经典神经网络学习笔记
写在前面:本文是阅读有三AI博主课程的笔记
AlexNet
- 更深的网络结构
- 使用卷积层+卷积层+池化层提取图像特征
- dropout
- 数据增强
- RELU替换sigmoid
- 多GPU训练
训练技巧
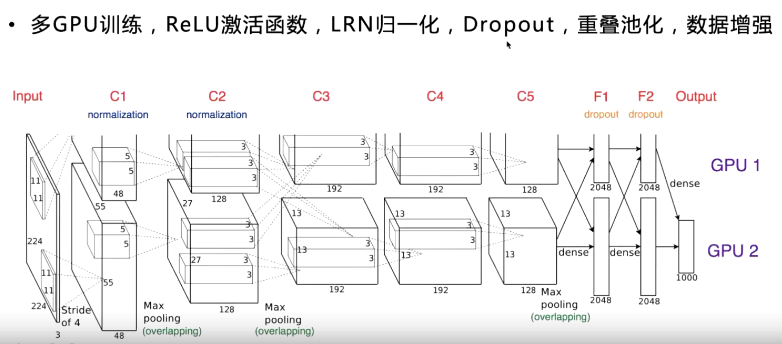
多GPU训练:(与只是用一个GPU想不,top-1和top-5的错误率减少1.7%和1.2%)
使得神经元并行,并使通信限制在了某些网络层。从上图中可以看出,c1,c2层是独立的,c4,c5是独立的,c3层两个GPU有通信

Dropout
随机裁剪一部分神经元,每次裁剪后生成的网络结构都不一样,通过组合多个模型的方式能有效减少过拟合
数据增强

VGG
小卷积
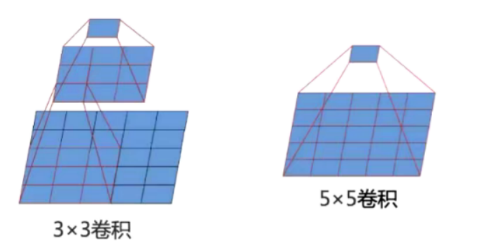
