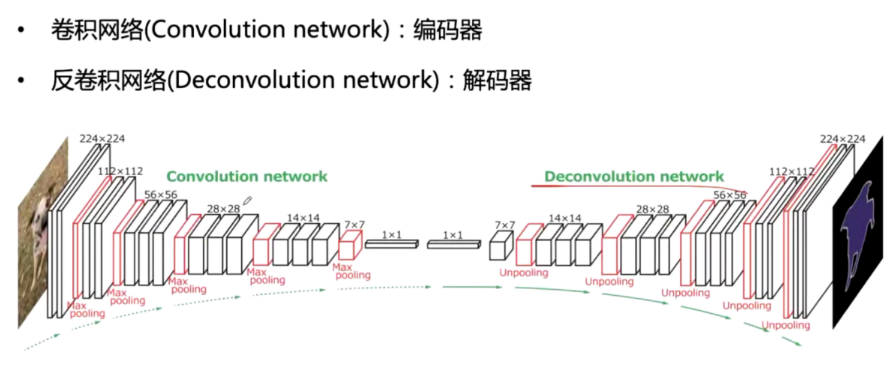
图像分割网络的两个模块卷积模块:
提取特征反卷积模块
上采样恢复到原图尺度
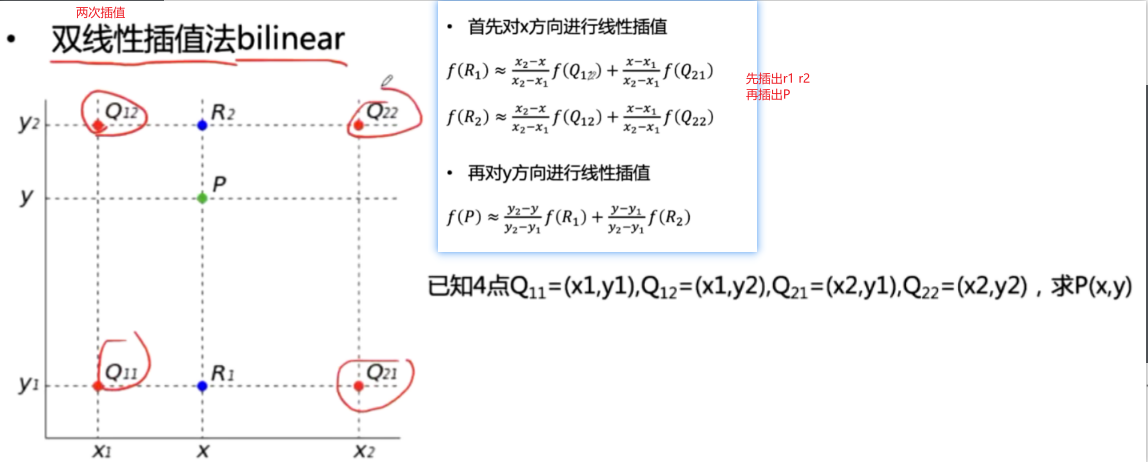
上采样实现一插值法
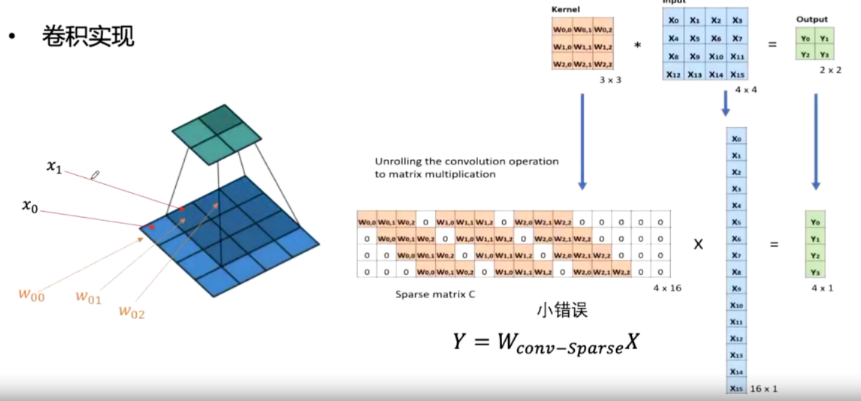
上采样实现一转置卷积
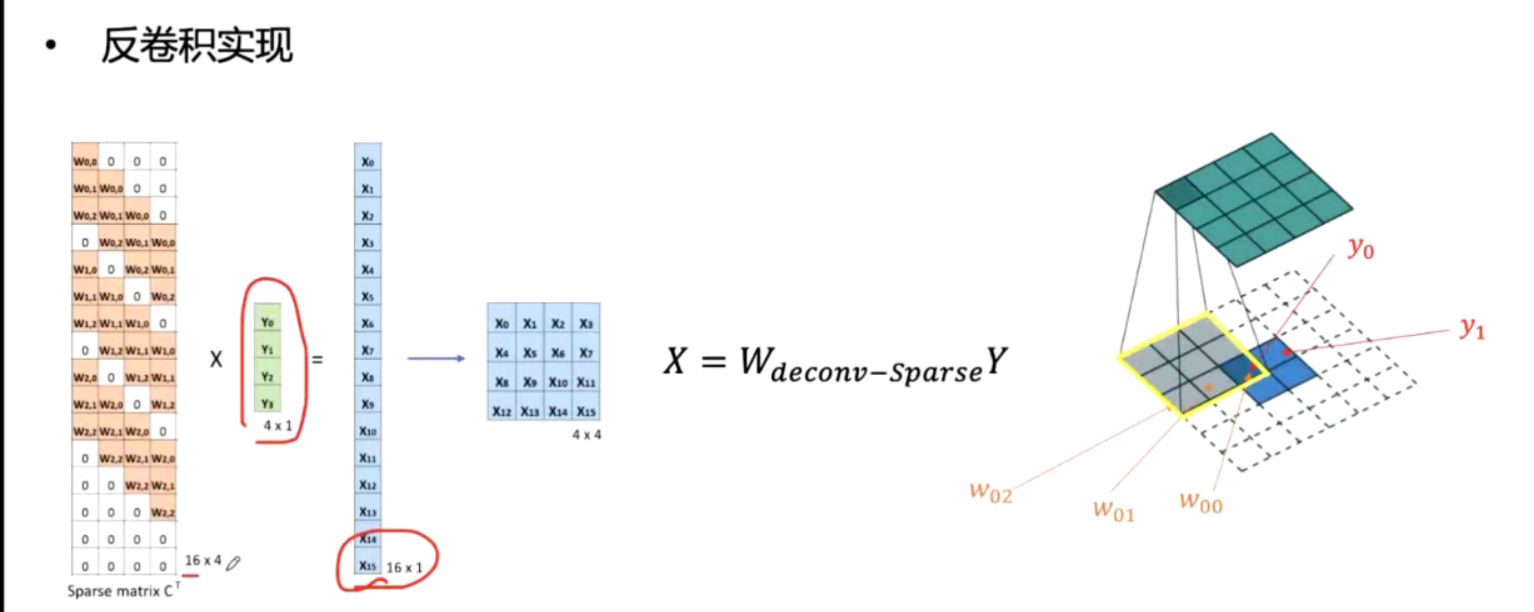
典型图像分割网络
语义分割经典模型
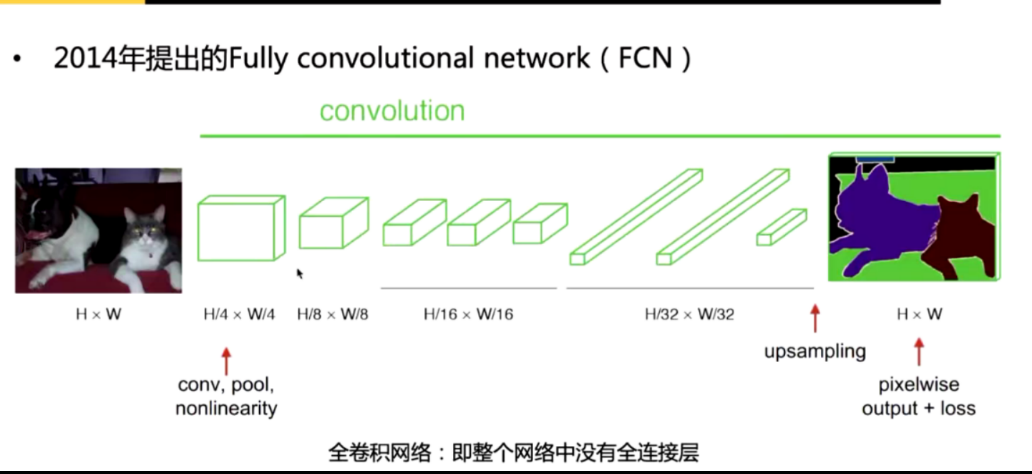
FCN (Fully convolutional network)
类似 VGG+双线性上采样
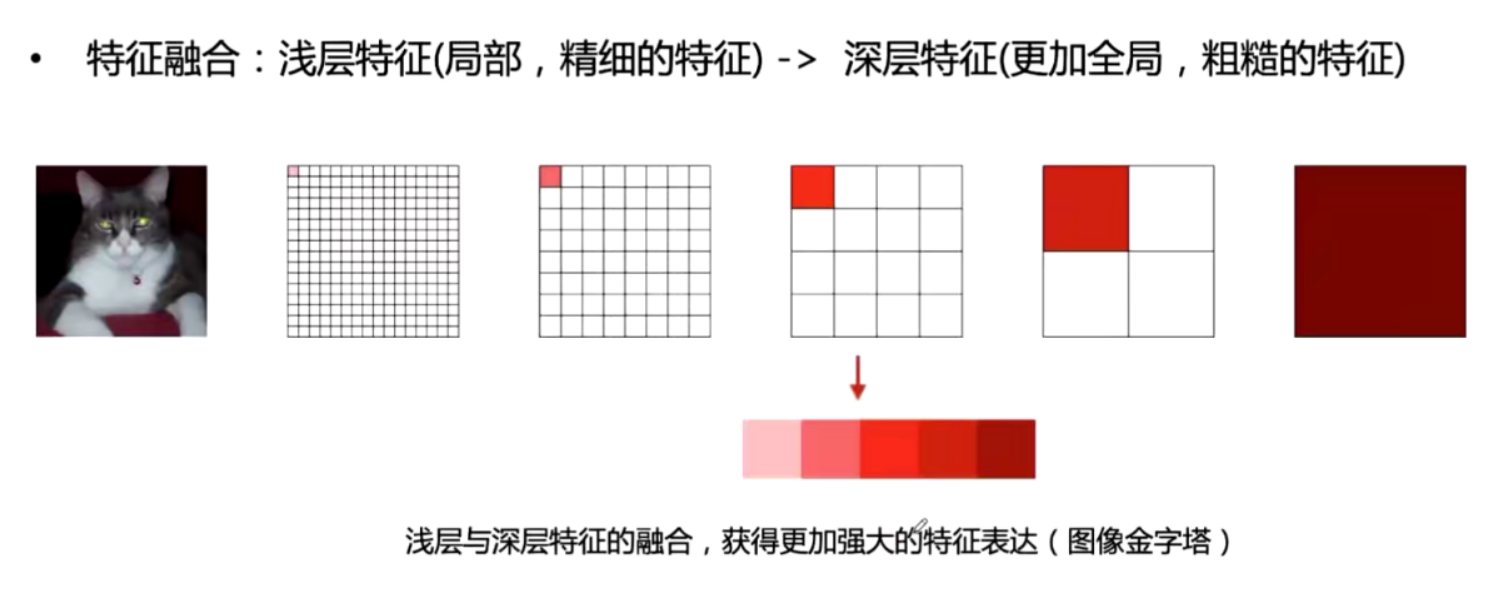
