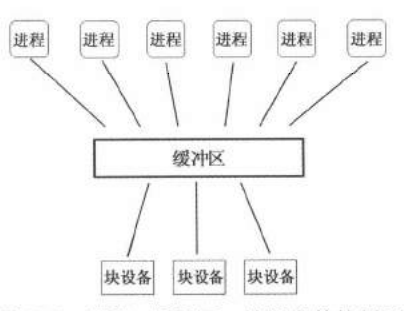
一些操作系统 (e.g.,
Linux)通过在只读的区域共享用户空间和内核态空间的数据加速特定的系统调用。这种方法可以减少系统调用需要不断跨越用户态和内核态的需求T.
To help you learn how to insert mappings into a page table, your first
task is to implement this optimization for the getpid()
system call in xv6.
当每个process被创建的时候, 在USYSCALL (a VA defined in
memlayout.h)映射一个只读page . 在页的开头, store a
struct usyscall (also defined in memlayout.h),
and initialize it to store the PID of the current process.
1 2 3 4 5 6
#define TRAPFRAME (TRAMPOLINE - PGSIZE) #ifdef LAB_PGTBL #define USYSCALL (TRAPFRAME - PGSIZE) structusyscall { int pid; // Process ID };
For this lab, ugetpid() has been provided on the
userspace side and will automatically use the USYSCALL mapping.
// map the trampoline code (for system call return) // at the highest user virtual address. // only the supervisor uses it, on the way // to/from user space, so not PTE_U. if(mappages(pagetable, TRAMPOLINE, PGSIZE, (uint64)trampoline, PTE_R | PTE_X) < 0){ uvmfree(pagetable, 0); return0; }
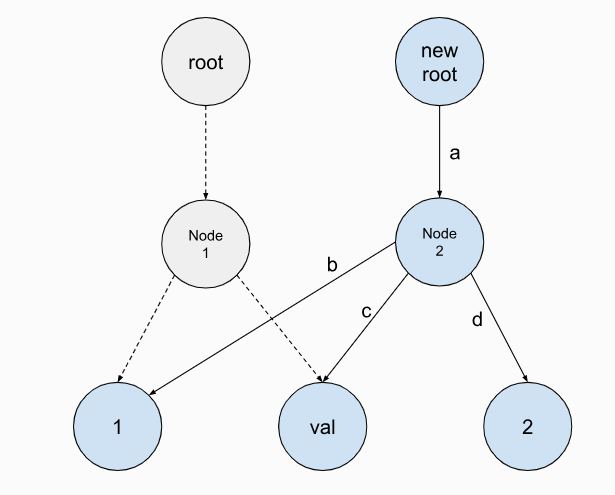
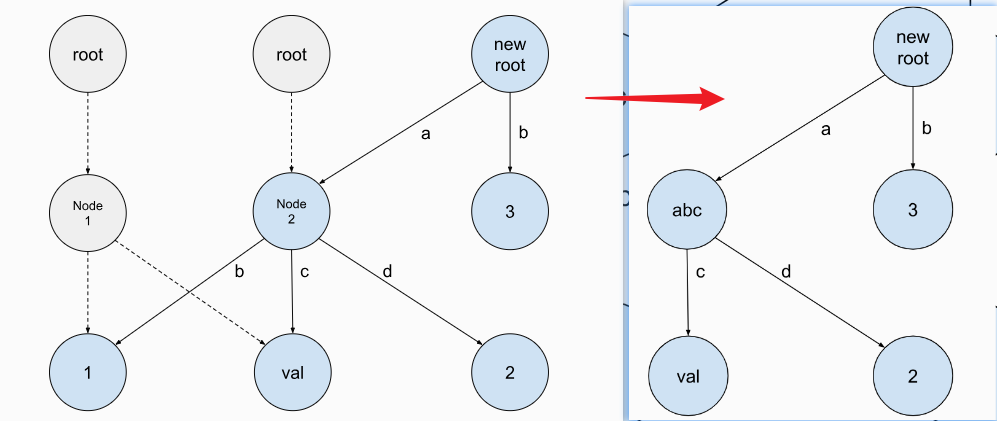
Put(key, value):
设置key对应的value值.如果key值已经存在则覆盖. Note that the type of the
value might be non-copyable (i.e.,
std::unique_ptr<int>). This method returns a new
trie.
在 C++
中,有一些类型是不允许直接进行复制的,而是通过移动或者转移所有权的方式来操作。std::unique_ptr
就是这样的一个例子。它表示一个独占所有权的指针,意味着同一时刻只有一个指针可以拥有它所指向的资源。由于其独占性质,它不允许直接进行复制,而是通过移动(move)操作来传递所有权。
Delete(key): Delete the value for the key. This
method returns a new trie.