33卷积卷两次得到的图的大小和进行一次5 5卷积得到的大小一样
使用3*3卷积的优点:
1.网络层数增加因此非线性表达能力更强
2.网络层参数减少 (2 * 3 * 3 =18 5* 5 =25)
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
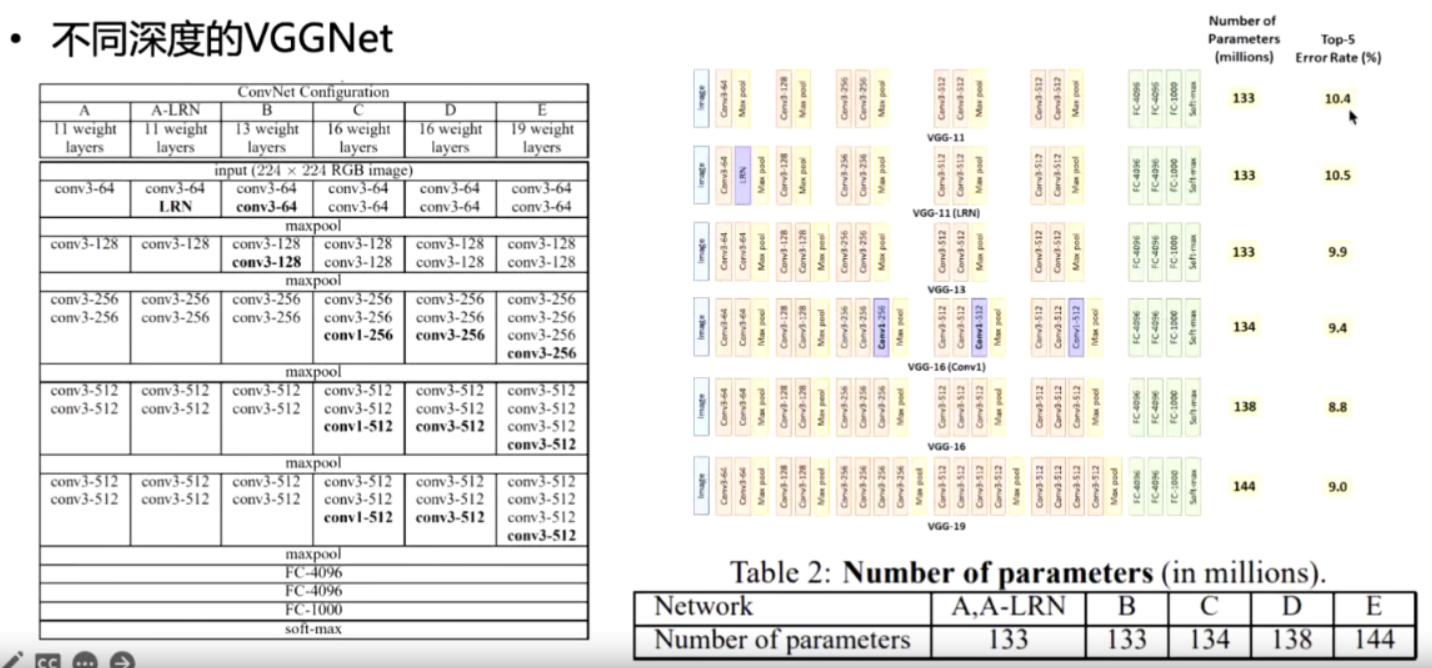
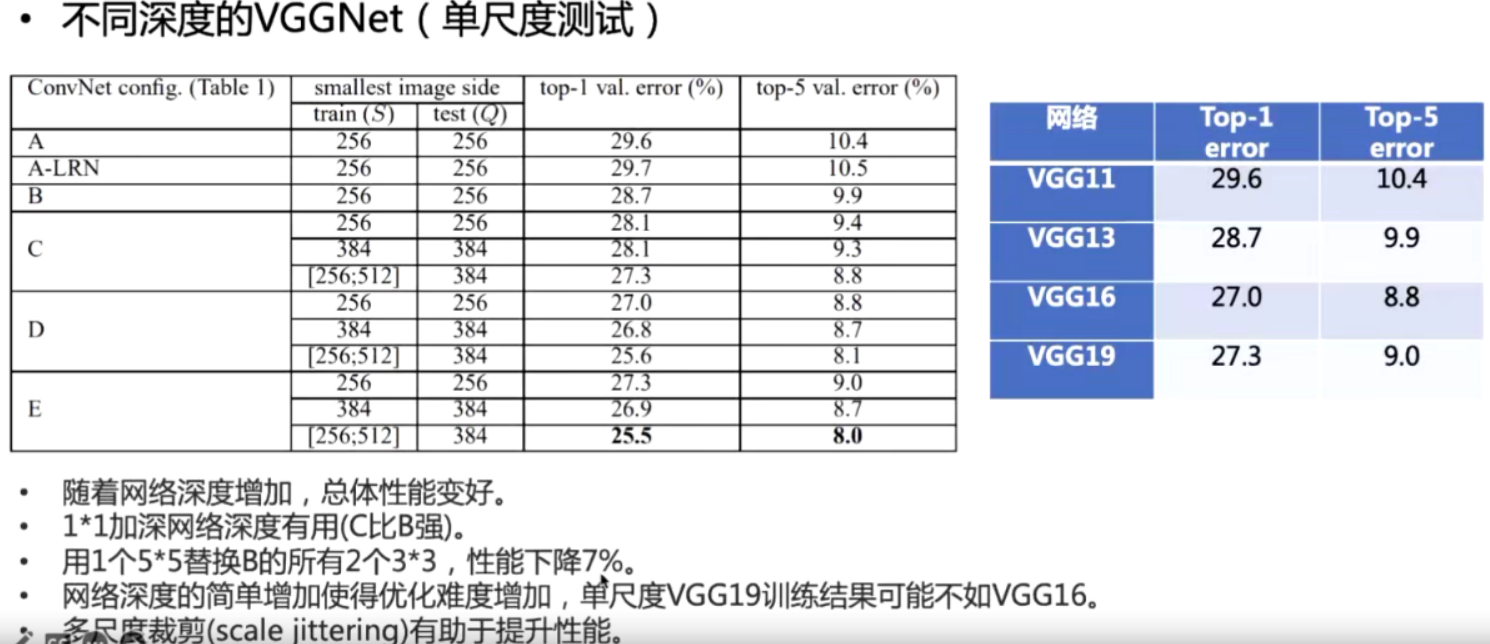
19的性能没有明显的优势
GoogLeNet
比VGG更深,但是参数量更少
背景
1*1卷积
RGB转灰度
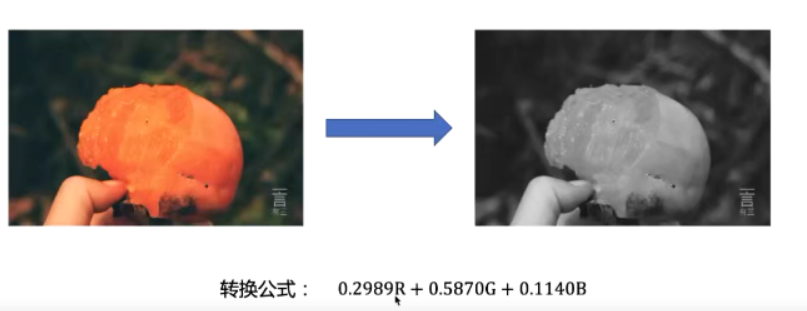
使用1* 1卷积层可以实现上述转换