随着网络加深特征图越来越小,特征越来越抽象
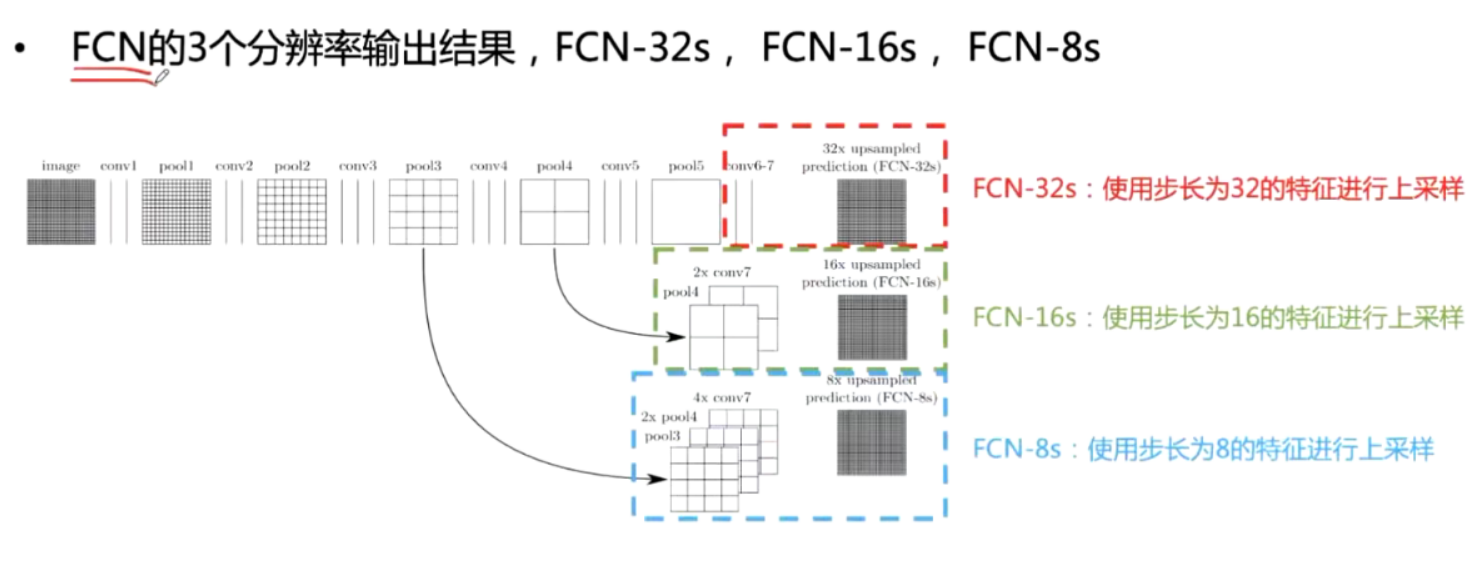
FCN32x:对conv7的预测结果进行32倍上采样(对应步长pool5)
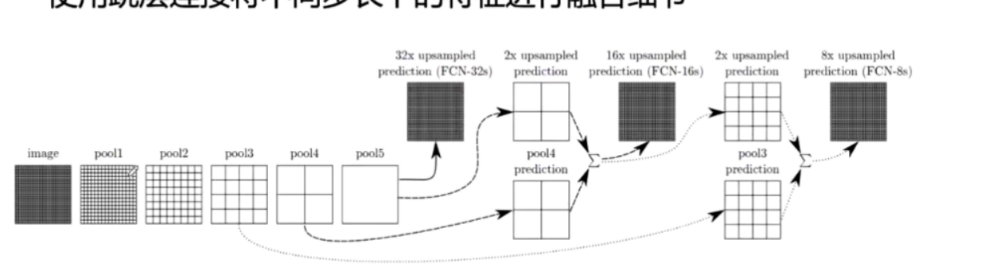
FCN16x·对conv7的预测结果上采样2倍,与poo14+conv预测结果相加,然后进行16倍上采样
FCN8x:对FCN16x预测结果上采样2倍,poo13+conv预测结果相加,然后进行8倍上采样
中间两个上采样使用双线性插值初始化并进行学习,最后一个上采样不学习
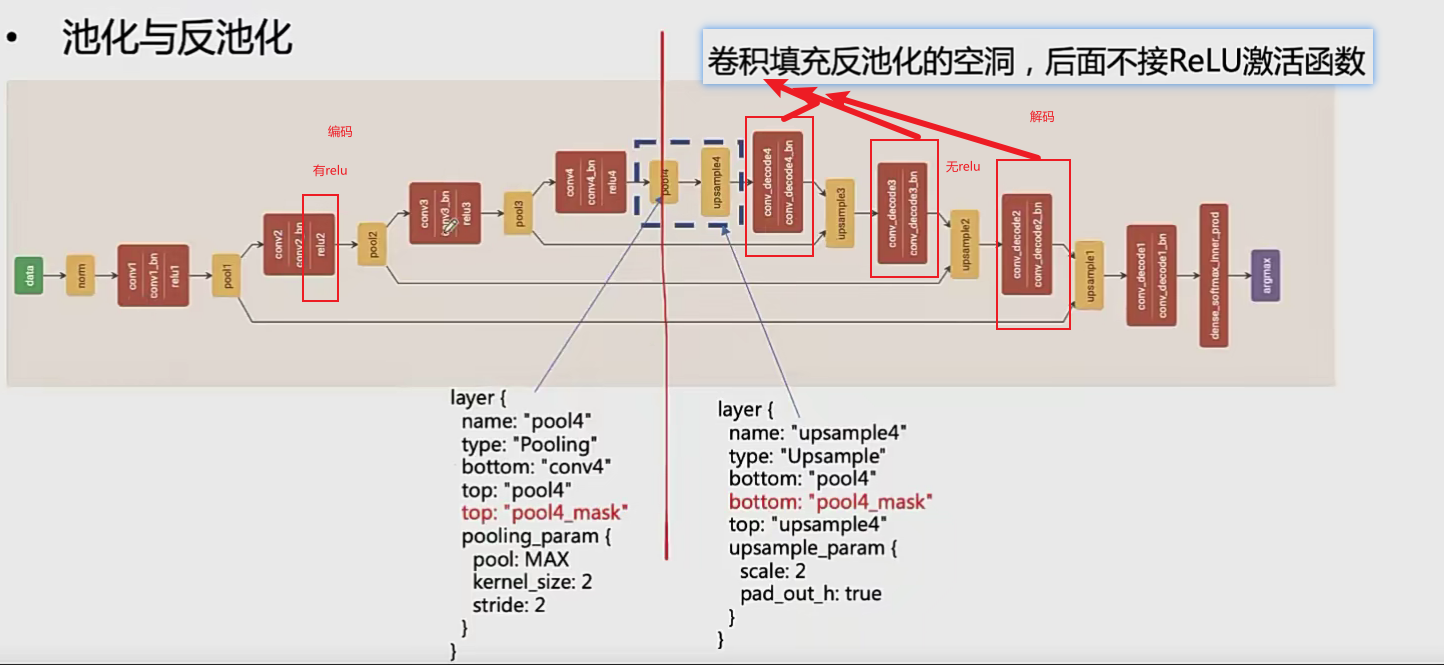
SegNet
SEGNET网络结构
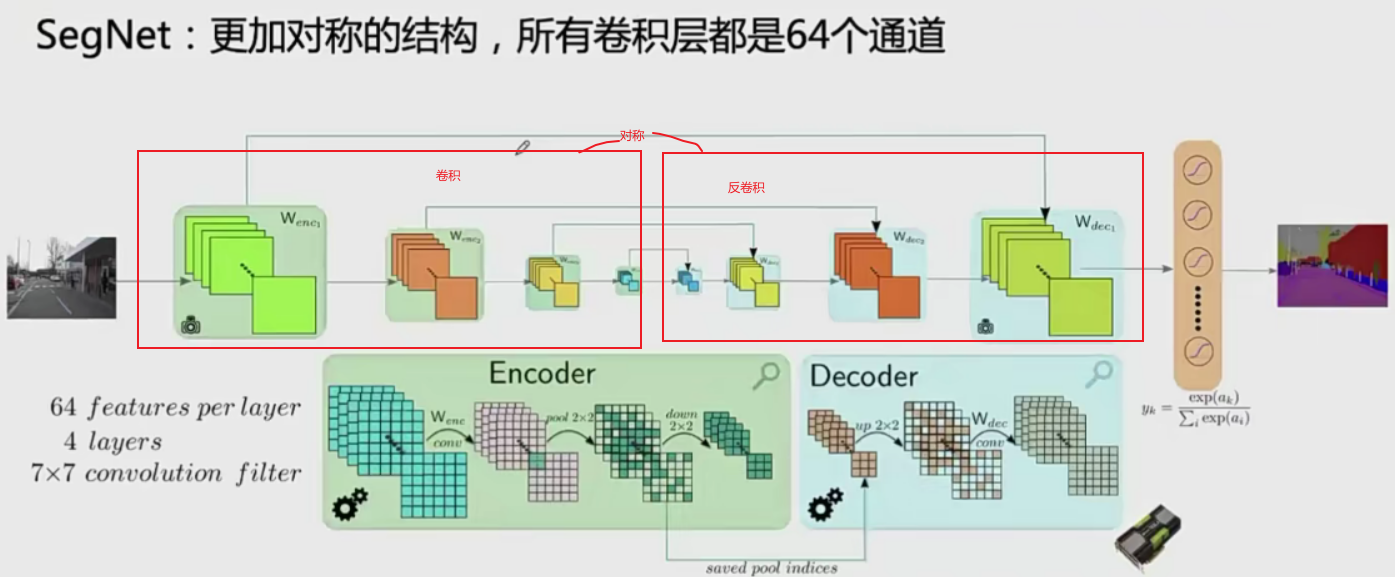
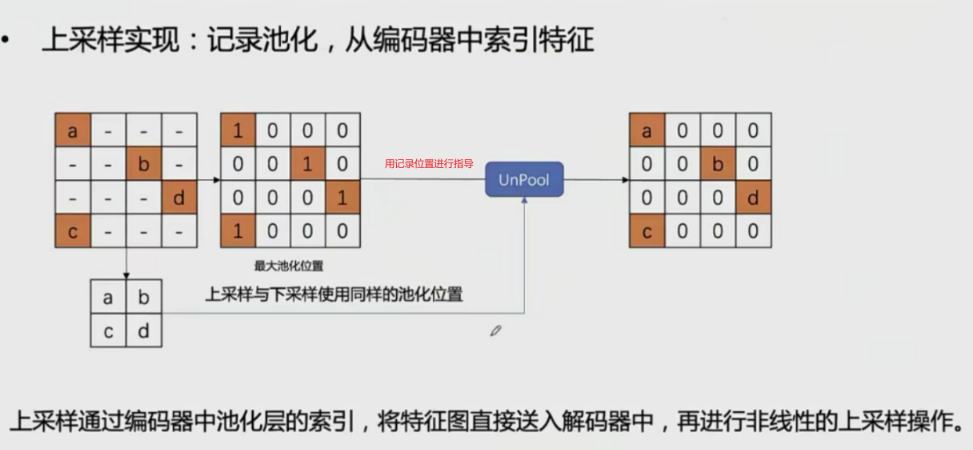
SEGNET网络细节
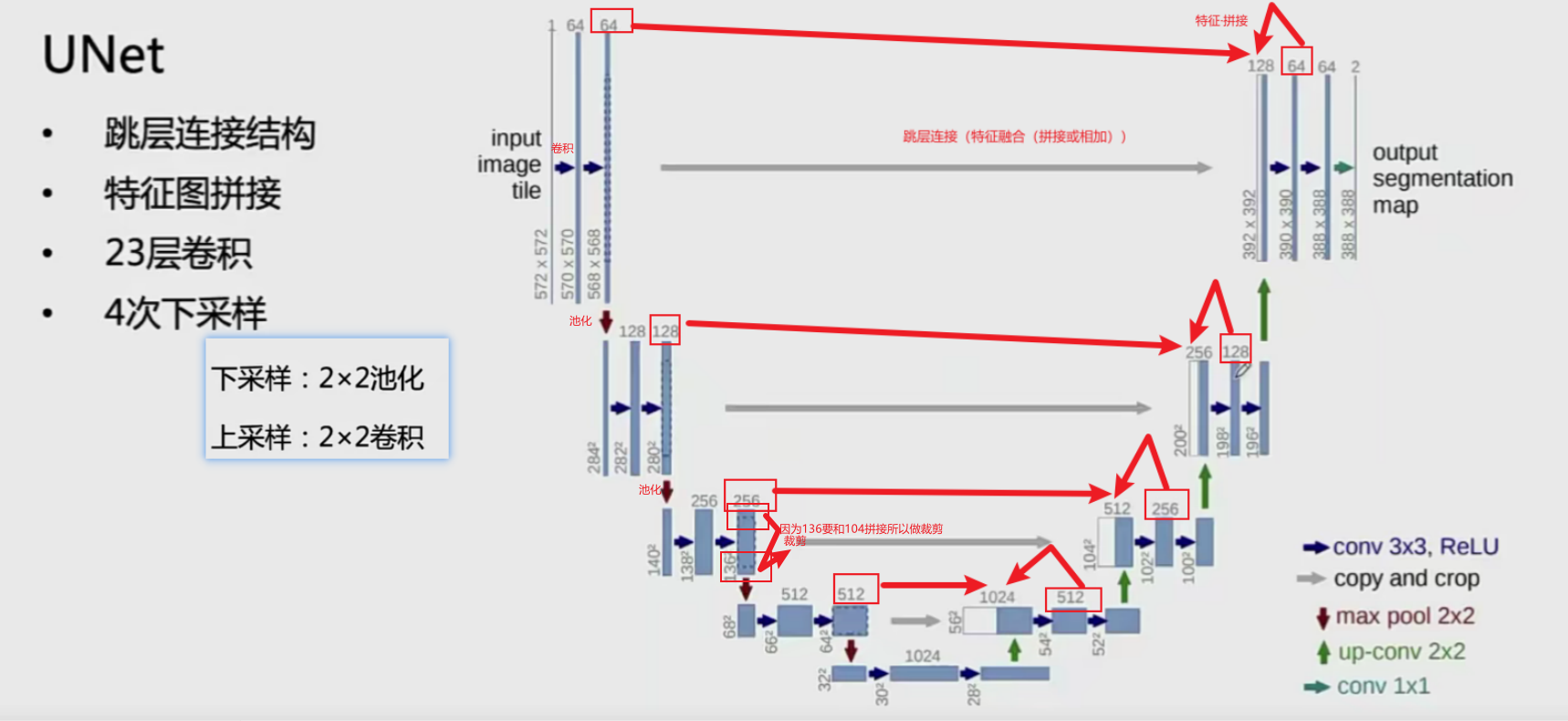
UNet
Unet结构:
语义分割模型改进
语义分割难题
- 分辨率问题

空间不变性:CNN分类的时候换一个位置分类还是相同的,但是分割问题要求不同位置的像素分类是不同的(比如两个人)
- 分类错误问题
相似形状与复杂纹理带来的分类错误
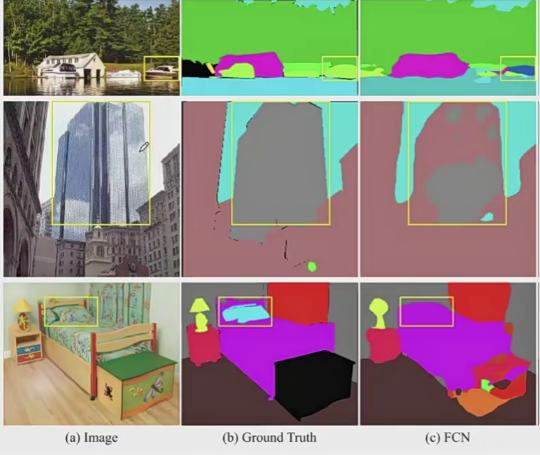
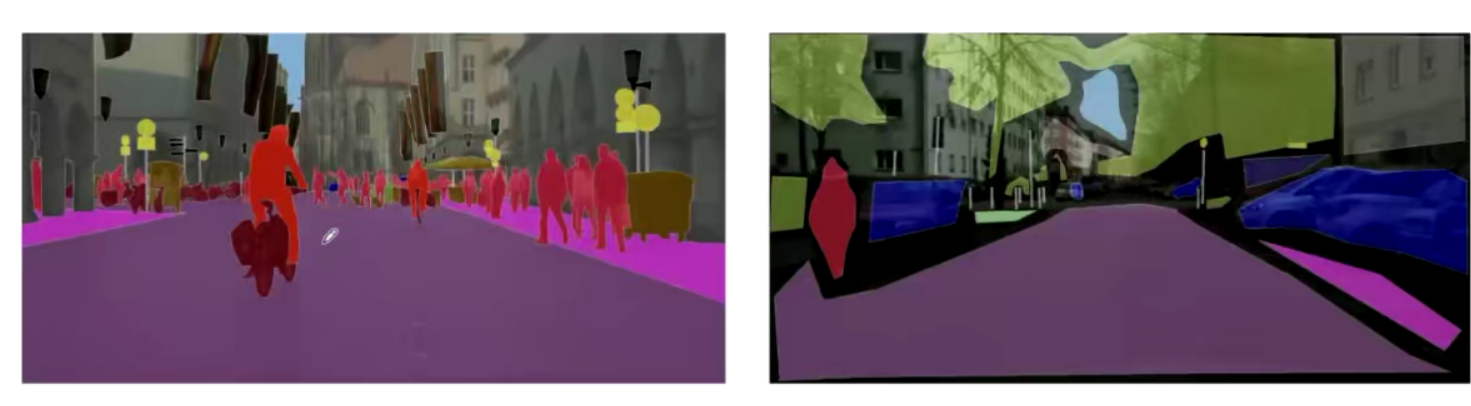