1*1 卷积的作用
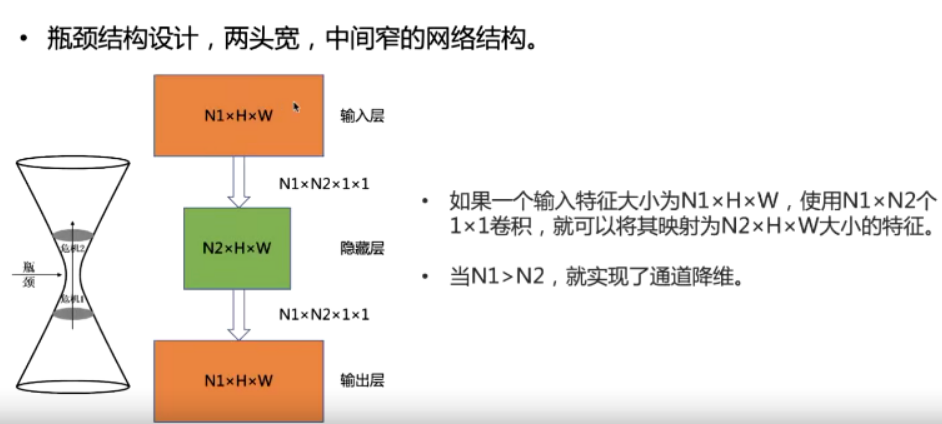
降维以后可以进行一些计算,降低参数量
1*1 卷积实验

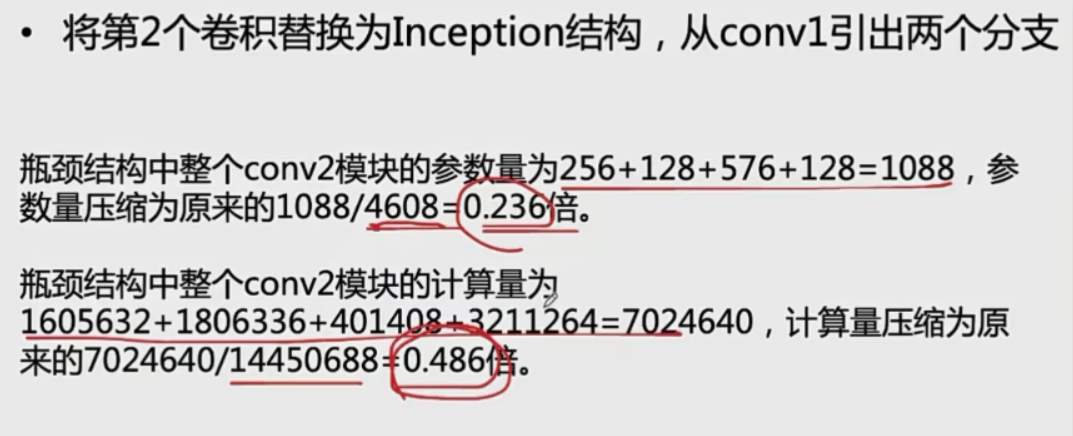
引入\(1\times1\)卷积之后


incption Module
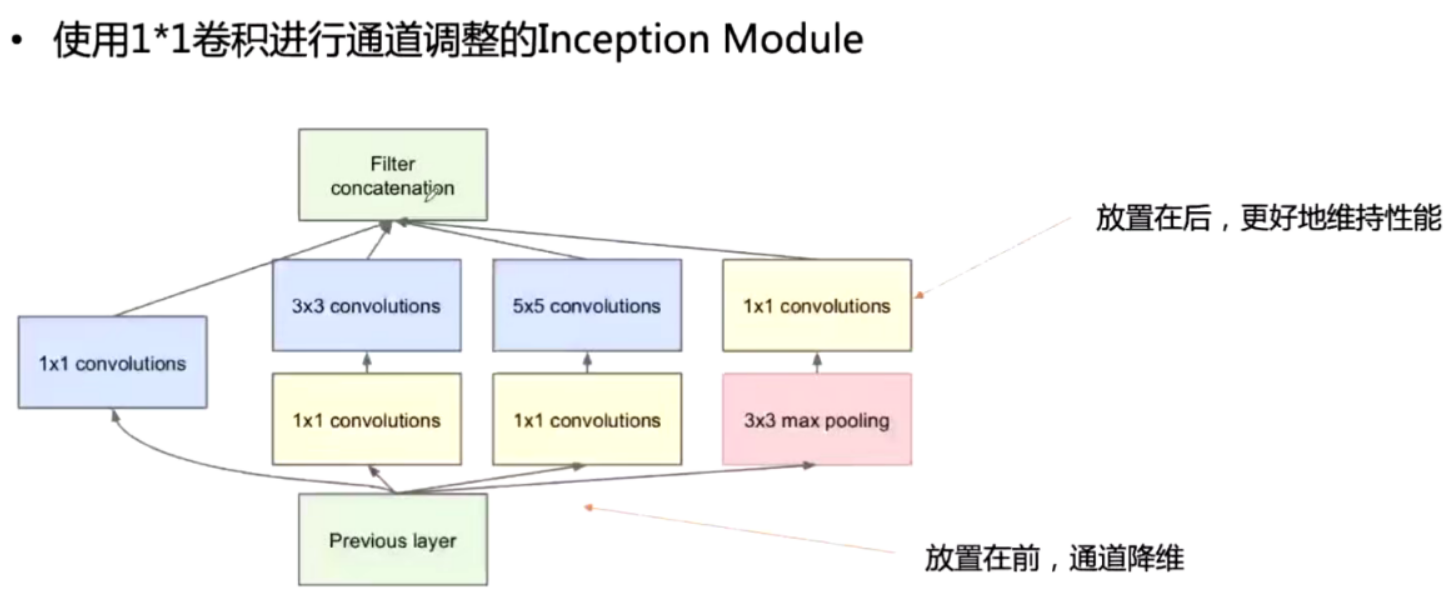