合理的先验关系(Mismatched Relationship)(如上图第一行,车在水里不符合先验关系) 混淆的类别(Confusion Categories) 不容易区分的类别(lnconspicuous Classes)
解决思路:
从更高分辨率的特征图开始恢复 利用充足的上下文信息(Cntext,感受野)
膨胀卷积(空洞卷积)
原来的\(3\times3\)卷积只能覆盖边界为3的区域,膨胀后覆盖的区域变大
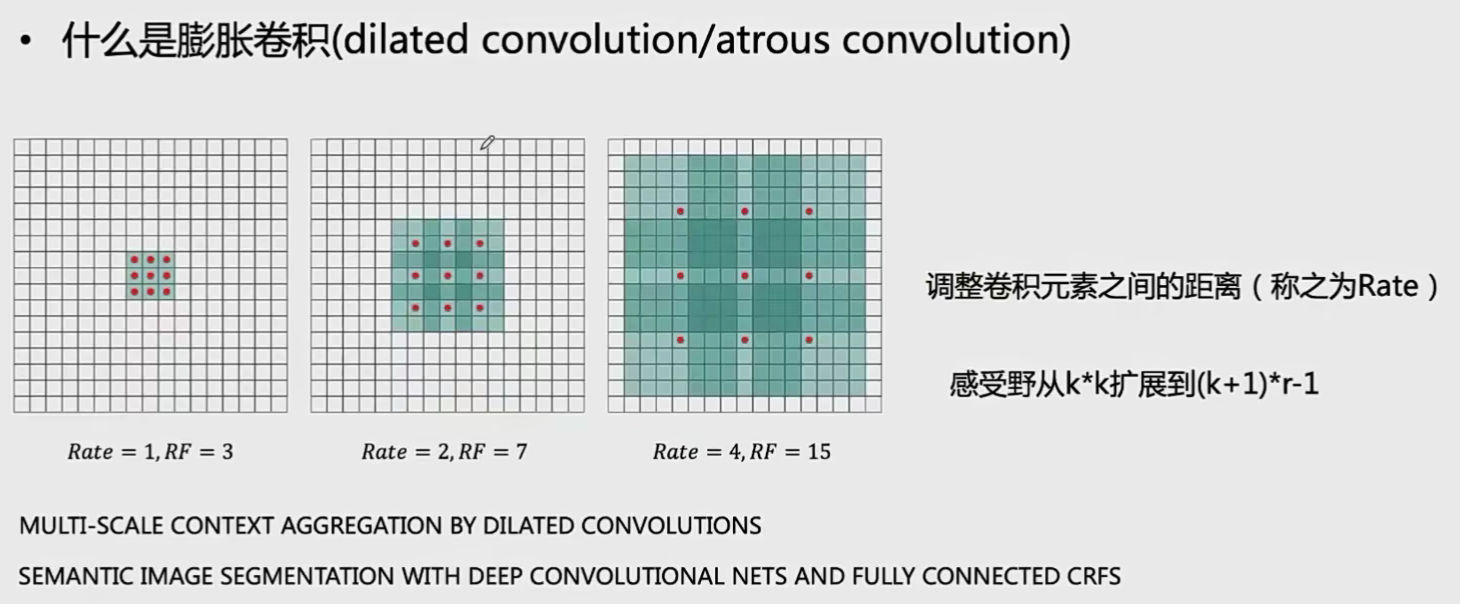
与其他曾加感受野的方法相比,膨胀卷积优势明显: 与使用更大的卷积核比较:有更少的卷积参数 与池化相比:保留了更大的卷积特征图 与增加网络深度比较:有更少的网络层和计算量
膨胀卷积结构设计
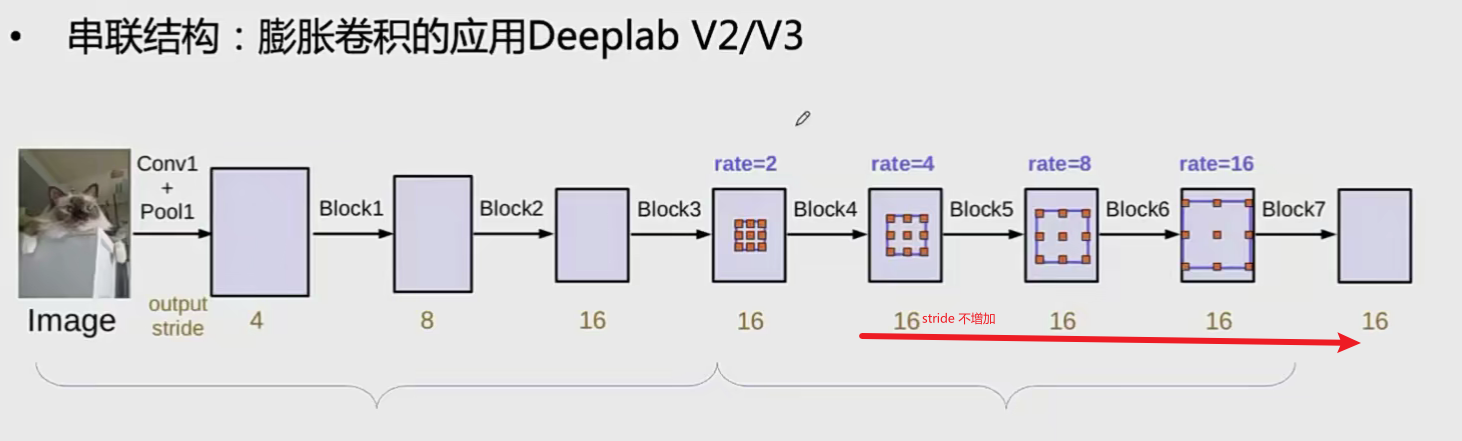
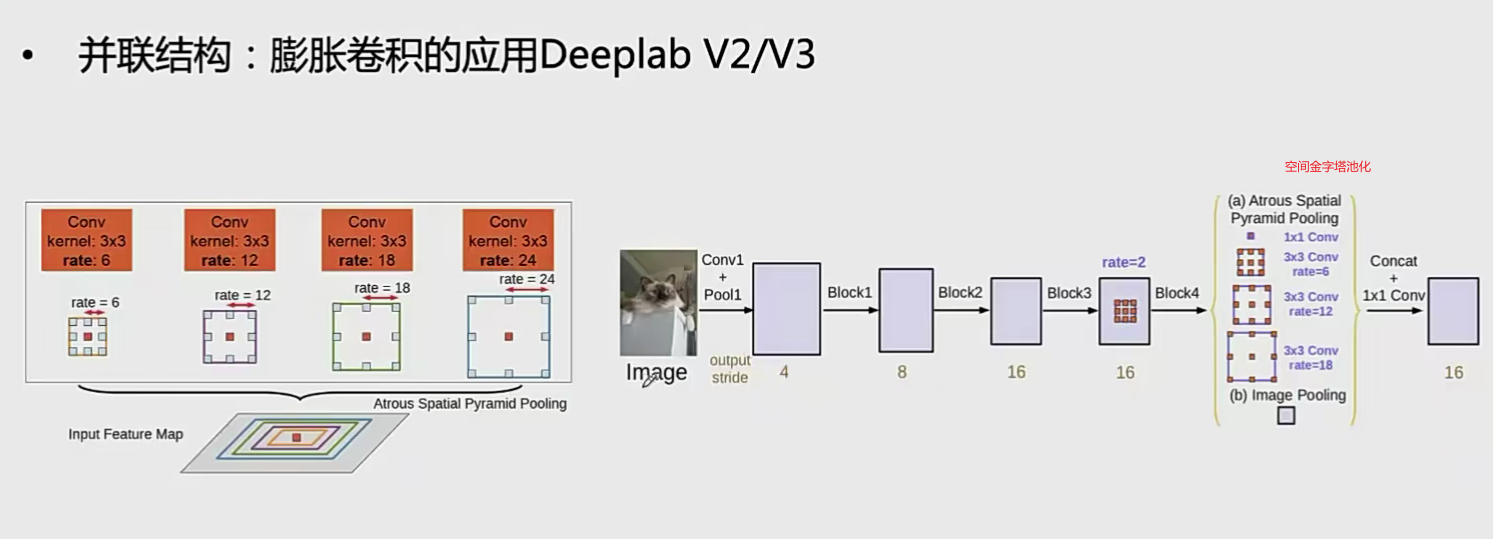
应用:
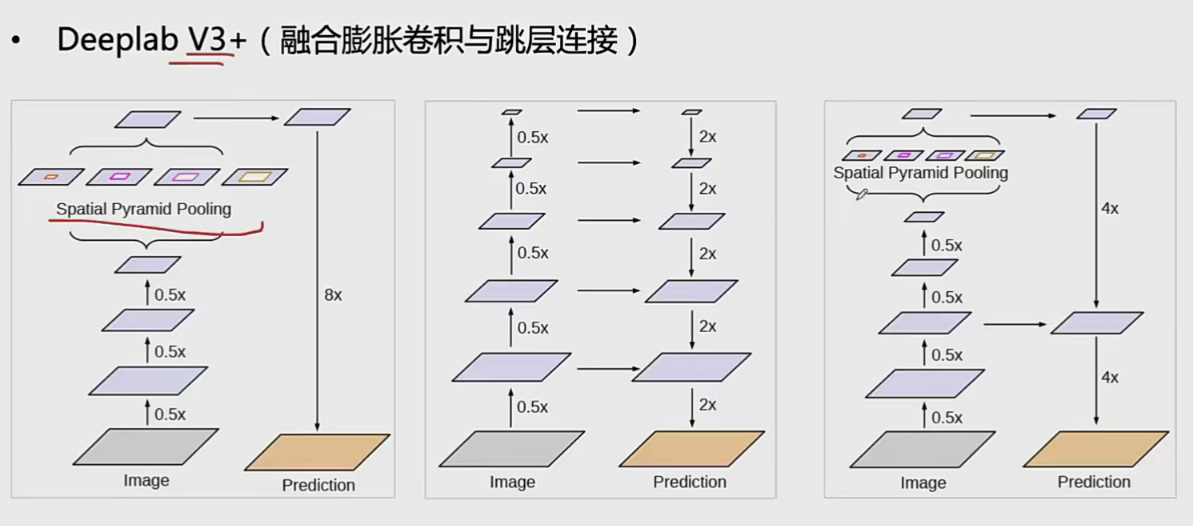
可变形卷积(deformable conv)
!(./图像分割/image-20230108102615922.png)
多尺度特征融合框架
parseNet
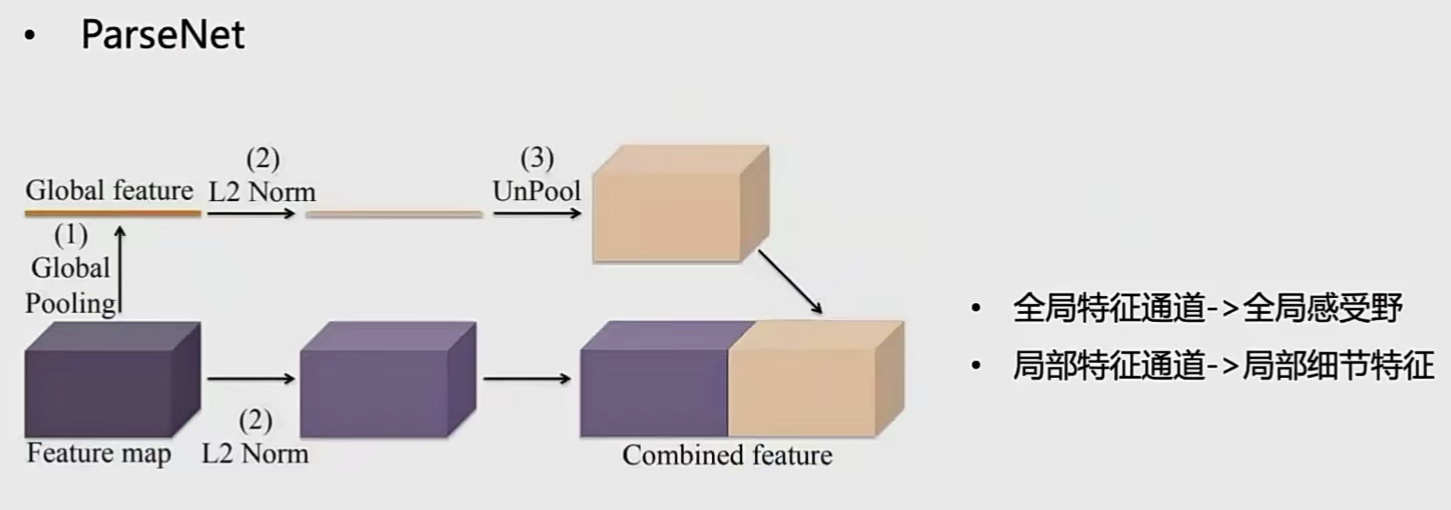
全局特征与局部特征融合
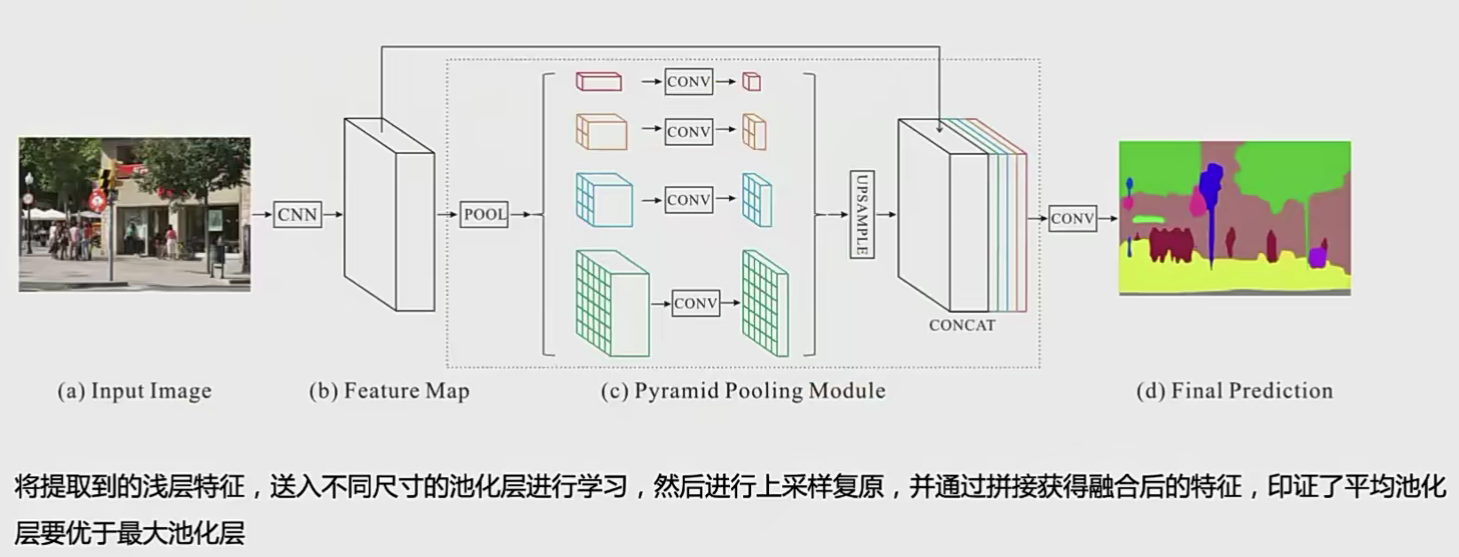
PSPNet(金字塔池化)
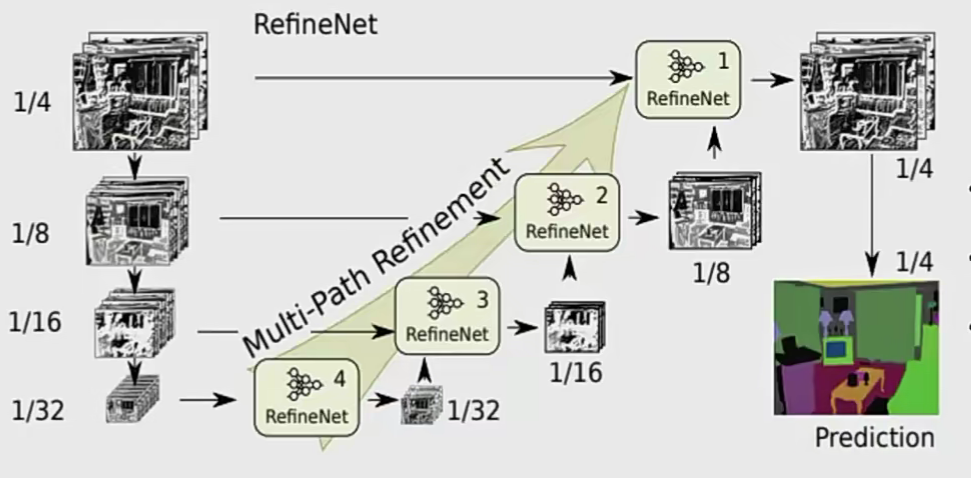
RefineNet
逐层进行多种分辨率的特征图融合
- 首先用卷积层获得尺寸不变的特征