对于同一张图片,不同尺寸的卷积核的表现效果是不一样的,因为他们的感受野不同。Inception便能够满足这样的需求,一个Inception模块中并列提供多种卷积核的操作,网络在训练的过程中通过调节参数自己去选择使用。
Resnet
short connect
残差网络有效性
- 从信号角度

- 从集成角度看
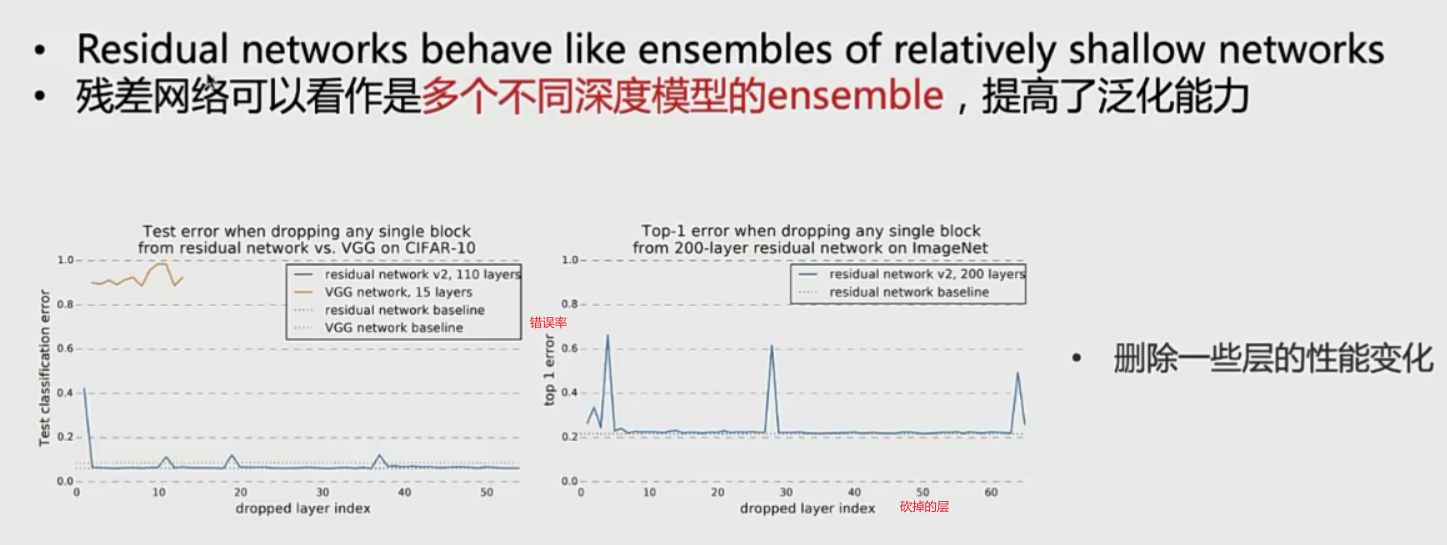
从模型结构看
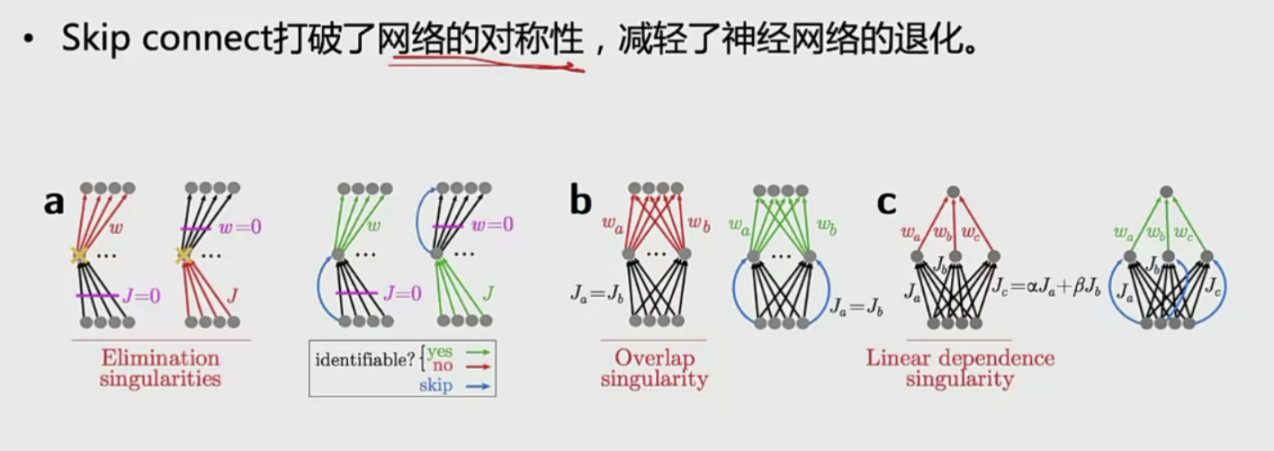
如果网络退化则说明参数的矩阵的秩比较低,矩阵行向量之间的线性相关性比较强
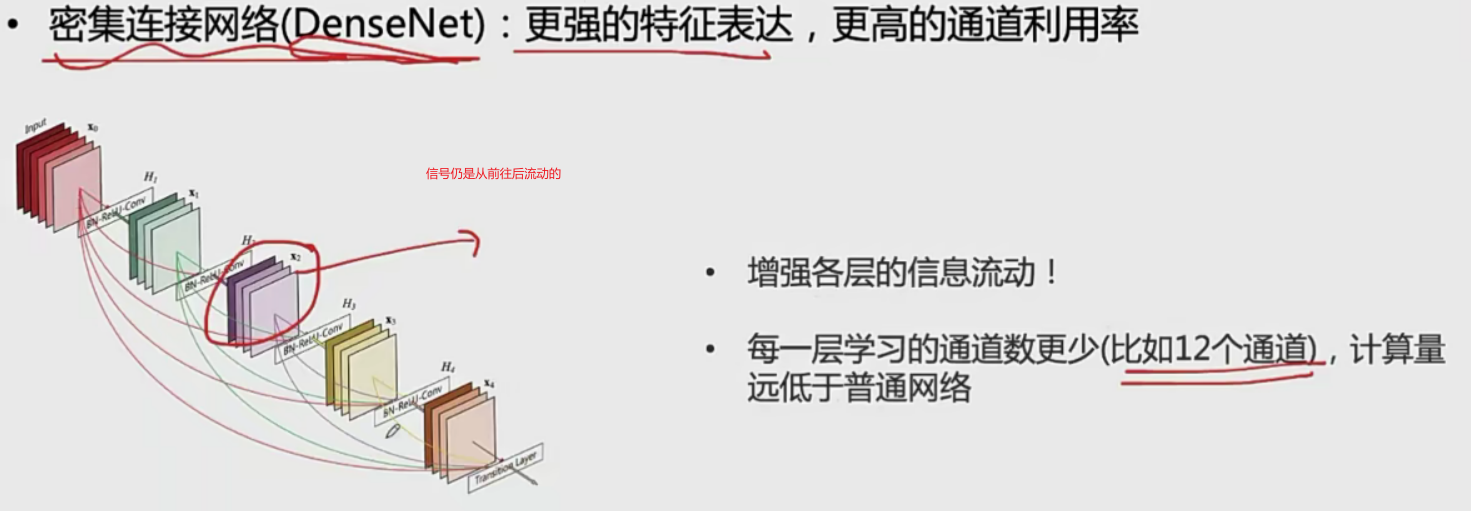
densenet