- 然后使用上采样操做将所有特征图扩展为尺寸相同的特征图
- 最后使用求和操作融合所有的特征图
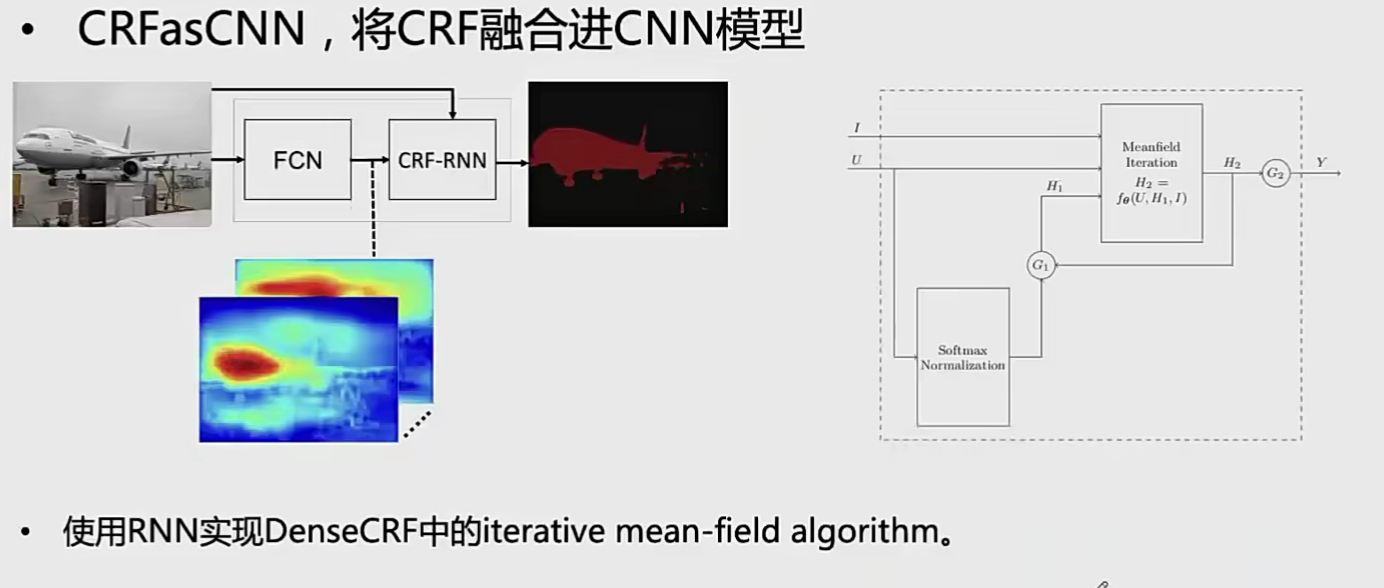
CRF
cnn的缺陷
CNN是对每一个像素单独进行预测,没有更好的考虑像素间的关系。
经典的cnn是局部的方法,即感受野是局部而不个图像 cnn具有空间变换不变性,这也了降低了分割的边缘定位精度
CRF 原理
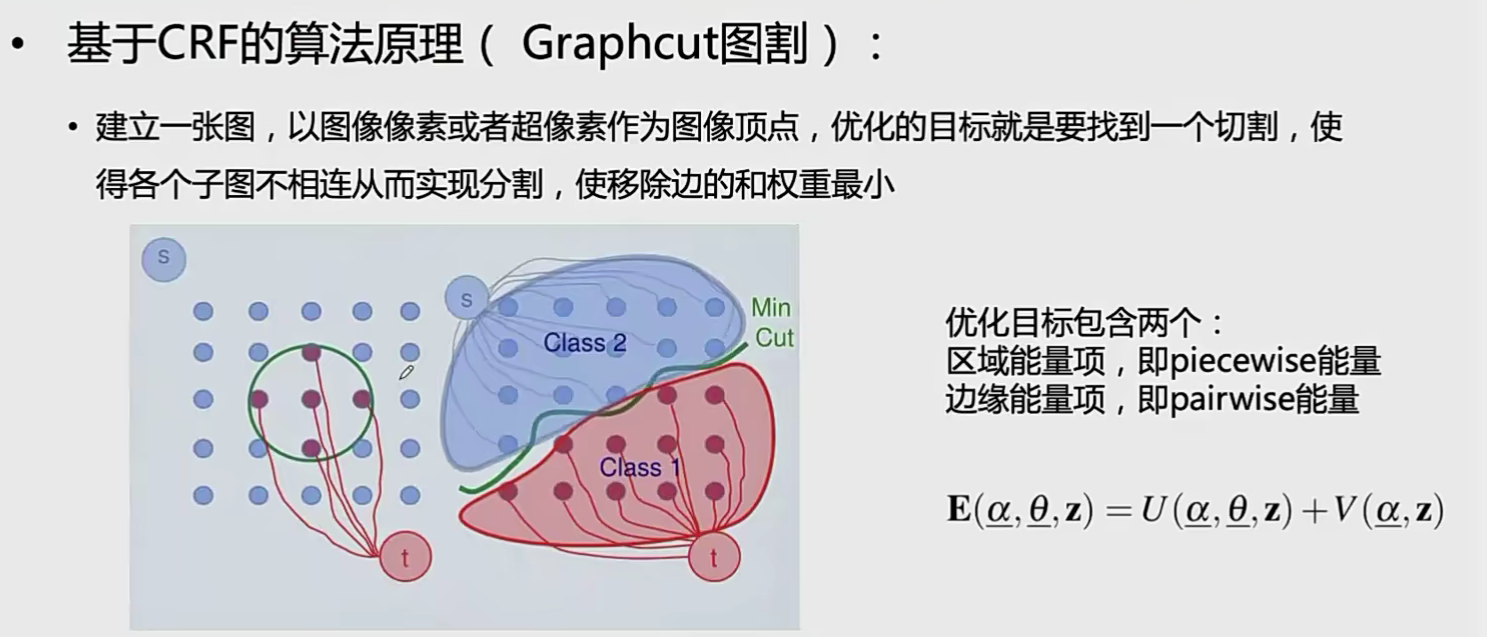
区域能量项:picewise
相同区域的像素分到一起(类似聚类)
一般使用直方图或混合高斯模型:
属于同一个目标的,颜色一般会比较一致
$U(, , )=_n-h(z_n ; _n) $
\(\quad D\left(\alpha_n, k_n, \underline{\theta}, z_n\right)=-\log \pi\left(\alpha_n, k_n\right)+\frac{1}{2} \log \operatorname{det} \Sigma\left(\alpha_n, k_n\right)\) \(+\frac{1}{2}\left[z_n-\mu\left(\alpha_n, k_n\right)\right]^{\top} \Sigma\left(\alpha_n, k_n\right)^{-1}\left[z_n-\mu\left(\alpha_n, k_n\right)\right]\)
边缘能量项:pairwise
衡量两个不相同区域的相似性的
平滑能量项(如果是不同目标,就应该取不同的标签,如果取了相同的标签,就给一个惩罚:
\(\exp -\beta\left(z_m-z_n\right)^2\)
\(V(\underline{\alpha}, \mathbf{z})=\gamma \sum_{(m, n) \in \mathbf{C}} \operatorname{dis}(m, n)^{-1}\left[\alpha_n \neq \alpha_m\right] \exp -\beta\left(z_m-z_n\right)^2\)
CRF的使用
- 直接分步后处理。将其用于处理cnn网络的输出。例如:
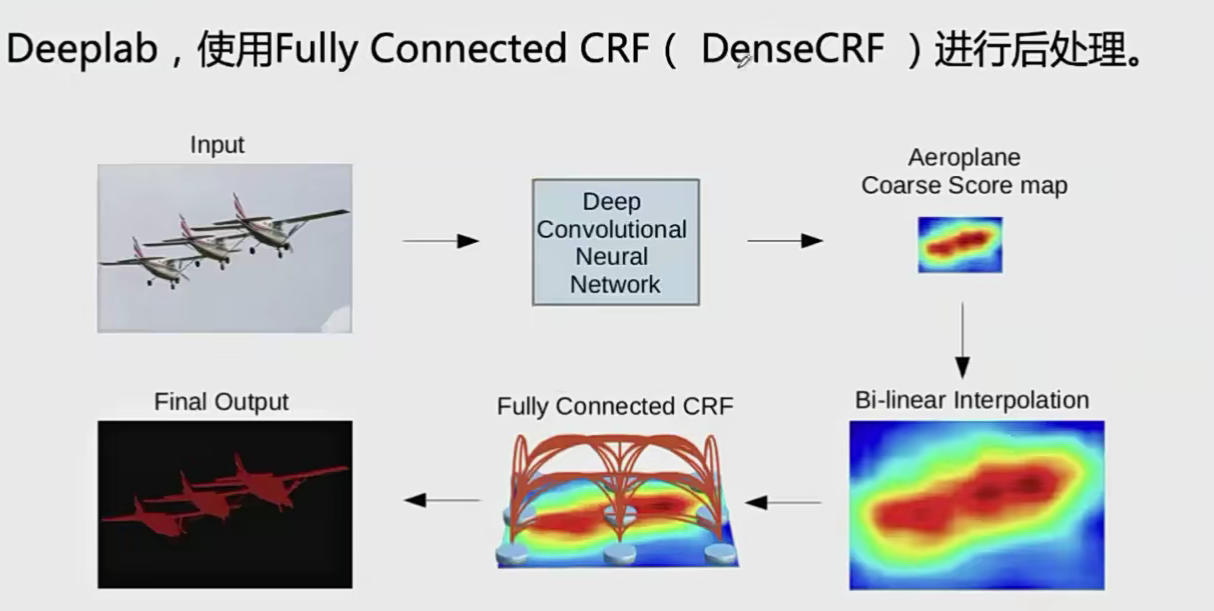
- 直接融合进cnn的框架。如牛津大学Torr-Vision提出的crf as Cnn在边缘定位精度取得很大提升