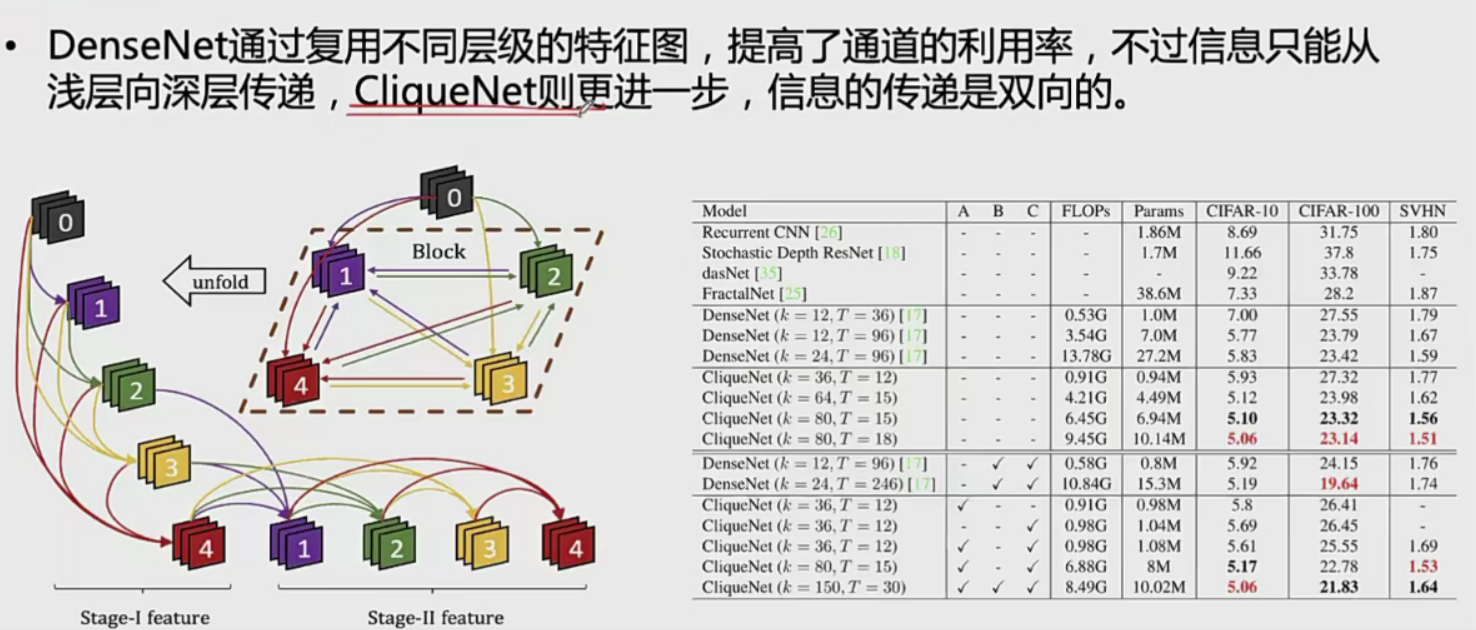
cliqueNet
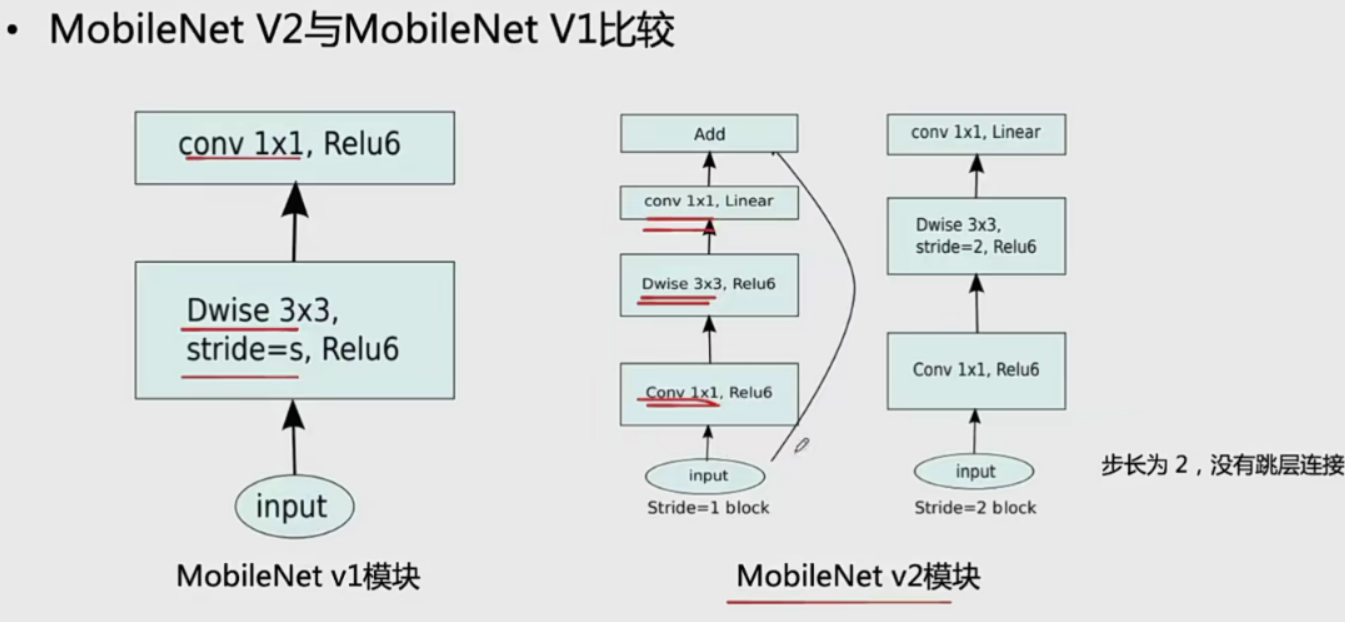
MobileNet
v1存在的问题
RELU信息丢失:小于0d=的信息直接丢失了

V2

反转残差模块
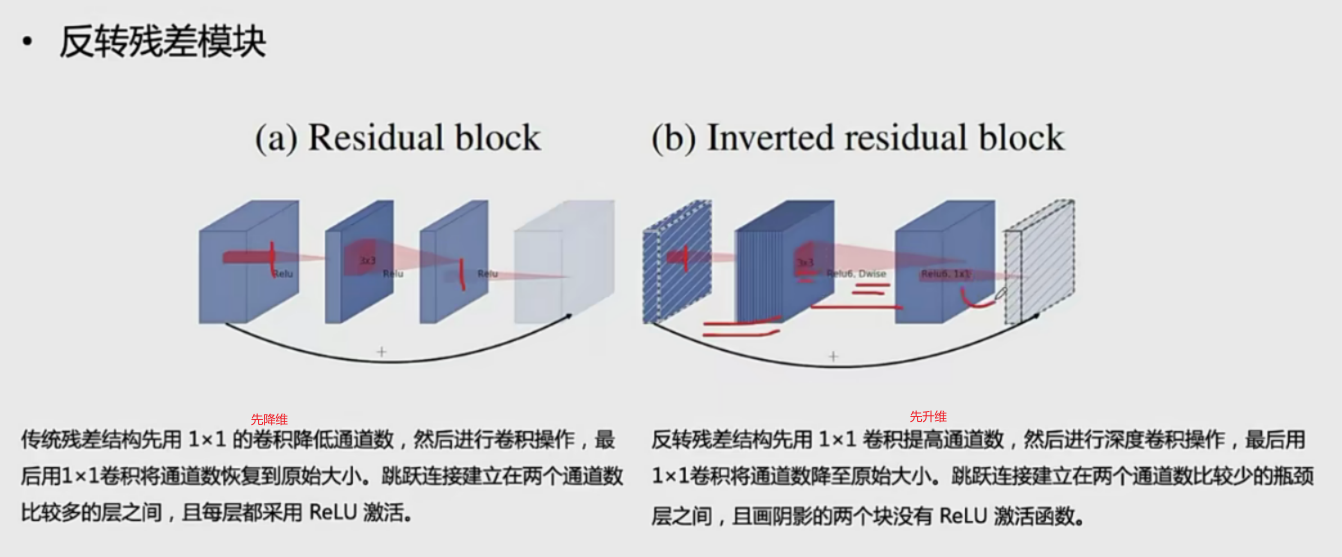
V1 和V2的结构对比